Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 32)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
Функции send и recv выполняют передачу данных через подключенное гнездо. Синтаксис вызова функции send:
count = send(sd, msg, length, flags);
где sd — дескриптор гнезда, msg — указатель на посылаемые данные, length размер данных, count — количество фактически переданных байт. Параметр flags может содержать значение SOF_OOB (послать данные out-of-band — "через таможню"), если посылаемые данные не учитываются в общем информационном обмене между взаимодействующими процессами. Программа удаленной регистрации, например, может послать out-of-band сообщение, имитирующее нажатие на клавиатуре терминала клавиши "delete". Синтаксис вызова системной функции recv:
count = recv(sd, buf, length, flags);
где buf — массив для приема данных, length — ожидаемый объем данных, count количество байт, фактически переданных пользовательской программе. Флаги (flags) могут быть установлены таким образом, что поступившее сообщение после чтения и анализа его содержимого не будет удалено из очереди, или настроены на получение данных out-of-band. В дейтаграммных версиях указанных функций, sendto и recvfrom, в качестве дополнительных параметров указываются адреса. После выполнения подключения к гнездам потокового типа процессы могут вместо функций send и recv использовать функции read и write. Таким образом, согласовав тип протокола, серверы могли бы порождать процессы, работающие только с функциями read и write, словно имеют дело с обычными файлами. Функция shutdown закрывает гнездовую связь:
shutdown(sd, mode)
где mode указывает, какой из сторон (посылающей, принимающей или обеим вместе) отныне запрещено участие в процессе передачи данных. Функция сообщает используемому протоколу о завершении сеанса сетевого взаимодействия, оставляя, тем не менее, дескрипторы гнезд в неприкосновенности. Освобождается дескриптор гнезда только в результате выполнения функции close. Системная функция getsockname получает имя гнездовой связи, установленной ранее с помощью функции bind:
getsockname(sd, name, length);
Функции getsockopt и setsockopt получают и устанавливают значения различных связанных с гнездом параметров в соответствии с типом домена и протокола. Рассмотрим обслуживающую программу, представленную на Рисунке 11.20. Процесс создает в домене "UNIX system" гнездо потокового типа и присваивает ему имя sockname. Затем с помощью функции listen устанавливается длина очереди поступающих сообщений и начинается цикл ожидания поступления запросов. Функция accept приостанавливает свое выполнение до тех пор, пока протоколом не будет зарегистрирован запрос на подключение к гнезду с означенным именем; после этого функция завершается, возвращая поступившему запросу новый дескриптор гнезда. Процесс-сервер порождает потомка, через которого будет поддерживаться связь с процессом-клиентом; родитель и потомок при этом закрывают свои дескрипторы, чтобы они не становились помехой для коммуникационного траффика другого процесса. Процесс-потомок ведет разговор с клиентом и завершается после выхода из функции read. Процесс-сервер возвращается к началу цикла и ждет поступления следующего запроса на подключение.
#include ‹sys/types.h›
#include ‹sys/socket.h›
main() {
int sd, ns;
char buf[256];
struct sockaddr sockaddr;
int fromlen;
sd = socket(AF_UNIX, SOCK_STREAM, 0);
/* имя гнезда — не может включать пустой символ */
bind(sd, "sockname", sizeof("sockname") - 1);
listen(sd, 1);
for (;;) {
ns = accept(sd, &sockaddr, &fromlen);
if (fork() == 0) { /* потомок */
close(sd);
read(ns, buf, sizeof(buf));
printf("сервер читает %s'\n",buf);
exit();
}
close(ns);
}
}
Рисунок 11.20. Процесс-сервер в домене "UNIX system"
#include ‹sys/types.h›
#include ‹sys/socket.h›
main() {
int sd, ns;
char buf[256];
struct sockaddr sockaddr;
int fromlen;
sd = socket(AF_UNIX, SOCK_STREAM, 0);
/* имя в запросе на подключение не может включать пустой символ */
if (connect(sd, "sockname", sizeof("sockname") - 1) == -1) exit();
write(sd, "hi guy", 6);}
Рисунок 11.21. Процесс-клиент в домене "UNIX system"
На Рисунке 11.21 показан пример процесса-клиента, ведущего общение с сервером. Клиент создает гнездо в том же домене, что и сервер, и посылает запрос на подключение к гнезду с именем sockname. В результате подключения процесс-клиент получает виртуальный канал связи с сервером. В рассматриваемом примере клиент передает одно сообщение и завершается. Если сервер обслуживает процессы в сети, указание о том, что гнездо принадлежит домену "Internet", можно сделать следующим образом:
socket(AF_INET, SOCK_STREAM, 0);
и связаться с сетевым адресом, полученным от сервера. В системе BSD имеются библиотечные функции, выполняющие эти действия. Второй параметр вызываемой клиентом функции connect содержит адресную информацию, необходимую для идентификации машины в сети (или адреса маршрутов посылки сообщений через промежуточные машины), а также дополнительную информацию, идентифицирующую приемное гнездо машины-адресата. Если серверу нужно одновременно следить за состоянием сети и выполнением локальных процессов, он использует два гнезда и с помощью функции select определяет, с каким клиентом устанавливается связь в данный момент.
11.5 ВЫВОДЫ
Мы рассмотрели несколько форм взаимодействия процессов. Первой формой, положившей начало обсуждению, явилась трассировка процессов — взаимодействие двух процессов, выступающее в качестве полезного средства отладки программ. При всех своих преимуществах трассировка процессов с помощью функции ptrace все же достаточно дорогостоящее и примитивное мероприятие, поскольку за один сеанс функция способна передать строго ограниченный объем данных, требуется большое количество переключений контекста, взаимодействие ограничивается только формой отношений родитель-потомок, и наконец, сама трассировка производится только по обоюдному согласию участвующих в ней процессов. В версии V системы UNIX имеется пакет взаимодействия процессов (IPC), включающий в себя механизмы обмена сообщениями, работы с семафорами и разделения памяти. К сожалению, все эти механизмы имеют узкоспециальное назначение, не имеют хорошей стыковки с другими элементами операционной системы и не действуют в сети. Тем не менее, они используются во многих приложениях и по сравнению с другими схемами отличаются более высокой эффективностью.
Система UNIX поддерживает широкий спектр вычислительных сетей. Традиционные методы согласования протоколов в сильной степени полагаются на помощь системной функции ioctl, однако в разных типах сетей они реализуются по-разному. В системе BSD имеются системные функции для работы с гнездами, поддерживающие более универсальную структуру сетевого взаимодействия. В будущем в версию V предполагается включить описанный в главе 10 потоковый механизм, повышающий согласованность работы в сети.
11.6 УПРАЖНЕНИЯ
1. Что произойдет в том случае, если в программе debug будет отсутствовать вызов функции wait (Рисунок 11.3)? (Намек: возможны два исхода.)
2. С помощью функции ptrace отладчик считывает данные из пространства трассируемого процесса по одному слову за одну операцию. Какие изменения следует произвести в ядре операционной системы для того, чтобы увеличить количество считываемых слов? Какие изменения при этом необходимо сделать в самой функции ptrace?
3. Расширьте область действия функции ptrace так, чтобы в качестве параметра pid можно было указывать идентификатор процесса, не являющегося потомком текущего процесса. Подумайте над вопросами, связанными с защитой информации: При каких обстоятельствах процессу может быть позволено читать данные из адресного пространства другого, произвольного процесса? При каких обстоятельствах разрешается вести запись в адресное пространство другого процесса?
4. Организуйте из функций работы с сообщениями библиотеку пользовательского уровня с использованием обычных файлов, поименованных каналов и элементов блокировки. Создавая очередь сообщений, откройте управляющий файл для записи в него информации о состоянии очереди; защитите файл с помощью средств захвата файлов и других удобных для вас механизмов. Посылая сообщение данного типа, создавайте поименованный канал для всех сообщений этого типа, если такого канала еще не было, и передавайте сообщение через него (с подсчетом переданных байт). Управляющий файл должен соотносить тип сообщения с именем поименованного канала. При чтении сообщений управляющий файл направляет процесс к соответствующему поименованному каналу. Сравните эту схему с механизмом, описанным в настоящей главе, по эффективности, сложности реализации и функциональным возможностям.
5. Какие действия пытается выполнить программа, представленная на Рисунке 11.22?
*6. Напишите программу, которая подключала бы область разделяемой памяти слишком близко к вершине стека задачи и позволяла бы стеку при увеличении пересекать границу разделяемой области. В какой момент произойдет фатальная ошибка памяти?
7. Используйте в программе, представленной на Рисунке 11.14, флаг IPC_NOWAIT, реализуя условный тип семафора. Продемонстрируйте, как за счет этого можно избежать возникновения взаимных блокировок.
8. Покажите, как операции над семафорами типа P и V реализуются при работе с поименованными каналами. Как бы вы реализовали операцию P условного типа?
9. Составьте программы захвата ресурсов, использующие (а) поименованные каналы, (б) системные функции creat и unlink, (в) функции обмена сообщениями. Проведите сравнительный анализ их эффективности.
10. На практических примерах работы с поименованными каналами сравните эффективность использования функций обмена сообщениями, с одной стороны, с функциями read и write, с другой.
11. Сравните на конкретных программах скорость передачи данных при работе с разделяемой памятью и при использовании механизма обмена сообщениями. Программы, использующие разделяемую память, для синхронизации завершения операций чтения-записи должны опираться на семафоры.
#include ‹sys/types.h›
#include ‹sys/ipc.h›
#include ‹sys/msg.h›
#define ALLTYPES 0
main() {
struct msgform {
long mtype;
char mtext[1024];
} msg;
register unsigned int id;
for (id = 0; ; id++) while (msgrcv(id, &msg, 1024, ALLTYPES, IPC_NOWAIT) › 0);
}
Рисунок 11.22
ГЛАВА 12. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
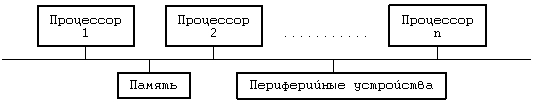
В классической постановке для системы UNIX предполагается использование однопроцессорной архитектуры, состоящей из одного ЦП, памяти и периферийных устройств. Многопроцессорная архитектура, напротив, включает в себя два и более ЦП, совместно использующих общую память и периферийные устройства (Рисунок 12.1), располагая большими возможностями в увеличении производительности системы, связанными с одновременным исполнением процессов на разных ЦП. Каждый ЦП функционирует независимо от других, но все они работают с одним и тем же ядром операционной системы. Поведение процессов в такой системе ничем не отличается от поведения в однопроцессорной системе — с сохранением семантики обращения к каждой системной функции — но при этом они могут открыто перемещаться с одного процессора на другой. Хотя, к сожалению, это не приводит к снижению затрат процессорного времени, связанного с выполнением процесса. Отдельные многопроцессорные системы называются системами с присоединенными процессорами, поскольку в них периферийные устройства доступны не для всех процессоров. За исключением особо оговоренных случаев, в настоящей главе не проводится никаких различий между системами с присоединенными процессорами и остальными классами многопроцессорных систем. Параллельная работа нескольких процессоров в режиме ядра по выполнению различных процессов создает ряд проблем, связанных с сохранением целостности данных и решаемых благодаря использованию соответствующих механизмов защиты. Ниже будет показано, почему классический вариант системы UNIX не может быть принят в многопроцессорных системах без внесения необходимых изменений, а также будут рассмотрены два варианта, предназначенные для работы в указанной среде.
Рисунок 12.1. Многопроцессорная конфигурация
12.1 ПРОБЛЕМЫ, СВЯЗАННЫЕ С МНОГОПРОЦЕССОРНЫМИ СИСТЕМАМИ
В главе 2 мы говорили о том, что защита целостности структур данных ядра системы UNIX обеспечивается двумя способами: ядро не может выгрузить один процесс и переключиться на контекст другого, если работа производится в режиме ядра, кроме того, если при выполнении критического участка программы обработчик возникающих прерываний может повредить структуры данных ядра, все возникающие прерывания тщательно маскируются. В многопроцессорной системе, однако, если два и более процессов выполняются одновременно в режиме ядра на разных процессорах, нарушение целостности ядра может произойти даже несмотря на принятие защитных мер, с другой стороны, в однопроцессорной системе вполне достаточных.
struct queue {} *bp, *bp1;
bp1-›forp = bp-›forp;
bp1-›backp = bp;
bp-›forp=bp1;
/* рассмотрите возможность переключения контекста в этом месте */
bp1-›forp-›backp =b p1;
Рисунок 12.2. Включение буфера в список с двойными указателями
В качестве примера рассмотрим фрагмент программы из главы 2 (Рисунок 12.2), в котором новая структура данных (указатель bp1) помещается в список после существующей структуры (указатель bp). Предположим, что этот фрагмент выполняется одновременно двумя процессами на разных ЦП, причем процессор A пытается поместить вслед за структурой bp структуру bpA, а процессор B структуру bpB. По поводу сопоставления быстродействия процессоров не приходится делать никаких предположений: возможен даже наихудший случай, когда процессор B исполняет 4 команды языка Си, прежде чем процессор A исполнит одну. Пусть, например, выполнение программы процессором A приостанавливается в связи с обработкой прерывания. В результате, даже несмотря на блокировку остальных прерываний, целостность данных будет поставлена под угрозу (в главе 2 этот момент уже пояснялся).
Ядро обязано удостовериться в том, что такого рода нарушение не сможет произойти. Если вопрос об опасности возникновения нарушения целостности оставить открытым, как бы редко подобные нарушения ни случались, ядро утратит свою неуязвимость и его поведение станет непредсказуемым. Избежать этого можно тремя способами:
1. Исполнять все критические операции на одном процессоре, опираясь на стандартные методы сохранения целостности данных в однопроцессорной системе;
2. Регламентировать доступ к критическим участкам программы, используя элементы блокирования ресурсов;
3. Устранить конкуренцию за использование структур данных путем соответствующей переделки алгоритмов.
Первые два способа здесь мы рассмотрим подробнее, третьему способу будет посвящено отдельное упражнение.
12.2 ГЛАВНЫЙ И ПОДЧИНЕННЫЙ ПРОЦЕССОРЫ
Систему с двумя процессорами, один из которых — главный (master) — может работать в режиме ядра, а другой — подчиненный (slave) — только в режиме задачи, впервые реализовал на машинах типа VAX 11/780 Гобл (см. [Goble 81]). Эта система, реализованная вначале на двух машинах, получила свое дальнейшее развитие в системах с одним главным и несколькими подчиненными процессорами. Главный процессор несет ответственность за обработку всех обращений к операционной системе и всех прерываний. Подчиненные процессоры ведают выполнением процессов в режиме задачи и информируют главный процессор о всех производимых обращениях к системным функциям.
Выбор процессора, на котором будет выполняться данный процесс, производится в соответствии с алгоритмом диспетчеризации (Рисунок 12.3). В соответствующей записи таблицы процессов появляется новое поле, в которое записывается идентификатор выбранного процессора; предположим для простоты, что он показывает, является ли процессор главным или подчиненным. Когда процесс производит обращение к системной функции, выполняясь на подчиненном процессоре, подчиненное ядро переустанавливает значение поля идентификации процессора таким образом, чтобы оно указывало на главный процессор, и переключает контекст на другие процессы (Рисунок 12.4). Главное ядро запускает на выполнение процесс с наивысшим приоритетом среди тех процессов, которые должны выполняться на главном процессоре. Когда выполнение системной функции завершается, поле идентификации процессора перенастраивается обратно, и процесс вновь возвращается на подчиненный процессор.
Если процессы должны выполняться на главном процессоре, желательно, чтобы главный процессор обрабатывал их как можно скорее и не заставлял их ждать своей очереди чересчур долго. Похожая мотивировка приводится в объяснение выгрузки процесса из памяти в однопроцессорной системе после выхода из системной функции с освобождением соответствующих ресурсов для выполнения более насущных счетных операций. Если в тот момент, когда подчиненный процессор делает запрос на исполнение системной функции, главный процесс выполняется в режиме задачи, его выполнение будет продолжаться до следующего переключения контекста. Главный процессор реагировал бы гораздо быстрее, если бы подчиненный процессор устанавливал при этом глобальный флаг; проверяя установку флага во время обработки очередного прерывания по таймеру, главный процессор произвел бы в итоге переключение контекста максимум через один таймерный тик. С другой стороны, подчиненный процессор мог бы прервать работу главного и заставить его переключить контекст немедленно, но данная возможность требует специальной аппаратной реализации.
алгоритм schedule_process (модифицированный)
входная информация: отсутствует
выходная информация: отсутствует
{
do while (для запуска не будет выбран один из процессов)
{
if (работа ведется на главном процессоре)
for (всех процессов в очереди готовых к выполнению)
выбрать процесс, имеющий наивысший приоритет среди загруженных в память;
else /* работа ведется на подчиненном процессоре */
for (тех процессов в очереди, которые не нуждаются в главном процессоре)
выбрать процесс, имеющий наивысший приоритет среди загруженных в память;
if (для запуска не подходит ни один из процессов)
не загружать машину, переходящую в состояние простоя; /* из этого состояния машина выходит в результате прерывания */
}
убрать выбранный процесс из очереди готовых к выполнению;
переключиться на контекст выбранного процесса, возобновить его выполнение;
}
Рисунок 12.3. Алгоритм диспетчеризации
алгоритм syscall /* исправленный алгоритм вызова системной функции */
входная информация: код системной функции
выходная информация: результат выполнения системной функции
{
if (работа ведется на подчиненном процессоре)
{
переустановить значение поля идентификации процессора в соответствующей записи таблицы процессов;
произвести переключение контекста;
}
выполнить обычный алгоритм реализации системной функции;
перенастроить значение поля идентификации процессора, чтобы оно указывало на "любой" (подчиненный);
if (на главном процессоре должны выполняться другие процессы)
произвести переключение контекста;
}
Рисунок 12.4. Алгоритм обработки обращения к системной функции
Программа обработки прерываний по таймеру на подчиненном процессоре следит за периодичностью перезапуска процессов, не допуская монопольного использования процессора одной задачей. Кроме того, каждую секунду эта программа выводит подчиненный процессор из состояния бездействия (простоя). Подчиненный процессор выбирает для выполнения процесс с наивысшим приоритетом среди тех процессов, которые не нуждаются в главном процессоре.
Единственным местом, где целостность структур данных ядра еще подвергается опасности, является алгоритм диспетчеризации, поскольку он не предохраняет от выбора процесса на выполнение сразу на двух процессорах. Например, если в конфигурации имеется один главный процессор и два подчиненных, не исключена возможность того, что оба подчиненных процессора выберут для выполнения в режиме задачи один и тот же процесс. Если оба процессора начнут выполнять его параллельно, осуществляя чтение и запись, это неизбежно приведет к искажению содержимого адресного пространства процесса.
Избежать возникновения этой проблемы можно двумя способами. Во-первых, главный процессор может явно указать, на каком из подчиненных процессоров следует выполнять данный процесс. Если на каждый процессор направлять несколько процессов, возникает необходимость в сбалансировании нагрузки (на один из процессоров назначается большое количество процессов, в то время как другие процессоры простаивают). Задача распределения нагрузки между процессорами ложится на главное ядро. Во-вторых, ядро может проследить за тем, чтобы в каждый момент времени в алгоритме диспетчеризации принимал участие только один процессор, для этого используются механизмы, подобные семафорам.
12.3 СЕМАФОРЫ
Поддержка системы UNIX в многопроцессорной конфигурации может включать в себя разбиение ядра системы на критические участки, параллельное выполнение которых на нескольких процессорах не допускается. Такие системы предназначались для работы на машинах AT amp;T 3B20A и IBM 370, для разбиения ядра использовались семафоры (см. [Bach 84]). Нижеследующие рассуждения помогают понять суть данной особенности. При ближайшем рассмотрении сразу же возникают два вопроса: как использовать семафоры и где определить критические участки. Как уже говорилось в главе 2, если при выполнении критического участка программы процесс приостанавливается, для защиты участка от посягательств со стороны других процессов алгоритмы работы ядра однопроцессорной системы UNIX используют блокировку. Механизм установления блокировки:
выполнять пока (блокировка установлена) /* операция проверки */
приостановиться (до снятия блокировки);
установить блокировку;
механизм снятия блокировки:
снять блокировку;
вывести из состояния приостанова все процессы, приостановленные в результате блокировки;
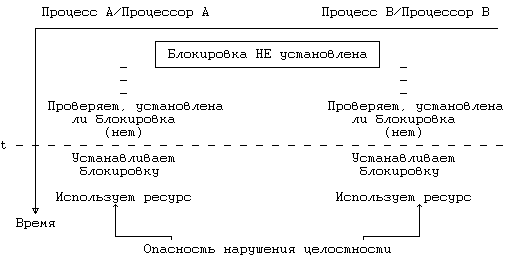
Рисунок 12.5. Конкуренция за установку блокировки в многопроцессорных системах
Блокировки такого рода охватывают некоторые критические участки, но не работают в многопроцессорных системах, что видно из Рисунка 12.5. Предположим, что блокировка снята и что два процесса на разных процессорах одновременно пытаются проверить ее наличие и установить ее. В момент t они обнаруживают снятие блокировки, устанавливают ее вновь, вступают в критический участок и создают опасность нарушения целостности структур данных ядра. В условии одновременности имеется отклонение: механизм не сработает, если перед тем, как процесс выполняет операцию проверки, ни один другой процесс не выполнил операцию установления блокировки. Если, например, после обнаружения снятия блокировки процессор A обрабатывает прерывание и в этот момент процессор B выполняет проверку и устанавливает блокировку, по выходе из прерывания процессор A так же установит блокировку. Чтобы предотвратить возникновение подобной ситуации, нужно сделать так, чтобы процедура блокирования была неделимой: проверку наличия блокировки и ее установку следует объединить в одну операцию, чтобы в каждый момент времени с блокировкой имел дело только один процесс.
12.3.1 Определение семафоров
Семафор представляет собой обрабатываемый ядром целочисленный объект, для которого определены следующие элементарные (неделимые) операции:
• Инициализация семафора, в результате которой семафору присваивается неотрицательное значение;
• Операция типа P, уменьшающая значение семафора. Если значение семафора опускается ниже нулевой отметки, выполняющий операцию процесс приостанавливает свою работу;
• Операция типа V, увеличивающая значение семафора. Если значение семафора в результате операции становится больше или равно 0, один из процессов, приостановленных во время выполнения операции P, выходит из состояния приостанова;
• Условная операция типа P, сокращенно CP (conditional P), уменьшающая значение семафора и возвращающая логическое значение "истина" в том случае, когда значение семафора остается положительным. Если в результате операции значение семафора должно стать отрицательным или нулевым, никаких действий над ним не производится и операция возвращает логическое значение "ложь".
Определенные таким образом семафоры, безусловно, никак не связаны с семафорами пользовательского уровня, рассмотренными в главе 11.
12.3.2 Реализация семафоров
Дийкстра [Dijkstra 65] показал, что семафоры можно реализовать без использования специальных машинных инструкций. На Рисунке 12.6 представлены реализующие семафоры функции, написанные на языке Си. Функция Pprim блокирует семафор по результатам проверки значений, содержащихся в массиве val; каждый процессор в системе управляет значением одного элемента массива. Прежде чем заблокировать семафор, процессор проверяет, не заблокирован ли уже семафор другими процессорами (соответствующие им элементы в массиве val тогда имеют значения, равные 2), а также не предпринимаются ли попытки в данный момент заблокировать семафор со стороны процессоров с более низким кодом идентификации (соответствующие им элементы имеют значения, равные 1). Если любое из условий выполняется, процессор переустанавливает значение своего элемента в 1 и повторяет попытку. Когда функция Pprim открывает внешний цикл, переменная цикла имеет значение, на единицу превышающее код идентификации того процессора, который использовал ресурс последним, тем самым гарантируется, что ни один из процессоров не может монопольно завладеть ресурсом (в качестве доказательства сошлемся на [Dijkstra 65] и [Coffman 73]). Функция Vprim освобождает семафор и открывает для других процессоров возможность получения исключительного доступа к ресурсу путем очистки соответствующего текущему процессору элемента в массиве val и перенастройки значения lastid. Чтобы защитить ресурс, следует выполнить следующий набор команд:
Pprim(семафор);
команды использования ресурса;
Vprim(семафор);
В большинстве машин имеется набор элементарных (неделимых) инструкций,
реализующих операцию блокирования более дешевыми средствами, ибо циклы, входящие в функцию Pprim, работают медленно и снижают производительность системы. Так, например, в машинах серии IBM 370 поддерживается инструкция compare and swap (сравнить и переставить), в машине AT amp;T 3B20 — инструкция read and clear (прочитать и очистить). При выполнении инструкции read and clear процессор считывает содержимое ячейки памяти, очищает ее (сбрасывает в 0) и по результатам сравнения первоначального содержимого с 0 устанавливает код завершения инструкции. Если ту же инструкцию над той же ячейкой параллельно выполняет еще один процессор, один из двух процессоров прочитает первоначальное содержимое, а другой — 0: неделимость операции гарантируется аппаратным путем. Таким образом, за счет использования данной инструкции функцию Pprim можно было бы реализовать менее сложными средствами (Рисунок 12.7). Процесс повторяет инструкцию read and clear в цикле до тех пор, пока не будет считано значение, отличное от нуля. Начальное значение компоненты семафора, связанной с блокировкой, должно быть равно 1.
Как таковую, данную семафорную конструкцию нельзя реализовать в составе ядра операционной системы, поскольку работающий с ней процесс не выходит из цикла, пока не достигнет своей цели. Если семафор используется для блокирования структуры данных, процесс, обнаружив семафор заблокированным, приостанавливает свое выполнение, чтобы ядро имело возможность переключиться на контекст другого процесса и выполнить другую полезную работу. С помощью функций Pprim и Vprim можно реализовать более сложный набор семафорных операций, соответствующий тому составу, который определен в разделе 12.3.1.
struct semaphore {
int val[NUMPROCS]; /* замок 1 элемент на каждый процессор */
int lastid; /* идентификатор процессора, получившего семафор последним */
};
int procid; /* уникальный идентификатор процессора */
int lastid; /* идентификатор процессора, получившего семафор последним */
INIT(semaphore)
struct semaphore semaphore;
{
int i;
for (i = 0; i ‹ NUMPROCS; i++) semaphore.val[i] = 0;
}
Pprim(semaphore)
struct semaphore semaphore;
{
int i, first;
loop:
first = lastid;
semaphore.val[procid] = 1;
forloop:
for (i = first; i ‹ NUMPROCS; i++) {
if (i == procid) {
semaphore.val[i] = 2;
for (i = 1; i ‹ NUMPROCS; i++) if (i != procid && semaphore.val[i] == 2) goto loop;
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|