Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 27)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
Если подвести итог, можно сказать, что номер устройства, используемый программой обработки прерываний, идентифицирует единицу аппаратуры, а младший номер в файле устройства идентифицирует устройство для ядра. Драйвер устройства устанавливает соответствие между младшим номером устройства и номером единицы аппаратуры.
10.2 ДИСКОВЫЕ ДРАЙВЕРЫ
Так сложилось исторически, что дисковые устройства в системах UNIX разбивались на разделы, содержащие различные файловые системы, что означало "деление [дискового] пакета на несколько управляемых по-своему частей" (см. [System V 84b]). Например, если на диске располагаются четыре файловые системы, администратор может оставить одну из них несмонтированной, одну смонтировать только для чтения, а две других только для записи. Несмотря на то, что все файловые системы сосуществуют на одном физическом устройстве, пользователи не могут ни обращаться к файлам немонтированной файловой системы, используя методы доступа, описанные в главах 4 и 5, ни записывать файлы в файловые системы, смонтированные только для чтения. Более того, так как каждый раздел (и, следовательно, файловая система) занимает на диске смежные дорожки и цилиндры, скопировать всю файловую систему легче, чем в том случае, если бы раздел занимал участки, разбросанные по всему дисковому тому. Дисковый драйвер транслирует адрес файловой системы, состоящий из логического номера устройства и номера блока, в точный номер дискового сектора. Драйвер получает адрес одним из следующих путей: либо стратегическая процедура использует буфер из буферного пула, заголовок которого содержит номера устройства и блока, либо процедуры чтения и записи передают логический (младший) номер устройства в качестве параметра; они преобразуют адрес смещения в байтах, хранящийся в пространстве задачи, в адрес соответствующего блока. Дисковый драйвер использует номер устройства для идентификации физического устройства и указания используемого раздела, обращаясь при этом к внутренним таблицам для поиска сектора, отмечающего начало раздела на диске. Наконец, он добавляет номер блока в файловой системе к номеру блока, с которого начинается каждый сектор, чтобы идентифицировать сектор, используемый для ввода-вывода.
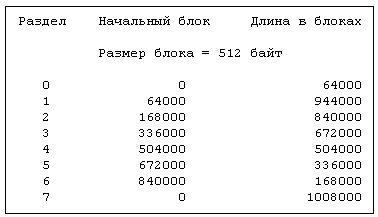
Рисунок 10.7. Разделы на диске RP07
Исторически сложилось так, что размеры дисковых разделов устанавливаются в зависимости от типа диска. Например, диск DEC RP07 разбит на разделы, характеристика которых приведена на Рисунке 10.7. Предположим, что файлы "/dev/dsk0", "/dev/dsk1", "/dev/dsk2" и "/dev/dsk3" соответствуют разделам диска RP07, имеющим номера от 0 до 3, и имеют аналогичные младшие номера. Пусть размер логического блока в файловой системе совпадает с размером дискового блока. Если ядро пытается обратиться к блоку с номером 940 в файловой системе, хранящейся в "/dev/dsk3", дисковый драйвер переадресует запрос к блоку с номером 336940 (раздел 3 начинается с блока, имеющего номер 336000; 336000 + 940 = 336940) на диске. Размеры разделов на диске варьируются и администраторы располагают файловые системы в разделах соответствующего размера: большие файловые системы попадают в разделы большего размера и т. д. Разделы на диске могут перекрываться. Например, разделы 0 и 1 на диске RP07 не пересекаются, но вместе они занимают блоки с номерами от 0 до 1008000, то есть весь диск. Раздел 7 так же занимает весь диск. Перекрытие разделов не имеет значения, поскольку файловые системы, хранящиеся в разделах, размещаются таким образом, что между ними нет пересечений. Иметь один раздел, включающий в себя все дисковое пространство, выгодно, поскольку весь том можно быстро скопировать. Использование разделов фиксированного состава и размера ограничивает гибкость дисковой конфигурации. Информацию о разделах в закодированном виде не следует включать в дисковый драйвер, но нужно поместить в таблицу содержимого дискового тома. Однако, найти общее место на всех дисках для размещения таблицы содержимого дискового тома и сохранить тем самым совместимость с предыдущими версиями системы довольно трудно. В существующих реализациях версии V предполагается, что блок начальной загрузки первой из файловых систем на диске занимает первый сектор тома, хотя по логике это, казалось бы, самое подходящее место для таблицы содержимого тома. И все же дисковый драйвер должен иметь закодированную информацию о месте расположения таблицы содержимого тома для каждого диска, не препятствуя существованию дисковых разделов переменного размера. В связи с тем, что для системы UNIX является типичным высокий уровень дискового трафика, драйвер диска должен максимизировать передачу данных с тем, чтобы обеспечить наилучшую производительность всей системы. Новейшие дисковые контроллеры осуществляют планирование выполнения заданий, требующих обращения к диску, позиционируют головку диска и обеспечивают передачу данных между диском и центральным процессором; иначе это приходится делать дисковому драйверу. Сервисные программы могут непосредственно обращаться к диску в обход стандартного метода доступа к файловой системе, рассмотренного в главах 4 и 5, как пользуясь блочным интерфейсом, так и не прибегая к структурированию данных. Непосредственно работают с диском две важные программы — mkfs и fsck. Программа mkfs форматирует раздел диска для файловой системы UNIX, создавая при этом суперблок, список индексов, список свободных дисковых блоков с указателями и корневой каталог новой файловой системы. Программа fsck проверяет целостность существующей файловой системы и исправляет ошибки, как показано в главе 5. Рассмотрим программу, приведенную на Рисунке 10.8, в применении к файлам "/dev/dsk15" и "/dev/rdsk15", и предположим, что команда ls выдала следующую информацию:
ls -l /dev/dsk15 /dev/rdsk15 br-------- 2 root root 0,21 Feb 12 15:40 /dev/dsk15 crw-rw---- 2 root root 7,21 Mar 7 09:29 /dev/rdsk15
Отсюда видно, что файл "/dev/dsk15" соответствует устройству блочного типа, владельцем которого является пользователь под именем "root", и только пользователь "root" может читать с него непосредственно. Его старший номер 0, младший — 21. Файл "/dev/rdsk15" соответствует устройству посимвольного ввода-вывода, владельцем которого является пользователь "root", однако права доступа к которому на запись и чтение есть как у владельца, так и у группы. Его старший номер — 7, младший — 21. Процесс, открывающий файлы, получает доступ к устройству через таблицу ключей устройств ввода-вывода блоками и таблицу ключей устройств посимвольного ввода-вывода, соответственно, а младший номер устройства 21 информирует драйвер о том, к какому разделу диска производится обращение, например, дисковод 2, раздел 1. Поскольку младшие номера у файлов совпадают, они ссылаются на один и тот же раздел диска, если предположить, что это одно устройство
. Таким образом, процесс, выполняющий программу, открывает один и тот же драйвер дважды (используя различные интерфейсы), позиционирует головку к смещению с адресом 8192 и считывает данные с этого места. Результаты выполнения операций чтения должны быть идентичными при условии, что работает только одна файловая система.
#include "fcntl.h"
main() {
char buf1[4096], buf2[4096];
int fd1, fd2, i;
if (((fd1 = open("/dev/dsk5/", O_RDONLY)) == -1) || ((fd2 = open("/dev/rdsk5", O_RDONLY)) == -1)) {
printf("ошибка при открытии\n");
exit();
}
lseek(fd1, 8192L, 0);
lseek(fd2, 8192L, 0);
if ((read(fd1, buf1, sizeof(buf1)) == -1) || (read(fd2, buf2, sizeof(buf2)) == -1)) {
printf("ошибка при чтении\n");
exit();
}
for (i = 0; i ‹ sizeof(buf1); i++) if (buf1[i] != buf2[i]) {
printf("различие в смещении %d\n", i);
exit();
}
printf("данные совпадают\n");
}
Рисунок 10.8. Чтение данных с диска с использованием блочного интерфейса и без структурирования данных
Программы, осуществляющие чтение и запись на диск непосредственно, представляют опасность, поскольку манипулируют с чувствительной информацией, рискуя нарушить системную защиту. Администраторам следует защищать интерфейсы ввода-вывода путем установки прав доступа к файлам дисковых устройств. Например, дисковые файлы "/dev/dsk15" и "/dev/rdsk15" должны принадлежать пользователю с именем "root", и права доступа к ним должны быть определены таким образом, чтобы пользователю "root" было разрешено чтение, а всем остальным пользователям и чтение, и запись должны быть запрещены. Программы, осуществляющие чтение и запись на диск непосредственно, могут также нарушить целостность данных в файловой системе. Алгоритмы файловой системы, рассмотренные в главах 3, 4 и 5, координируют выполнение операций ввода-вывода, связанных с диском, тем самым поддерживая целостность информационных структур на диске, в том числе списка свободных дисковых блоков и указателей из индексов на информационные блоки прямой и косвенной адресации. Процессы, обращающиеся к диску непосредственно, обходят эти алгоритмы. Пусть даже их программы написаны с большой осторожностью, проблема целостности все равно не исчезнет, если они выполняются параллельно с работой другой файловой системы. По этой причине программа fsck не должна выполняться при наличии активной файловой системы. Два типа дискового интерфейса различаются между собой по использованию буферного кеша. При работе с блочным интерфейсом ядро пользуется тем же алгоритмом, что и для файлов обычного типа, исключение составляет тот момент, когда после преобразования адреса смещения логического байта в адрес смещения логического блока (см. алгоритм bmap в главе 4) оно трактует адрес смещения логического блока как физический номер блока в файловой системе. Затем, используя буферный кеш, ядро обращается к данным, и, в конечном итоге, к стратегическому интерфейсу драйвера. Однако, при обращении к диску через символьный интерфейс (без структурирования данных), ядро не превращает адрес смещения в адрес файла, а передает его немедленно драйверу, используя для передачи рабочее пространство задачи. Процедуры чтения и записи, входящие в состав драйвера, преобразуют смещение в байтах в смещение в блоках и копируют данные непосредственно в адресное пространство задачи, минуя буферы ядра. Таким образом, если один процесс записывает на устройство блочного типа, а второй процесс затем считывает с устройства символьного типа по тому же адресу, второй процесс может не считать информацию, записанную первым процессом, так как информация может еще находиться в буферном кеше, а не на диске. Тем не менее, если второй процесс обратится к устройству блочного типа, он автоматически попадет на новые данные, находящиеся в буферном кеше. При использовании символьного интерфейса можно столкнуться со странной ситуацией. Если процесс читает или пишет на устройство посимвольного ввода-вывода порциями меньшего размера, чем, к примеру, блок, результаты будут зависеть от драйвера. Например, если производить запись на ленту по 1 байту, каждый байт может попасть в любой из ленточных блоков. Преимущество использования символьного интерфейса состоит в скорости, если не возникает необходимость в кешировании данных для дальнейшей работы. Процессы, обращающиеся к устройствам ввода — вывода блоками, передают информацию блоками, размер каждого из которых ограничивается размером логического блока в данной файловой системе. Например, если размер логического блока в файловой системе 1 Кбайт, за одну операцию ввода-вывода может быть передано не больше 1 Кбайта информации. При этом процессы, обращающиеся к диску с помощью символьного интерфейса, могут передавать за одну дисковую операцию множество дисковых блоков, в зависимости от возможностей дискового контроллера. С функциональной точки зрения, процесс получает тот же самый результат, но символьный интерфейс может работать гораздо быстрее. Если воспользоваться примером, приведенным на Рисунке 10.8, можно увидеть, что когда процесс считывает 4096 байт, используя блочный интерфейс для файловой системы с размером блока 1 Кбайт, ядро производит четыре внутренние итерации, на каждом шаге обращаясь к диску, прежде чем вызванная системная функция возвращает управление, но когда процесс использует символьный интерфейс, драйвер может закончить чтение за одну дисковую операцию. Более того, использование блочного интерфейса вызывает дополнительное копирование данных между адресным пространством задачи и буферами ядра, что отсутствует в символьном интерфейсе.
10.3 ТЕРМИНАЛЬНЫЕ ДРАЙВЕРЫ
Терминальные драйверы выполняют ту же функцию, что и остальные драйверы: управление передачей данных от и на терминалы. Однако, терминалы имеют одну особенность, связанную с тем, что они обеспечивают интерфейс пользователя с системой. Обеспечивая интерактивное использование системы UNIX, терминальные драйверы имеют свой внутренний интерфейс с модулями, интерпретирующими ввод и вывод строк. В каноническом режиме интерпретаторы строк преобразуют неструктурированные последовательности данных, введенные с клавиатуры, в каноническую форму (то есть в форму, соответствующую тому, что пользователь имел ввиду на самом деле) прежде, чем послать эти данные принимающему процессу; строковый интерфейс также преобразует неструктурированные последовательности выходных данных, созданных процессом, в формат, необходимый пользователю. В режиме без обработки строковый интерфейс передает данные между процессами и терминалом без каких-либо преобразований. Программисты, например, работают на клавиатуре терминала довольно быстро, но с ошибками. На этот случай терминалы имеют клавишу стирания ("erase"; клавиша может быть обозначена таким образом), чтобы пользователь имел возможность стирать часть введенной строки и вводить коррективы. Терминалы пересылают машине всю введенную последовательность, включая и символы стирания
. В каноническом режиме строковый интерфейс буферизует информацию в строки (набор символов, заканчивающийся символом возврата каретки
) и процессы стирают символы у себя, прежде чем переслать исправленную последовательность считывающему процессу. В функции строкового интерфейса входят: • построчный разбор введенных последовательностей; • обработка символов стирания; • обработка символов "удаления", отменяющих все остальные символы, введенные до того в текущей строке; • отображение символов, полученных терминалом; • расширение выходных данных, например, преобразование символов табуляции в последовательности пробелов; • сигнализирование процессам о зависании терминалов и прерывании строк или в ответ на нажатие пользователем клавиши удаления; • предоставление возможности не обрабатывать специальные символы, такие как символы стирания, удаления и возврата каретки. Функционирование без обработки подразумевает использование асинхронного терминала, поскольку процессы могут считывать символы в том виде, в каком они были введены, вместо того, чтобы ждать, когда пользователь нажмет клавишу ввода или возврата каретки. Ричи отметил, что первые строковые интерфейсы, используемые еще при разработке системы в начале 70-х годов, работали в составе программ командного процессора и редактора, но не в ядре (см. [Ritchie 84], стр.1580). Однако, поскольку в их функциях нуждается множество программ, их место в составе ядра. Несмотря на то, что строковый интерфейс выполняет такие функции, из которых логически вытекает его место между терминальным драйвером и остальной частью ядра, ядро не запускает строковый интерфейс иначе, чем через терминальный драйвер. На Рисунке 10.9 показаны поток данных, проходящий через терминальный драйвер и строковый интерфейс, и соответствующие ему управляющие воздействия, проходящие через терминальный драйвер. Пользователи могут указать, какой строковый интерфейс используется посредством вызова системной функции ioctl, но реализовать схему, по которой одно устройство использовало бы несколько строковых интерфейсов одновременно, при чем каждый интерфейсный модуль, в свою очередь, успешно вызывал бы следующий модуль для обработки данных, довольно трудно. 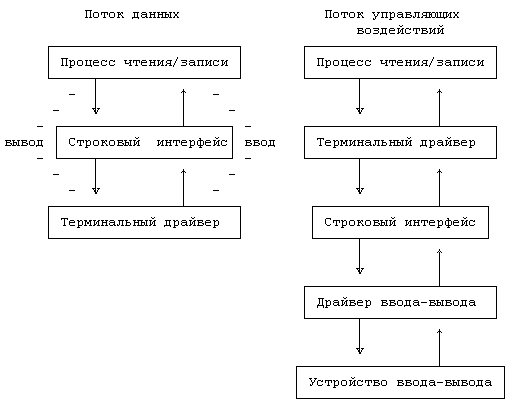
10.3.1 Символьные списки
Строковый интерфейс обрабатывает данные в символьных списках. Символьный список (clist) представляет собой переменной длины список символьных блоков с использованием указателей и с подсчетом количества символов в списке. Символьный блок (cblock) содержит указатель на следующий блок в списке, небольшой массив хранимой в символьном виде информации и адреса смещений, показывающие место расположения внутри блока корректной информации (Рисунок 10.10). Смещение до начала показывает первую позицию расположения корректной информации в массиве, смещение до конца показывает первую позицию расположения некорректной информации.
Рисунок 10.10. Символьный блок
Ядро обеспечивает ведение списка свободных символьных блоков и выполняет над символьными списками и символьными блоками шесть операций. 1. Ядро назначает драйверу символьный блок из списка свободных символьных блоков. 2. Оно также возвращает символьный блок в список свободных символьных блоков. 3. Ядро может выбирать первый символ из символьного списка: оно удаляет первый символ из первого символьного блока в списке и устанавливает значения счетчика символов в списке и указателей в блоке таким образом, чтобы последующие операции не выбирали один и тот же символ. Если в результате операции выбран последний символ блока, ядро помещает в список свободных символьных блоков пустой блок и переустанавливает указатели в символьном списке. Если в символьном списке отсутствуют символы, ядро возвращает пустой символ. 4. Ядро может поместить символ в конец символьного списка путем поиска последнего символьного блока в списке, включения символа в него и переустановки адресов смещений. Если символьный блок заполнен, ядро выделяет новый символьный блок, включает его в конец символьного списка и помещает символ в новый блок. 5. Ядро может удалять от начала списка группу символов по одному блоку за одну операцию, что эквивалентно удалению всех символов в блоке за один раз. 6. Ядро может поместить блок с символами в конец символьного списка. Символьные списки позволяют создать несложный механизм буферизации, полезный при небольшом объеме передаваемых данных, типичном для медленных устройств, таких как терминалы. Они дают возможность манипулировать с данными с каждым символом в отдельности и с группой символьных блоков. Например, Рисунок 10.11 иллюстрирует удаление символов из символьного списка; ядро удаляет по одному символу из первого блока в списке (Рисунок 10.11а-в) до тех пор, пока в блоке не останется ни одного символа (Рисунок 10.11 г); затем оно устанавливает указатель списка на следующий блок, который становится первым блоком в списке. Подобно этому на Рисунке 10.12 показано, как ядро включает символы в символьный список; при этом предполагается, что в одном блоке помещается до 8 символов и что ядро размещает новый блок в конце списка (Рисунок 10.12 г).
Рисунок 10.11. Удаление символов из символьного списка
Рисунок 10.12. Включение символов в символьный список
10.3.2 Терминальный драйвер в каноническом режиме
Структуры данных, с которыми работают терминальные драйверы, связаны с тремя символьными списками: списком для хранения данных, выводимых на терминал, списком для хранения неструктурированных вводных данных, поступивших в результате выполнения программы обработки прерывания от терминала, вызванного попыткой пользователя ввести данные с клавиатуры, и списком для хранения обработанных входных данных, поступивших в результате преобразования строковым интерфейсом специальных символов (таких как символы стирания и удаления) в неструктурированном списке.
Когда процесс ведет запись на терминал (Рисунок 10.13), терминальный драйвер запускает строковый интерфейс. Строковый интерфейс в цикле считывает символы из адресного пространства процесса и помещает их в символьный список для хранения выводных данных до тех пор, пока поток данных не будет исчерпан. Строковый интерфейс обрабатывает выводимые символы, например, заменяя символы табуляции на последовательности пробелов. Если количество символов в списке для хранения выводных данных превысит верхнюю отметку, строковый интерфейс вызывает процедуры драйвера, пересылающие данные из символьного списка на терминал и после этого приостанавливающие выполнение процесса, ведущего запись. Когда объем информации в списке для хранения выводных данных падает за нижнюю отметку, программа обработки прерываний возобновляет выполнение всех процессов, приостановленных до того момента, когда терминал сможет принять следующую порцию данных. Строковый интерфейс завершает цикл обработки, скопировав всю выводимую информацию из адресного пространства задачи в соответствующий символьный список, и вызывает выполнение процедур драйвера, пересылающих данные на терминал, о которых уже было сказано выше.
алгоритм terminal_write
{
do while(из пространства задачи еще поступают данные)
{
if (на терминал поступает информация)
{
приступить к выполнению операции записи данных из списка, хранящего выводные данные;
приостановиться (до того момента, когда терминал будет готов принять следующую порцию данных);
continue; /* возврат к началу цикла */
}
скопировать данные в объеме символьного блока из пространства задачи в список, хранящий выводные данные: строковый интерфейс преобразует символы табуляции и т. д.;
}
приступить к выполнению операции записи данных из списка, хранящего выводные данные;
}
Рисунок 10.13. Алгоритм переписи данных на терминал
'Если на терминал ведут запись несколько процессов, они независимо друг от друга следуют указанной процедуре. Выводимая информация может быть искажена; то есть на терминале данные, записываемые процессами, могут пересекаться. Это может произойти из-за того, что процессы ведут запись на терминал, используя несколько вызовов системной функции write. Ядро может переключать контекст, пока процесс выполняется в режиме задачи, между последовательными вызовами функции write, и вновь запущенные процессы могут вести запись на терминал, пока первый из процессов приостановлен. Выводимые данные могут быть также искажены и на терминале, поскольку процесс может приостановиться на середине выполнения системной функции write, ожидая завершения вывода на терминал из системы предыдущей порции данных. Ядро может запустить другие процессы, которые вели запись на терминал до того, как первый процесс был повторно запущен. По этой причине, ядро не гарантирует, что содержимое буфера данных, выводимое в результате вызова системной функции write, появится на экране терминала в непрерывном виде.
char form[]="это пример вывода строки из порожденного процесса";
main() {
char output[128];
int i;
for (i = 0; i ‹ 18; i++) {
switch (fork()) {
case -1: /* ошибка — превышено максимальное число процессов */
exit();
default: /* родительский процесс */
break;
case 0: /* порожденный процесс */
/* формат вывода строки в переменной output */
sprintf(output, "%%d\n%s%d\n", form, i, form, i);
for (;;) write(1, output, sizeof(output));
}
}
}
Рисунок 10.14. Передача данных через стандартный вывод
Рассмотрим программу, приведенную на Рисунке 10.14. Родительский процесс создает до 18 порожденных процессов; каждый из порожденных процессов записывает строку (с помощью библиотечной функции sprintf) в массив output, который включает сообщение и значение счетчика i в момент выполнения функции fork, и затем входит в цикл пошаговой переписи строки в файл стандартного вывода. Если стандартным выводом является терминал, терминальный драйвер регулирует поток поступающих данных. Выводимая строка имеет более 64 символов в длину, то есть слишком велика для того, чтобы поместиться в символьном блоке (длиной 64 байта) в версии V системы. Следовательно, терминальному драйверу требуется более одного символьного блока для каждого вызова функции write, иначе выводной поток может стать искаженным. Например, следующие строки были частью выводного потока, полученного в результате выполнения программы на машине AT&T 3B20:
this is a sample output string from child 1
this is a sample outthis is a sample output string from child 0
Чтение данных с терминала в каноническом режиме более сложная операция. В вызове системной функции read указывается количество байт, которые процесс хочет считать, но строковый интерфейс выполняет чтение по получении символа перевода каретки, даже если количество символов не указано. Это удобно с практической точки зрения, так как процесс не в состоянии предугадать, сколько символов пользователь введет с клавиатуры, и, с другой стороны, не имеет смысла ждать, когда пользователь введет большое число символов. Например, пользователи вводят командные строки для командного процессора shell и ожидают ответа shell'а на команду по получении символа возврата каретки. При этом нет никакой разницы, являются ли введенные строки простыми командами, такими как "date" или "who", или же это более сложные последовательности команд, подобные следующей:
pic file* | tbl | eqn | troff -mm -Taps | apsend
Терминальный драйвер и строковый интерфейс ничего не знают о синтаксисе командного процессора shell, и это правильно, поскольку другие программы, которые считывают информацию с терминалов (например, редакторы), имеют различный синтаксис команд. Поэтому строковый интерфейс выполняет чтение по получении символа возврата каретки.
На Рисунке 10.15 показан алгоритм чтения с терминала. Предположим, что терминал работает в каноническом режиме; в разделе 10.3.3 будет рассмотрена работа в режиме без обработки. Если в настоящий момент в любом из символьных списков для хранения вводной информации отсутствуют данные, процесс, выполняющий чтение, приостанавливается до поступления первой строки данных. Когда данные поступают, программа обработки прерывания от терминала запускает "программу обработки прерывания" строкового интерфейса, которая помещает данные в список для хранения неструктурированных вводных данных для передачи процессам, осуществляющим чтение, и в список для хранения выводных данных, передаваемых в качестве эхосопровождения на терминал. Если введенная строка содержит символ возврата каретки, программа обработки прерывания возобновляет выполнение всех приостановленных процессов чтения. Когда процесс, осуществляющий чтение, выполняется, драйвер выбирает символы из списка для хранения неструктурированных вводных данных, обрабатывает символы стирания и удаления и помещает символы в канонический символьный список. Затем он копирует строку символов в адресное пространство задачи до символа возврата каретки или до исчерпания числа символов, указанного в вызове системной функции read, что встретится раньше. Однако, процесс может обнаружить, что данных, ради которых он возобновил свое выполнение, больше не существует: другие процессы считали данные с терминала и удалили их из списка для неструктурированных вводных данных до того, как первый процесс был запущен вновь. Такая ситуация похожа на ту, которая имеет место, когда из канала считывают данные несколько процессов.
алгоритм terminal_read
{
if (в каноническом символьном списке отсутствуют данные)
{
do while (в списке для неструктурированных вводных данных отсутствует информация)
{
if (терминал открыт с параметром "no delay" (без задержки))
return;
if (терминал в режиме без обработки с использованием таймера и таймер не активен)
предпринять действия к активизации таймера (таблица ответных сигналов);
sleep (до поступления данных с терминала);
}
/* в списке для неструктурированных вводных данных есть информация */
if (терминал в режиме без обработки)
скопировать все данные из списка для неструктурированных вводных данных в канонический список;
else { /* терминал в каноническом режиме */
do while (в списке для неструктурированных вводных данных есть символы)
{
копировать по одному символу из списка для неструктурированных вводных данных в канонический список: выполнить обработку символов стирания и удаления;
if (символ — "возврат каретки" или "конец файла") break
; /* выход из цикла */
}
}
}
do while(в каноническом списке еще есть символы и не исчерпано количество символов, указанное в вызове функции read)
копировать символы из символьных блоков канонического списка в адресное пространство задачи;
}
Рисунок 10.15. Алгоритм чтения с терминала
Обработка символов в направлении ввода и в направлении вывода асимметрична, что видно из наличия двух символьных списков для ввода и одного — для вывода. Строковый интерфейс выводит данные из пространства задачи, обрабатывает их и помещает их в список для хранения выводных данных. Для симметрии следовало бы иметь только один список для вводных данных. Однако, в таком случае потребовалось бы использование программы обработки прерываний для интерпретации символов стирания и удаления, что сделало бы процедуру более сложной и длительной и запретило бы возникновение других прерываний на все критическое время.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|