Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 5)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
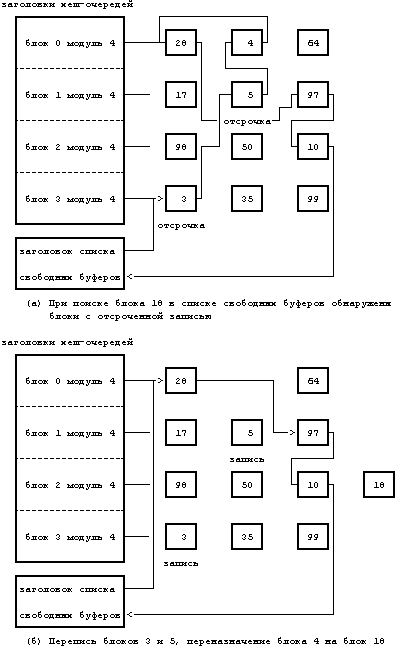
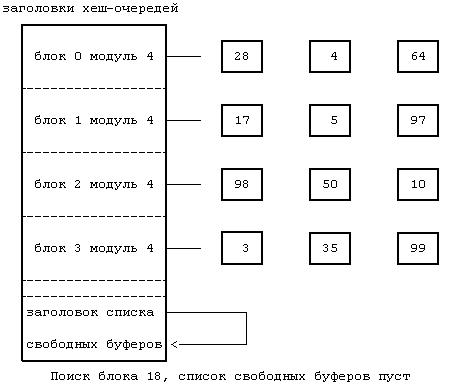
раздел 3.4). Ядро повышает приоритет прерывания работы процессора так, чтобы запретить возникновение любых прерываний от диска на время работы со списком свободных буферов, предупреждая искажение указателей буфера в результате вложенного выполнения алгоритма brelse. Похожие последствия могут произойти, если программа обработки прерываний запустит алгоритм brelse во время выполнения процессом алгоритма getblk, поэтому ядро повышает приоритет прерывания работы процессора и в стратегических моментах выполнения алгоритма getblk. Более подробно эти случаи мы разберем с помощью упражнений. При выполнении алгоритма getblk имеет место случай 2, когда ядро просматривает хеш-очередь, в которой должен был бы находиться блок, но не находит его там. Так как блок не может быть ни в какой другой хеш-очереди, поскольку он не должен «хешироваться» в другом месте, следовательно, его нет в буферном кеше. Поэтому ядро удаляет первый буфер из списка свободных буферов; этот буфер был уже выделен другому дисковому блоку и также находится в хеш-очереди. Если буфер не помечен для отложенной переписи, ядро помечает буфер занятым, удаляет его из хеш-очереди, где он находится, назначает в заголовке буфера номера устройства и блока, соответствующие данному дисковому блоку, и помещает буфер в хеш-очередь. Ядро использует буфер, не переписав информацию, которую буфер прежде хранил для другого дискового блока. Тот процесс, который будет искать прежний дисковый блок, не обнаружит его в пуле и получит для него точно таким же образом новый буфер из списка свободных буферов. Когда ядро заканчивает работу с буфером, оно освобождает буфер вышеописанным способом. На Рисунке 3.7, например, ядро ищет блок 18, но не находит его в хеш-очереди, помеченной как «блок 2 модуль 4». Поэтому ядро удаляет первый буфер из списка свободных буферов (блок 3), назначает его блоку 18 и помещает его в соответствующую хеш-очередь.
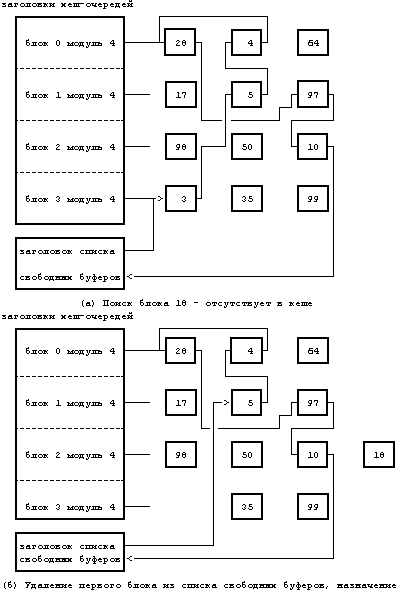 Если при выполнении алгоритма getblk имеет место случай 3, ядро так же должно выделить буфер из списка свободных буферов. Однако, оно обнаруживает, что удаляемый из списка буфер был помечен для отложенной переписи, поэтому прежде чем использовать буфер ядро должно переписать его содержимое на диск. Ядро приступает к асинхронной записи на диск и пытается выделить другой буфер из списка. Когда асинхронная запись заканчивается, ядро освобождает буфер и помещает его в начало списка свободных буферов. Буфер сам продвинулся от конца списка свободных буферов к началу списка. Если после асинхронной переписи ядру бы понадобилось поместить буфер в конец списка, буфер получил бы «зеленую улицу» по всему списку свободных буферов, результат такого перемещения противоположен действию алгоритма поиска буферов, к которым наиболее долго не было обращений. Например, если обратиться к Рисунку 3.8, ядро не смогло обнаружить блок 18, но когда попыталось выделить первые два буфера (по очереди) в списке свободных буферов, то оказалось, что они оба помечены для отложенной переписи. Ядро удалило их из списка, запустило операции переписи на диск в соответствующие блоки, и выделило третий буфер из списка, блок 4. Далее ядро присвоило новые значения полям буфера «номер устройства» и «номер блока» и включило буфер, получивший имя «блок 18», в новую хеш-очередь. В четвертом случае (Рисунок 3.9) ядро, работая с процессом A, не смогло найти дисковый блок в соответствующей хеш-очереди и предприняло попытку выделить из списка свободных буферов новый буфер, как в случае 2. Однако, в списке не оказалось ни одного буфера, поэтому процесс A приостановился до тех пор, пока другим процессом не будет выполнен алгоритм brelse, высвобождающий буфер. Планируя выполнение процесса A, ядро вынуждено снова просматривать хеш-очередь в поисках блока. Оно не в состоянии немедленно выделить буфер из списка свободных буферов, так как возможна ситуация, когда свободный буфер ожидают сразу несколько процессов и одному из них будет выделен вновь освободившийся буфер, на который уже нацелился процесс A. Таким образом, алгоритм поиска блока снова гарантирует, что только один буфер включает содержимое дискового блока. На Рисунке 3.10 показана конкуренция между двумя процессами за освободившийся буфер. Последний случай (Рисунок 3.11) наиболее сложный, поскольку он связан с комплексом взаимоотношений между несколькими процессами. Предположим, что ядро, работая с процессом A, ведет поиск дискового блока и выделяет буфер, но приостанавливает выполнение процесса перед освобождением буфера. Например, если процесс A попытается считать дисковый блок и выделить буфер, как в случае 2, то он приостановится до момента завершения передачи данных с диска. Предположим, что пока процесс A приостановлен, ядро активизирует второй процесс, B, который пытается обратиться к дисковому блоку, чей буфер был только что заблокирован процессом A. Процесс B (случай 5) обнаружит этот захваченный блок в хеш-очереди. Так как использовать захваченный буфер не разрешается и, кроме того, нельзя выделить для одного и того же дискового блока второй буфер, процесс B помечает буфер как «запрошенный» и затем приостанавливается до того момента, когда процесс A освободит данный буфер. В конце концов процесс A освобождает буфер и замечает, что он запрошен. Тогда процесс A «будит» все процессы, приостановленные по событию «буфер становится свободным», включая и процесс B. Когда же ядро вновь запустит на выполнение процесс B, процесс B должен будет убедиться в том, что буфер свободен. Возможно, что третий процесс, C, ждал освобождения этого же буфера, и ядро запланировало активизацию процесса C раньше B; при этом процесс C мог приостановиться и оставить буфер заблокированным. Следовательно, процесс B должен проверить то, что блок действительно свободен.
Рисунок 3.8. Третий случай выделения буфера
Рисунок 3.9. Четвертый случай выделения буфера
Процесс B также должен убедиться в том, что в буфере содержится первоначально затребованный дисковый блок, поскольку процесс C мог выделить данный буфер другому блоку, как в случае 2. При выполнении процесса B может обнаружиться, что он ждал освобождения буфера не с тем содержимым, поэтому процессу B придется вновь заниматься поисками блока. Если же его настроить на автоматическое выделение буфера из списка свободных буферов, он может упустить из виду возможность того, что какой-либо другой процесс уже выделил буфер для данного блока.
Рисунок 3.10. Состязание за свободный буфер
В конце концов, процесс B найдет этот блок, при необходимости выбрав новый буфер из списка свободных буферов, как в случае 2. Пусть некоторый процесс, осуществляя поиск блока 99 (Рисунок 3.11), обнаружил этот блок в хеш-очереди, однако он оказался занятым. Процесс приостанавливается до момента освобождения блока, после чего он запускает весь алгоритм с самого начала. На Рисунке 3.12 показано содержимое занятого буфера. Алгоритм выделения буфера должен быть надежным; процессы не должны «засыпать» навсегда и рано или поздно им нужно выделить буфер. Ядро гарантирует такое положение, при котором все процессы, ожидающие выделения буфера, продолжат свое выполнение, благодаря тому, что ядро распределяет буферы во время обработки обращений к операционной системе и освобождает их перед возвратом управления процессам.
В режиме задачи процессы непосредственно не контролируют выделение буферов ядром системы, поэтому они не могут намеренно «захватывать» буферы. Ядро теряет контроль над буфером только тогда, когда ждет завершения операции ввода-вывода между буфером и диском. Было задумано так, что если дисковод испорчен, он не может прерывать работу центрального процессора, и тогда ядро никогда не освободит буфер. Дисковод должен следить за работой аппаратных средств в таких случаях и возвращать ядру код ошибки, сообщая о плохой работе диска. Короче говоря, ядро может гарантировать, что процессы, приостановленные в ожидании буфера, в конце концов возобновят свое выполнение. 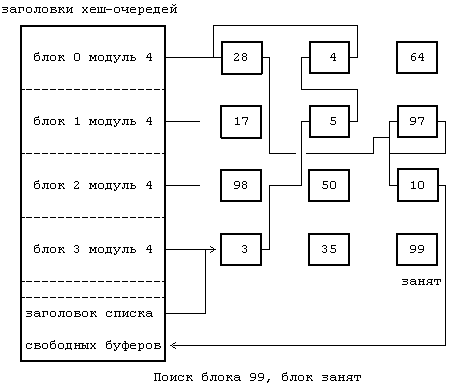 Можно также представить себе ситуацию, когда процесс «зависает» в ожидании получения доступа к буферу. В четвертом случае, например, если несколько процессов приостанавливаются, ожидая освобождения буфера, ядро не гарантирует, что они получат доступ к буферу в той очередности, в которой они запросили доступ. Процесс может приостановить и возобновить свое выполнение, когда буфер станет свободным, только для того, чтобы приостановиться вновь из — за того, что другой процесс получил управление над буфером первым. Теоретически, так может продолжаться вечно, но практически такой проблемы не возникает в связи с тем, что в системе обычно заложено большое количество буферов.
3.4 ЧТЕНИЕ И ЗАПИСЬ ДИСКОВЫХ БЛОКОВ
Теперь, когда алгоритм выделения буферов нами уже рассмотрен, будет легче понять процедуру чтения и записи дисковых блоков. Чтобы считать дисковый блок (Рисунок 3.13), процесс использует алгоритм getblk для поиска блока в буферном кеше. Если он там, ядро может возвратить его немедленно без физического считывания блока с диска. Если блок в кеше отсутствует, ядро приказывает дисководу «запланировать» запрос на чтение и приостанавливает работу, ожидая завершения ввода-вывода. Дисковод извещает контроллер диска о том, что он собирается считать информацию, и контроллер тогда передает информацию в буфер. Наконец, дисковый контроллер прерывает работу процессора, сообщая о завершении операции ввода-вывода, и программа обработки прерываний от диска возобновляет выполнение приостановленного процесса; теперь содержимое дискового блока находится в буфере. Модули, запросившие информацию данного блока, получают ее; когда буфер им уже не потребуется, они освободят его для того, чтобы другие процессы получили к нему доступ.  В главе 5 будет показано, как модули более высокого уровня (такие как подсистема управления файлами) могут предчувствовать потребность во втором дисковом блоке, когда процесс читает информацию из файла последовательно. Эти модули формируют запрос на асинхронное выполнение второй операции ввода-вывода, надеясь на то, что информация уже будет в памяти, когда вдруг возникнет необходимость в ней, и тем самым повышая быстродействие системы. Для этого ядро выполняет алгоритм чтения блока с продвижением breada (Рисунок 3.14). Ядро проверяет, находится ли в кеше первый блок, и если его там нет, приказывает дисководу считать этот блок. Если в буферном кеше отсутствует и второй блок, ядро дает команду дисководу считать асинхронно и его. Затем процесс приостанавливается, ожидая завершения операции ввода-вывода над первым блоком. Когда выполнение процесса возобновляется, он возвращает буфер первому блоку и не обращает внимание на то, когда завершится операция ввода-вывода для второго блока. После завершения этой операции контроллер диска прерывает работу системы; программа обработки прерываний узнает о том, что ввод-вывод выполнялся асинхронно, и освобождает буфер (алгоритм brelse). Если бы она не освободила буфер, буфер остался бы заблокированным и по этой причине недоступным для всех процессов. Невозможно заранее разблокировать буфер, так как операция ввода-вывода, связанная с буфером, активна и, следовательно, содержимое буфера еще не адекватно. Позже, если процесс пожелает считать второй блок, он обнаружит его в буферном кеше, поскольку к тому времени операция ввода-вывода закончится. Если же, в начале выполнения алгоритма breada, первый блок обнаружился в буферном кеше, ядро тут же проверяет, находится там же и второй блок, и продолжает работу по только что описанной схеме.
алгоритм bread /* чтение блока */
входная информация: номер блока в файловой системе
выходная информация: буфер, содержащий данные
{
получить буфер для блока (алгоритм getblk);
if (данные в буфере правильные)
return буфер;
приступить к чтению с диска;
sleep (до завершения операции чтения);
return (буфер);
}
Рисунок 3.13. Алгоритм чтения дискового блока
Алгоритм записи содержимого буфера в дисковый блок (Рисунок 3.15) похож на алгоритм чтения. Ядро информирует дисковод о том, что есть буфер, содержимое которого должно быть выведено, и дисковод планирует операцию ввода-вывода блока. Если запись производится синхронно, вызывающий процесс приостанавливается, ожидая ее завершения и освобождая буфер в момент возобновления своего выполнения. Если запись производится асинхронно, ядро запускает операцию записи на диск, но не ждет ее завершения. Ядро освободит буфер, когда завершится ввод-вывод.
алгоритм breada /* чтение блока с продвижением */
входная информация:
(1) в файловой системе номер блока для немедленного считывания
(2) в файловой системе номер блока для асинхронного считывания
выходная информация: буфер с данными, считанными немедленно
{
if (первый блок отсутствует в кеше)
{
получить буфер для первого блока (алгоритм getblk);
if (данные в буфере неверные)
приступить к чтению с диска;
}
if (второй блок отсутствует в кеше)
{
получить буфер для второго блока (алгоритм getblk);
if (данные в буфере верные)
освободить буфер (алгоритм brelse);
else
приступить к чтению с диска;
}
if (первый блок первоначально находился в кеше)
{
считать первый блок (алгоритм bread);
return буфер;
}
sleep (до того момента, когда первый буфер будет содержать верные данные);
return буфер;
}
Рисунок 3.14. Алгоритм чтения блока с продвижением
Могут возникнуть ситуации, и это будет показано в следующих двух главах, когда ядро не записывает данные немедленно на диск. Если запись «откладывается», ядро соответствующим образом помечает буфер, освобождая его по алгоритму brelse, и продолжает работу без планирования ввода-вывода. Ядро записывает блок на диск перед тем, как другой процесс сможет переназначить буфер другому блоку, как показано в алгоритме getblk (случай 3). Между тем, ядро надеется на то, что процесс получает доступ до того, как буфер будет переписан на диск; если этот процесс впоследствии изменит содержимое буфера, ядро произведет дополнительную операцию по сохранению изменений на диске.
алгоритм bwrite /* запись блока */
входная информация: буфер
выходная информация: отсутствует
{
приступить к записи на диск;
if (ввод-вывод синхронный)
{
sleep (до завершения ввода-вывода);
освободить буфер (алгоритм brelse);
}
else
if (буфер помечен для отложенной записи)
пометить буфер для последующего размещения в «голове» списка свободных буферов;
}
Рисунок 3.15. Алгоритм записи дискового блока
Отложенная запись отличается от асинхронной записи. Выполняя асинхронную запись, ядро запускает дисковую операцию немедленно, но не дожидается ее завершения. Что касается отложенной записи, ядро отдаляет момент физической переписи на диск насколько возможно; затем по алгоритму getblk (случай 3) оно помечает буфер как «старый» и записывает блок на диск асинхронно. После этого контроллер диска прерывает работу системы и освобождает буфер, используя алгоритм brelse; буфер помещается в «голову» списка свободных буферов, поскольку он имеет пометку «старый». Благодаря наличию двух выполняющихся асинхронно операций ввода-вывода — чтения блока с продвижением и отложенной записи — ядро может запускать программу brelse из программы обработки прерываний. Следовательно, ядро вынуждено препятствовать возникновению прерываний при выполнении любой процедуры, работающей со списком свободных буферов, поскольку brelse помещает буферы в этот список.
3.5 ПРЕИМУЩЕСТВА И НЕУДОБСТВА БУФЕРНОГО КЕША
Использование буферного кеша имеет, с одной стороны, несколько преимуществ и, с другой стороны, некоторые неудобства.
• Использование буферов позволяет внести единообразие в процедуру обращения к диску, поскольку ядру нет необходимости знать причину ввода-вывода. Вместо этого, ядро копирует данные в буфер и из буфера, невзирая на то, являются ли данные частью файла, индекса или суперблока. Буферизация ввода-вывода с диска повышает модульность разработки программ, поскольку те составные части ядра, которые занимаются вводом-выводом на диск, имеют один интерфейс на все случаи. Короче говоря, упрощается проектирование системы.
• Система не накладывает никаких ограничений на выравнивание информации пользовательскими процессами, выполняющими ввод-вывод, поскольку ядро производит внутреннее выравнивание информации. В различных аппаратных реализациях часто требуется выравнивать информацию для ввода-вывода с диска определенным образом, т. е. производить к примеру двухбайтное или четырехбайтное выравнивание данных в памяти. Без механизма буферизации программистам пришлось бы заботиться самим о правильном выравнивании данных. По этой причине на машинах с ограниченными возможностями в выравнивании адресов возникает большое количество ошибок программирования и, кроме того, становится проблемой перенос программ в операционную среду UNIX. Копируя информацию из пользовательских буферов в системные буферы (и обратно), ядро системы устраняет необходимость в специальном выравнивании пользовательских буферов, делая пользовательские программы более простыми и мобильными.
• Благодаря использованию буферного кеша, сокращается объем дискового трафика и время реакции и повышается общая производительность системы. Процессы, считывающие данные из файловой системы, могут обнаружить информационные блоки в кеше и им не придется прибегать ко вводу-выводу с диска. Ядро часто применяет «отложенную запись», чтобы избежать лишних обращений к диску, оставляя блок в буферном кеше и надеясь на попадание блока в кеш. Очевидно, что шансы на такое попадание выше в системах с большим количеством буферов. Тем не менее, число буферов, которые можно заложить в системе, ограничивается объемом памяти, доступной выполняющимся процессам: если под буферы задействовать слишком много памяти, то система будет работать медленнее в связи с тем, что ей придется заниматься подкачкой и замещением выполняющихся процессов.
• Алгоритмы буферизации помогают поддерживать целостность файловой системы, так как они сохраняют общий, первоначальный и единственный образ дисковых блоков, содержащихся в кеше. Если два процесса одновременно попытаются обратиться к одному и тому же дисковому блоку, алгоритмы буферизации (например, getblk) параллельный доступ преобразуют в последовательный, предотвращая разрушение данных.
• Сокращение дискового трафика является важным преимуществом с точки зрения обеспечения хорошей производительности или быстрой реакции системы, однако стратегия кеширования также имеет некоторые неудобства. Так как ядро в случае отложенной записи не переписывает данные на диск немедленно, такая система уязвима для сбоев, которые оставляют дисковые данные в некорректном виде. Хотя в последних версиях системы и сокращен ущерб, наносимый катастрофическими сбоями, основная проблема остается: пользователь, запрашивающий выполнение операции записи, никогда не знает, в какой момент данные завершат свой путь на диск
.
• Использование буферного кеша требует дополнительного копирования информации при ее считывании и записи пользовательскими процессами. Процесс, записывающий данные, передает их ядру и ядро копирует данные на диск; процесс, считывающий данные, получает их от ядра, которое читает данные с диска. При передаче большого количества данных дополнительное копирование отрицательным образом отражается на производительности системы, однако при передаче небольших объемов данных производительность повышается, поскольку ядро буферизует данные (используя алгоритм getblk и отложенную запись) до тех пор, пока это представляется эффективным с точки зрения экономии времени работы с диском.
3.6 ВЫВОДЫ
В данной главе была рассмотрена структура буферного кеша и различные способы, которыми ядро размещает блоки в кеше. В алгоритмах буферизации сочетаются несколько простых идей, которые в сумме обеспечивают работу механизма кеширования. При работе с блоками в буферном кеше ядро использует алгоритм замены буферов, к которым наиболее долго не было обращений, предполагая, что к блокам, к которым недавно было обращение, вероятно, вскоре обратятся снова. Очередность, в которой буферы появляются в списке свободных буферов, соответствует очередности их предыдущего использования. Остальные алгоритмы обслуживания буферов, типа «первым пришел — первым вышел» и замещения редко используемых, либо являются более сложными в реализации, либо снижают процент попадания в кеш. Использование функции хеширования и хеш-очередей дает ядру возможность ускорить поиск заданных блоков, а использование двунаправленных указателей в списках облегчает исключение буферов.
Ядро идентифицирует нужный ему блок по номеру логического устройства и номеру блока. Алгоритм getblk просматривает буферный кеш в поисках блока и, если буфер присутствует и свободен, блокирует буфер и возвращает его. Если буфер заблокирован, обратившийся к нему процесс приостанавливается до тех пор, пока буфер не освободится. Механизм блокирования гарантирует, что только один процесс в каждый момент времени работает с буфером. Если в кеше блок отсутствует, ядро назначает блоку свободный буфер, блокирует и возвращает его. Алгоритм bread выделяет блоку буфер и при необходимости читает туда информацию. Алгоритм bwrite копирует информацию в предварительно выделенный буфер. Если при выполнении указанных алгоритмов ядро не увидит необходимости в немедленном копировании данных на диск, оно пометит буфер для «отложенной записи», чтобы избежать излишнего ввода-вывода. К сожалению, процедура откладывания записи сопровождается тем, что процесс никогда не уверен, в какой момент данные физически попадают на диск. Если ядро записывает данные на диск синхронно, оно поручает драйверу диска передать блок файловой системе и ждет прерывания, сообщающего об окончании ввода-вывода.
Существует множество способов использования ядром буферного кеша. Посредством буферного кеша ядро обеспечивает обмен данными между прикладными программами и файловой системой, передачу дополнительной системной информации, например, индексов, между алгоритмами ядра и файловой системой. Ядро также использует буферный кеш, когда читает программы в память для выполнения. В следующих главах будет рассмотрено множество алгоритмов, использующих процедуры, описанные в данной главе. Другие алгоритмы, которые кешируют индексы и страницы памяти, также используют приемы, похожие на те, что описаны для буферного кеша.
3.7 УПРАЖНЕНИЯ
1. Рассмотрим функцию хеширования применительно к Рисунку 3.3. Наилучшей функцией хеширования является та, которая единым образом распределяет блоки между хеш-очередями. Что Вы могли бы предложить в качестве оптимальной функции хеширования? Должна ли эта функция в своих расчетах использовать логический номер устройства?
2. В алгоритме getblk, если ядро удаляет буфер из списка свободных буферов, оно должно повысить приоритет прерывания работы процессора так, чтобы блокировать прерывания до проверки списка. Почему?
*3. В алгоритме getblk ядро должно повысить приоритет прерывания работы процессора так, чтобы блокировать прерывания до проверки занятости блока. (Это не показано в тексте.) Почему?
4. В алгоритме brelse ядро помещает буфер в «голову» списка свободных буферов, если содержимое буфера неверно. Если содержимое буфера неверно, должен ли буфер появиться в хеш-очереди?
5. Предположим, что ядро выполняет отложенную запись блока. Что произойдет, когда другой процесс выберет этот блок из его хеш-очереди? Из списка свободных буферов?
*6. Если несколько процессов оспаривают буфер, ядро гарантирует, что ни один из них не приостановится навсегда, но не гарантирует, что процесс не «зависнет» и дождется получения буфера. Переделайте алгоритм getblk так, чтобы процессу было в конечном итоге гарантировано получение буфера.
7. Переделайте алгоритмы getblk и brelse так, чтобы ядро следовало не схеме замещения буферов, к которым наиболее долго не было обращений, а схеме «первым пришел — первым вышел». Повторите то же самое со схемой замещения редко используемых буферов.
8. Опишите ситуацию в алгоритме bread, когда информация в буфере уже верна.
*9. Опишите различные ситуации, встречающиеся в алгоритме breada. Что произойдет в случае следующего выполнения алгоритма bread или breada, когда текущий блок прочитан с продвижением? В алгоритме breada, если первый или второй блок отсутствует в кеше, в дальнейшем при проверке правильности содержимого буфера предполагается, что блок мог быть в буферном пуле. Как это может быть?
10. Опишите алгоритм, запрашивающий и получающий любой свободный буфер из буферного пула. Сравните этот алгоритм с getblk.
11. В различных системных операциях, таких как umount и sync (глава 5), требуется, чтобы ядро перекачивало на диск содержимое всех буферов, которые помечены для «отложенной записи» в данной файловой системе. Опишите алгоритм, реализующий перекачку буферов. Что произойдет с очередностью расположения буферов в списке свободных буферов в результате этой операции? Как ядро может гарантировать, что ни один другой процесс не подберется к буферу с пометкой «отложенная запись» и не сможет переписать его содержимое в файловую систему, пока процесс перекачки приостановлен в ожидании завершения операции ввода-вывода?
12. Определим время реакции системы как среднее время выполнения системного вызова. Определим пропускную способность системы как количество процессов, которые система может выполнять в данный период времени. Объясните, как буферный кеш может способствовать повышению реакции системы. Способствует ли он с неизбежностью увеличению пропускной способности системы?
ГЛАВА 4. ВНУТРЕННЕЕ ПРЕДСТАВЛЕНИЕ ФАЙЛОВ
Как уже было замечено в главе 2, каждый файл в системе UNIX имеет уникальный индекс. Индекс содержит информацию, необходимую любому процессу для того, чтобы обратиться к файлу, например, права собственности на файл, права доступа к файлу, размер файла и расположение данных файла в файловой системе. Процессы обращаются к файлам, используя четко определенный набор системных вызовов и идентифицируя файл строкой символов, выступающих в качестве составного имени файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро системы преобразует это имя в индекс файла.
Эта глава посвящена описанию внутренней структуры файлов в операционной системе UNIX, в следующей же главе рассматриваются обращения к операционной системе, связанные с обработкой файлов. Раздел 4.1 касается индекса и работы с ним ядра, раздел 4.2 — внутренней структуры обычных файлов и некоторых моментов, связанных с чтением и записью ядром информации файлов. В разделе 4.3 исследуется строение каталогов — структур данных, позволяющих ядру организовывать файловую систему в виде иерархии файлов, раздел 4.4 содержит алгоритм преобразования имен пользовательских файлов в индексы. В разделе 4.5 дается структура суперблока, а в разделах 4.6 и 4.7 представлены алгоритмы назначения файлам дисковых индексов и дисковых блоков. Наконец, в разделе 4.8 идет речь о других типах файлов в системе, а именно о каналах и файлах устройств.
Алгоритмы, описанные в этой главе, уровнем выше по сравнению с алгоритмами управления буферным кешем, рассмотренными в предыдущей главе (Рисунок 4.1). Алгоритм iget возвращает последний из идентифицированных индексов с возможностью считывания его с диска, используя буферный кеш, а алгоритм iput освобождает индекс. Алгоритм bmap устанавливает параметры ядра, связанные с обращением к файлу. Алгоритм namei преобразует составное имя пользовательского файла в имя индекса, используя алгоритмы iget, iput и bmap. Алгоритмы alloc и free выделяют и освобождают дисковые блоки для файлов, алгоритмы ialloc и ifree назначают и освобождают для файлов индексы.
Алгоритмы работы с файловой системой на нижнем уровне
namei
alloc free
ialloc ifree
iget
iput
bmap
алгоритмы работы с буферами
getblk
brelse
bread
breada
bwrite
Рисунок 4.1. Алгоритмы файловой системы
4.1 ИНДЕКСЫ
4.1.1 Определение
Индексы существуют на диске в статической форме и ядро считывает их в память прежде, чем начать с ними работать. Дисковые индексы включают в себя следующие поля:
• Идентификатор владельца файла. Права собственности разделены между индивидуальным владельцем и «групповым» и тем самым помогают определить круг пользователей, имеющих права доступа к файлу. Суперпользователь имеет право доступа ко всем файлам в системе.
• Тип файла. Файл может быть файлом обычного типа, каталогом, специальным файлом, соответствующим устройствам ввода-вывода символами или блоками, а также абстрактным файлом канала (организующим обслуживание запросов в порядке поступления, «первым пришел — первым вышел»).
• Права доступа к файлу. Система разграничивает права доступа к файлу для трех классов пользователей: индивидуального владельца файла, группового владельца и прочих пользователей; каждому классу выделены определенные права на чтение, запись и исполнение файла, которые устанавливаются индивидуально. Поскольку каталоги как файлы не могут быть исполнены, разрешение на исполнение в данном случае интерпретируется как право производить поиск в каталоге по имени файла.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|