Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 9)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись (раздел 3.4) данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (раздел 5.12). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге «/tmp» и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы.
5.4 ЗАХВАТ ФАЙЛА И ЗАПИСИ
В первой версии системы UNIX, разработанной Томпсоном и Ричи, отсутствовал внутренний механизм, с помощью которого процессу мог бы быть обеспечен исключительный доступ к файлу. Механизм захвата был признан излишним, поскольку, как отмечает Ричи, «мы не имеем дела с большими базами данных, состоящими из одного файла, которые поддерживаются независимыми процессами» (см. [Ritchie 81]). Для того, чтобы повысить привлекательность системы UNIX для коммерческих пользователей, работающих с базами данных, в версию V системы ныне включены механизмы захвата файла и записи. Захват файла — это средство, позволяющее запретить другим процессам производить чтение или запись любой части файла, а захват записи — это средство, позволяющее запретить другим процессам производить ввод-вывод указанных записей (частей файла между указанными смещениями). В упражнении 5.9 рассматривается реализация механизма захвата файла и записи.
5.5 УКАЗАНИЕ МЕСТА В ФАЙЛЕ, ГДЕ БУДЕТ ВЫПОЛНЯТЬСЯ ВВОД-ВЫВОД — LSEEК
Обычное использование системных функций read и write обеспечивает последовательный доступ к файлу, однако процессы могут использовать вызов системной функции lseek для указания места в файле, где будет производиться ввод-вывод, и осуществления произвольного доступа к файлу. Синтаксис вызова системной функции:
position = lseek(fd, offset, reference);
где fd — дескриптор файла, идентифицирующий файл, offset — смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи. Например, в программе, приведенной на Рисунке 5.10, процесс открывает файл, считывает байт, а затем вызывает функцию lseek, чтобы заменить значение поля смещения в таблице файлов величиной, равной 1023 (с переменной reference, имеющей значение 1), и выполняет цикл. Таким образом, программа считывает каждый 1024-й байт файла. Если reference имеет значение 0, ядро осуществляет поиск от начала файла, а если 2, ядро ведет поиск от конца файла. Функция lseek ничего не должна делать, кроме операции поиска, которая позиционирует головку чтения-записи на указанный дисковый сектор. Для того, чтобы выполнить функцию lseek, ядро просто выбирает значение смещения из таблицы файлов; в последующих вызовах функций read и write смещение из таблицы файлов используется в качестве начального смещения.
#include ‹fcntl.h›
main(argc, argv)
int argc; char *argv[];
{
int fd, skval;
char c;
if (argc != 2) exit();
fd = open(argv[1], O_RDONLY);
if (fd == -1) exit();
while ((skval = read(fd, &c,1 )) == 1)
{
printf("char %c\n", c);
skval = lseek(fd, 1023L, 1);
printf("new seek val %d\n",
skval);
}
}
Рисунок 5.10. Программа, содержащая вызов системной функции lseek
5.6 CLOSЕ
Процесс закрывает открытый файл, когда процессу больше не нужно обращаться к нему. Синтаксис вызова системной функции close (закрыть):
close(fd);
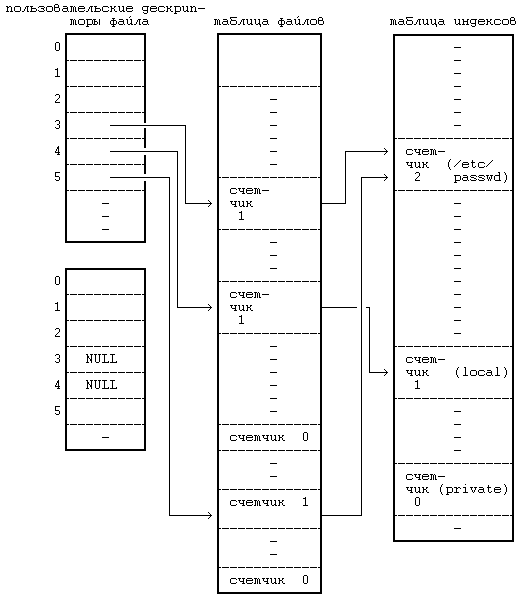
где fd — дескриптор открытого файла. Ядро выполняет операцию закрытия, используя дескриптор файла и информацию из соответствующих записей в таблице файлов и таблице индексов. Если счетчик ссылок в записи таблицы файлов имеет значение, большее, чем 1, в связи с тем, что были обращения к функциям dup или fork, то это означает, что на запись в таблице файлов делают ссылку другие пользовательские дескрипторы, что мы увидим далее; ядро уменьшает значение счетчика и операция закрытия завершается. Если счетчик ссылок в таблице файлов имеет значение, равное 1, ядро освобождает запись в таблице и индекс в памяти, ранее выделенный системной функцией open (алгоритм iput). Если другие процессы все еще ссылаются на индекс, ядро уменьшает значение счетчика ссылок на индекс, но оставляет индекс процессам; в противном случае индекс освобождается для переназначения, так как его счетчик ссылок содержит 0. Когда выполнение системной функции close завершается, запись в таблице пользовательских дескрипторов файла становится пустой. Попытки процесса использовать данный дескриптор заканчиваются ошибкой до тех пор, пока дескриптор не будет переназначен другому файлу в результате выполнения другой системной функции. Когда процесс завершается, ядро проверяет наличие активных пользовательских дескрипторов файла, принадлежавших процессу, и закрывает каждый из них. Таким образом, ни один процесс не может оставить файл открытым после своего завершения. На Рисунке 5.11, например, показаны записи из таблиц, приведенных на Рисунке 5.4, после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы «/etc/passwd» и «private» в индексах также уменьшились. Индекс для файла «private» находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу «private», пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в разделе 4.1.2.
Рисунок 5.11. Таблицы после закрытия файла
5.7 СОЗДАНИЕ ФАЙЛА
Системная функция open дает процессу доступ к существующему файлу, а системная функция creat создает в системе новый файл. Синтаксис вызова системной функции creat:
fd = creat(pathname, modes);
где переменные pathname, modes и fd имеют тот же смысл, что и в системной функции open. Если прежде такого файла не существовало, ядро создает новый файл с указанным именем и указанными правами доступа к нему; если же такой файл уже существовал, ядро усекает файл (освобождает все существующие блоки данных и устанавливает размер файла равным 0) при наличии соответствующих прав доступа к нему
. На Рисунке 5.12 приведен алгоритм создания файла.
алгоритм creat
входная информация:
имя файла
установки прав доступа к файлу
выходная информация: дескриптор файла
{
получить индекс для данного имени файла (алгоритм namei);
if (файл уже существует)
{
if (доступ не разрешен)
{
освободить индекс (алгоритм iput);
return (ошибку);
}
}
else { /* файл еще не существует */
назначить свободный индекс из файловой системы (алгоритм ialloc);
создать новую точку входа в родительском каталоге;
включить имя нового файла и номер вновь назначенного индекса;
}
выделить для индекса запись в таблице файлов, инициализировать счетчик;
if (файл существовал к моменту создания)
освободить все блоки файла (алгоритм free);
снять блокировку (с индекса);
return (пользовательский дескриптор файла);
}
Рисунок 5.12. Алгоритм создания файла
Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге.
Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (раздел 4.6). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. в разделе 5.16.1).
Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать «новый» файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога.
Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.)
5.8 СОЗДАНИЕ СПЕЦИАЛЬНЫХ ФАЙЛОВ
Системная функция mknod создает в системе специальные файлы, в число которых включаются поименованные каналы, файлы устройств и каталоги. Она похожа на функцию creat в том, что ядро выделяет для файла индекс. Синтаксис вызова системной функции mknod:
mknod(pathname, type and permissions, dev)
где pathname — имя создаваемой вершины в иерархической структуре файловой системы, type and permissions — тип вершины (например, каталог) и права доступа к создаваемому файлу, а dev указывает старший и младший номера устройства для блочных и символьных специальных файлов (глава 10). На Рисунке 5.13 приведен алгоритм, реализуемый функцией mknod при создании новой вершины.
алгоритм создания новой вершины
входная информация:
вершина (имя файла)
тип файла
права доступа
старший, младший номера устройства (для блочных и символьных специальных файлов)
выходная информация: отсутствует
{
if (новая вершина не является поименованным каналом и пользователь не является суперпользователем)
return (ошибку);
получить индекс вершины, являющейся родительской для новой вершины (алгоритм namei);
if (новая вершина уже существует)
{
освободить родительский индекс (алгоритм iput);
return (ошибку);
}
назначить для новой вершины свободный индекс из файловой системы (алгоритм ialloc);
создать новую запись в родительском каталоге;
включить имя новой вершины и номер вновь назначенного индекса;
освободить индекс родительского каталога (алгоритм iput);
if (новая вершина является блочным или символьным специальным файлом)
записать старший и младший номера в структуру индекса;
освободить индекс новой вершины (алгоритм iput);
}
Рисунок 5.13. Алгоритм создания новой вершины
Ядро просматривает файловую систему в поисках имени файла, который оно собирается создать. Если файл еще пока не существует, ядро назначает ему новый индекс на диске и записывает имя нового файла и номер индекса в родительский каталог. Оно устанавливает значение поля типа файла в индексе, указывая, что файл является каналом, каталогом или специальным файлом. Наконец, если файл является специальным файлом устройства блочного или символьного типа, ядро записывает в индекс старший и младший номера устройства. Если функция mknod создает каталог, он будет существовать по завершении выполнения функции, но его содержимое будет иметь неверный формат (в каталоге будут отсутствовать записи с именами «.» и «..»). В упражнении 5.33 рассматриваются шаги, необходимые для преобразования содержимого каталога в правильный формат.
5.9 СМЕНА ТЕКУЩЕГО И КОРНЕВОГО КАТАЛОГА
Когда система загружается впервые, нулевой процесс делает корневой каталог файловой системы текущим на время инициализации. Для индекса корневого каталога нулевой процесс выполняет алгоритм iget, сохраняет этот индекс в пространстве процесса в качестве индекса текущего каталога и снимает с индекса блокировку. Когда с помощью функции fork создается новый процесс, он наследует текущий каталог старого процесса в своем адресном пространстве, а ядро, соответственно, увеличивает значение счетчика ссылок в индексе.
алгоритм смены каталога
входная информация: имя нового каталога
выходная информация: отсутствует
{
получить индекс для каталога с новым именем (алгоритм namei);
if (индекс не является индексом каталога или же процессу не разрешен доступ к файлу)
{
освободить индекс (алгоритм iput);
return (ошибку);
}
снять блокировку с индекса;
освободить индекс прежнего текущего каталога (алгоритм iput);
поместить новый индекс в позицию для текущего каталога в пространстве процесса;
}
Рисунок 5.14. Алгоритм смены текущего каталога
Алгоритм chdir (Рисунок 5.14) изменяет имя текущего каталога для процесса. Синтаксис вызова системной функции chdir:
chdir(pathname);
где pathname — каталог, который становится текущим для процесса. Ядро анализирует имя каталога, используя алгоритм namei, и проверяет, является ли данный файл каталогом и имеет ли владелец процесса право доступа к каталога. Ядро снимает с нового индекса блокировку, но удерживает индекс в качестве выделенного и оставляет счетчик ссылок без изменений, освобождает индекс прежнего текущего каталога (алгоритм iput), хранящийся в пространстве процесса, и запоминает в этом пространстве новый индекс. После смены процессом текущего каталога алгоритм namei использует индекс в качестве начального каталога при анализе всех имен путей, которые не берут начало от корня. По окончании выполнения системной функции chdir счетчик ссылок на индекс нового каталога имеет значение, как минимум, 1, а счетчик ссылок на индекс прежнего текущего каталога может стать равным 0. В этом отношении функция chdir похожа на функцию open, поскольку обе функции обращаются к файлу и оставляют его индекс в качестве выделенного. Индекс, выделенный во время выполнения функции chdir, освобождается только тогда, когда процесс меняет текущий каталог еще раз или когда процесс завершается.
Процессы обычно используют глобальный корневой каталог файловой системы для всех имен путей поиска, начинающихся с «/». Ядро хранит глобальную переменную, которая указывает на индекс глобального корня, выделяемый по алгоритму iget при загрузке системы. Процессы могут менять свое представление о корневом каталоге файловой системы с помощью системной функции chroot. Это бывает полезно, если пользователю нужно создать модель обычной иерархической структуры файловой системы и запустить процессы там. Синтаксис вызова функции:
chroot(pathname);
где pathname — каталог, который впоследствии будет рассматриваться ядром в качестве корневого каталога для процесса. Выполняя функцию chroot, ядро следует тому же алгоритму, что и при смене текущего каталога. Оно запоминает индекс нового корня в пространстве процесса, снимая с индекса блокировку по завершении выполнения функции. Тем не менее, так как умолчание на корень для ядра хранится в глобальной переменной, ядро освобождает индекс прежнего корня не автоматически, а только после того, как оно само или процесс-предок исполнят вызов функции chroot. Новый индекс становится логическим корнем файловой системы для процесса (и для всех порожденных им процессов) и это означает, что все пути поиска в алгоритме namei, начинающиеся с корня («/»), возьмут начало с данного индекса и что все попытки войти в каталог «..» над корнем приведут к тому, что рабочим каталогом процесса останется новый корень. Процесс передает всем вновь порождаемым процессам этот каталог в качестве корневого подобно тому, как передает свой текущий каталог.
5.10 CМЕНА ВЛАДЕЛЬЦА И РЕЖИМА ДОСТУПА К ФАЙЛУ
Смена владельца или режима (прав) доступа к файлу является операцией, производимой над индексом, а не над файлом. Синтаксис вызова соответствующих системных функций:
chown(pathname, owner, group)
chmod(pathname, mode)
Для того, чтобы поменять владельца файла, ядро преобразует имя файла в идентификатор индекса, используя алгоритм namei. Владелец процесса должен быть суперпользователем или владельцем файла (процесс не может распоряжаться тем, что не принадлежит ему). Затем ядро назначает файлу нового владельца и нового группового пользователя, сбрасывает флаги прежних установок (см. раздел 7.5) и освобождает индекс по алгоритму iput. После этого прежний владелец теряет право «собственности» на файл. Для того, чтобы поменять режим доступа к файлу, ядро выполняет процедуру, подобную описанной, вместо кода владельца меняя флаги, устанавливающие режим доступа.
5.11 STAT И FSTАТ
Системные функции stat и fstat позволяют процессам запрашивать информацию о статусе файла: типе файла, владельце файла, правах доступа, размере файла, числе связей, номере индекса и времени доступа к файлу. Синтаксис вызова функций:
stat(pathname, statbuffer); fstat(fd, statbuffer);
где pathname — имя файла, fd — дескриптор файла, возвращаемый функцией open, statbuffer — адрес структуры данных пользовательского процесса, где будет храниться информация о статусе файла после завершения выполнения вызова. Системные функции просто переписывают поля из индекса в структуру statbuffer. Программа на Рисунке 5.33 иллюстрирует использование функций stat и fstat.
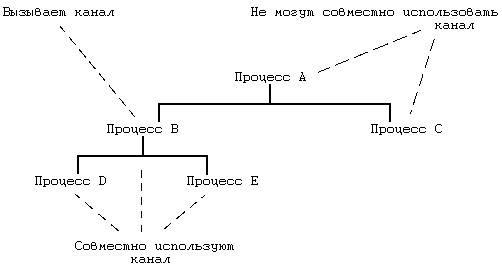
Рисунок 5.15. Дерево процессов и совместное использование каналов
5.12 КАНАЛЫ
Каналы позволяют передавать данные между процессами в порядке поступления («первым пришел — первым вышел»), а также синхронизировать выполнение процессов. Их использование дает процессам возможность взаимодействовать между собой, пусть даже не известно, какие процессы находятся на другом конце канала. Традиционная реализация каналов использует файловую систему для хранения данных. Различают два вида каналов: поименованные каналы и, за отсутствием лучшего термина, непоименованные каналы, которые идентичны между собой во всем, кроме способа первоначального обращения к ним процессов. Для поименованных каналов процессы используют системную функцию open, а системную функцию pipe — для создания непоименованного канала. Впоследствии, при работе с каналами процессы пользуются обычными системными функциями для файлов, такими как read, write и close. Только связанные между собой процессы, являющиеся потомками того процесса, который вызвал функцию pipe, могут разделять доступ к непоименованным каналам. Например (см. Рисунок 5.15), если процесс B создает канал и порождает процессы D и E, эти три процесса разделяют между собой доступ к каналу, в отличие от процессов A и C. Однако, все процессы могут обращаться к поименованному каналу независимо от взаимоотношений между ними, при условии наличия обычных прав доступа к файлу. Поскольку непоименованные каналы встречаются чаще, они будут рассмотрены первыми.
5.12.1 Системная функция pipе
Синтаксис вызова функции создания канала:
pipe(fdptr);
где fdptr — указатель на массив из двух целых переменных, в котором будут храниться два дескриптора файла для чтения из канала и для записи в канал. Поскольку ядро реализует каналы внутри файловой системы и поскольку канал не существует до того, как его будут использовать, ядро должно при создании канала назначить ему индекс. Оно также назначает для канала пару пользовательских дескрипторов и соответствующие им записи в таблице файлов: один из дескрипторов для чтения из канала, а другой для записи в канал. Поскольку ядро пользуется таблицей файлов, интерфейс для вызова функций read, write и др. согласуется с интерфейсом для обычных файлов. В результате процессам нет надобности знать, ведут ли они чтение или запись в обычный файл или в канал.
алгоритм pipe
входная информация: отсутствует
выходная информация:
дескриптор файла для чтения
дескриптор файла для записи
{
назначить новый индекс из устройства канала (алгоритм ialloc);
выделить одну запись в таблице файлов для чтения, одну — для переписи;
инициализировать записи в таблице файлов таким образом, чтобы они указывали на новый индекс;
выделить один пользовательский дескриптор файла для чтения, один — для записи, проинициализировать их таким образом, чтобы они указывали на соответствующие точки входа в таблице файлов;
установить значение счетчика ссылок в индексе равным 2;
установить значение счетчика числа процессов, производящих чтение, и процессов, производящих запись, равным 1;
}
Рисунок 5.16. Алгоритм создания каналов (непоименованных)
На Рисунке 5.16 показан алгоритм создания непоименованных каналов. Ядро назначает индекс для канала из файловой системы, обозначенной как «устройство канала», используя алгоритм ialloc. Устройство канала — это именно та файловая система, из которой ядро может назначать каналам индексы и выделять блоки для данных. Администраторы системы указывают устройство канала при конфигурировании системы и эти устройства могут совпадать у разных файловых систем. Пока канал активен, ядро не может переназначить индекс канала и информационные блоки канала другому файлу.
Затем ядро выделяет в таблице файлов две записи, соответствующие дескрипторам для чтения и записи в канал, и корректирует «бухгалтерскую» информацию в копии индекса в памяти. В каждой из выделенных записей в таблице файлов хранится информация о том, сколько экземпляров канала открыто для чтения или записи (первоначально 1), а счетчик ссылок в индексе указывает, сколько раз канал был «открыт» (первоначально 2 — по одному для каждой записи таблицы файлов). Наконец, в индексе записываются смещения в байтах внутри канала до места, где будет начинаться следующая операция записи или чтения. Благодаря сохранению этих смещений в индексе имеется возможность производить доступ к данным в канале в порядке их поступления в канал («первым пришел первым вышел»); этот момент является особенностью каналов, поскольку для обычных файлов смещения хранятся в таблице файлов. Процессы не могут менять эти смещения с помощью системной функции lseek и поэтому произвольный доступ к данным канала невозможен.
5.12.2 Открытие поименованного канала
Поименованный канал — это файл, имеющий почти такую же семантику, как и непоименованный канал, за исключением того, что этому файлу соответствует запись в каталоге и обращение к нему производится по имени. Процессы открывают поименованные каналы так же, как и обычные файлы, и, следовательно, с помощью поименованных каналов могут взаимодействовать между собой даже процессы, не имеющие друг к другу близкого отношения. Поименованные каналы постоянно присутствуют в иерархии файловой системы (из которой они удаляются с помощью системной функции unlink), а непоименованные каналы являются временными: когда все процессы заканчивают работу с каналом, ядро отбирает назад его индекс.
Алгоритм открытия поименованного канала идентичен алгоритму открытия обычного файла. Однако, перед выходом из функции ядро увеличивает значения тех счетчиков в индексе, которые показывают количество процессов, открывших поименованный канал для чтения или записи. Процесс, открывающий поименованный канал для чтения, приостановит свое выполнение до тех пор, пока другой процесс не откроет поименованный канал для записи, и наоборот. Не имеет смысла открывать канал для чтения, если процесс не надеется получить данные; то же самое касается записи. В зависимости от того, открывает ли процесс поименованный канал для записи или для чтения, ядро возобновляет выполнение тех процессов, которые были приостановлены в ожидании процесса, записывающего в поименованный канал или считывающего данные из канала (соответственно).
Если процесс открывает поименованный канал для чтения, причем процесс, записывающий в канал, существует, открытие завершается. Или если процесс открывает поименованный файл с параметром «no delay», функция open возвращает управление немедленно, даже когда нет ни одного записывающего процесса. Во всех остальных случаях процесс приостанавливается до тех пор, пока записывающий процесс не откроет канал. Аналогичные правила действуют для процесса, открывающего канал для записи.
5.12.3 Чтение из каналов и запись в каналы
Канал следует рассматривать под таким углом зрения, что процессы ведут запись на одном конце канала, а считывают данные на другом конце. Как уже говорилось выше, процессы обращаются к данным в канале в порядке их поступления в канал; это означает, что очередность, в которой данные записываются в канал, совпадает с очередностью их выборки из канала. Совпадение количества процессов, считывающих данные из канала, с количеством процессов, ведущих запись в канал, совсем не обязательно; если одно число отличается от другого более, чем на 1, процессы должны координировать свои действия по использованию канала с помощью других механизмов. Ядро обращается к данным в канале точно так же, как и к данным в обычном файле: оно сохраняет данные на устройстве канала и назначает каналу столько блоков, сколько нужно, во время выполнения функции write. Различие в выделении памяти для канала и для обычного файла состоит в том, что канал использует в индексе только блоки прямой адресации в целях повышения эффективности работы, хотя это и накладывает определенные ограничения на объем данных, одновременно помещающихся в канале. Ядро работает с блоками прямой адресации индекса как с циклической очередью, поддерживая в своей структуре указатели чтения и записи для обеспечения очередности обслуживания "первым пришел - первым вышел" (Рисунок 5.17). Рассмотрим четыре примера ввода-вывода в канал: запись в канал, в котором есть место для записи данных; чтение из канала, в котором достаточно данных для удовлетворения запроса на чтение; чтение из канала, в котором данных недостаточно; и запись в канал, где нет места для записи.
Рисунок 5.17. Логическая схема чтения и записи в канал Рассмотрим первый случай, в котором процесс ведет запись в канал, имеющий место для ввода данных: сумма количества записываемых байт с числом байт, уже находящихся в канале, меньше или равна емкости канала. Ядро следует алгоритму записи данных в обычный файл, за исключением того, что оно увеличивает размер канала автоматически после каждого выполнения функции write, поскольку по определению объем данных в канале растет с каждой операцией записи. Иначе происходит увеличение размера обычного файла: процесс увеличивает размер файла только тогда, когда он при записи данных переступает границу конца файла.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|