Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 8)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
4.10 УПРАЖНЕНИЯ
1. В версии V системы UNIX разрешается использовать не более 14 символов на каждую компоненту имени пути поиска. Алгоритм namei отсекает лишние символы в компоненте. Что нужно сделать в файловой системе и в соответствующих алгоритмах, чтобы стали допустимыми имена компонент произвольной длины?
2. Предположим, что пользователь имеет закрытую версию системы UNIX, причем он внес в нее такие изменения, что имя компоненты теперь может состоять из 30 символов; закрытая версия системы обеспечивает тот же способ хранения записей каталогов, как и стандартная операционная система, за исключением того, что записи каталогов имеют длину 32 байта вместо 16. Если пользователь смонтирует закрытую файловую систему в стандартной операционной среде, что произойдет во время работы алгоритма namei, когда процесс обратится к файлу?
*3. Рассмотрим работу алгоритма namei по преобразованию имени пути поиска в идентификатор индекса. В течение всего просмотра ядро проверяет соответствие текущего рабочего индекса индексу каталога. Может ли другой процесс удалить (unlink) каталог? Каким образом ядро предупреждает такие действия? В следующей главе мы вернемся к этой проблеме.
*4. Разработайте структуру каталога, повышающую эффективность поиска имен файлов без использования линейного просмотра. Рассмотрите два способа: хеширование и n-арные деревья.
*5. Разработайте алгоритм сокращения количества просмотров каталога в поисках имени файла, используя запоминание часто употребляемых имен.
*6. В идеальном случае в файловой системе не должно быть свободных индексов с номерами, меньшими, чем номер «запомненного» индекса, используемый алгоритмом ialloc. Как случается, что это утверждение бывает ложным?
7. Суперблок является дисковым блоком и содержит кроме списка свободных блоков и другую информацию, как показано в данной главе. Поэтому список свободных блоков в суперблоке не может содержать больше номеров свободных блоков, чем может поместиться в одном дисковом блоке в связанном списке свободных дисковых блоков. Какое число номеров свободных блоков было бы оптимальным для хранения в одном блоке из связанного списка?
ГЛАВА 5. СИСТЕМНЫЕ ОПЕРАЦИИ ДЛЯ РАБОТЫ С ФАЙЛОВОЙ СИСТЕМОЙ
В последней главе рассматривались внутренние структуры данных для файловой системы и алгоритмы работы с ними. В этой главе речь пойдет о системных функциях для работы с файловой системой с использованием понятий, введенных в предыдущей главе. Рассматриваются системные функции, обеспечивающие обращение к существующим файлам, такие как open, read, write, lseek и close, затем функции создания новых файлов, а именно, creat и mknod, и, наконец, функции для работы с индексом или для передвижения по файловой системе: chdir, chroot, chown, stat и fstat. Исследуются более сложные системные функции: pipe и dup имеют важное значение для реализации каналов в shell'е; mount и umount расширяют видимое для пользователя дерево файловых систем; link и unlink изменяют иерархическую структуру файловой системы. Затем дается представление об абстракциях, связанных с файловой системой, в отношении поддержки различных файловых систем, подчиняющихся стандартным интерфейсам. В последнем разделе главы речь пойдет о сопровождении файловой системы. Глава знакомит с тремя структурами данных ядра: таблицей файлов, в которой каждая запись связана с одним из открытых в системе файлов, таблицей пользовательских дескрипторов файлов, в которой каждая запись связана с файловым дескриптором, известным процессу, и таблицей монтирования, в которой содержится информация по каждой активной файловой системе.
Функции для работы с файловой системой
Возвращают дескрипторы файла
Используют алгоритм namei
Назначают индексы
Работают с атрибутами файла
Ввод-вывод из файла
Работают со структурой файловых систем
Управление деревьями
open creat dup pipe close
open stat creat link chdir chroot chown chmod unlink mknod mount umount
creat mknod link unlink
chown chmod stat
read write lseek
mount umount
chdir chown
Алгоритмы работы с файловой системой на нижнем уровне
namei iget iput bmap
ialloc ifree
alloc free bmap
Алгоритмы работы с буферами
getblk brelse bread breada bwrite
Рисунок 5.1. Функции для работы с файловой системой и их связь с другими алгоритмами
На Рисунке 5.1 показана взаимосвязь между системными функциями и алгоритмами, описанными ранее. Системные функции классифицируются на несколько категорий, хотя некоторые из функций присутствуют более, чем в одной категории:
• Системные функции, возвращающие дескрипторы файлов для использования другими системными функциями;
• Системные функции, использующие алгоритм namei для анализа имени пути поиска;
• Системные функции, назначающие и освобождающие индекс с использованием алгоритмов ialloc и ifree;
• Системные функции, устанавливающие или изменяющие атрибуты файла;
• Системные функции, позволяющие процессу производить ввод-вывод данных с использованием алгоритмов alloc, free и алгоритмов выделения буфера;
• Системные функции, изменяющие структуру файловой системы;
• Системные функции, позволяющие процессу изменять собственное представление о структуре дерева файловой системы.
5.1 OPEN
Вызов системной функции open (открыть файл) — это первый шаг, который должен сделать процесс, чтобы обратиться к данным в файле. Синтаксис вызова функции open:
fd = open(pathname, flags, modes);
где pathname — имя файла, flags указывает режим открытия (например, для чтения или записи), а modes содержит права доступа к файлу в случае, если файл создается. Системная функция open возвращает целое число
, именуемое пользовательским дескриптором файла. Другие операции над файлами, такие как чтение, запись, позиционирование головок чтения-записи, воспроизведение дескриптора файла, установка параметров ввода-вывода, определение статуса файла и закрытие файла, используют значение дескриптора файла, возвращаемое системной функцией open. Ядро просматривает файловую систему в поисках файла по его имени, используя алгоритм namei (см. Рисунок 5.2). Оно проверяет права на открытие файла после того, как обнаружит копию индекса файла в памяти, и выделяет открываемому файлу запись в таблице файлов. Запись таблицы файлов содержит указатель на индекс открытого файла и поле, в котором хранится смещение в байтах от начала файла до места, откуда предполагается начинать выполнение последующих операций чтения или записи. Ядро сбрасывает это смещение в 0 во время открытия файла, имея в виду, что исходная операция чтения или записи по умолчанию будет производиться с начала файла. С другой стороны, процесс может открыть файл в режиме записи в конец, в этом случае ядро устанавливает значение смещения, равное размеру файла. Ядро выделяет запись в личной (закрытой) таблице в адресном пространстве задачи, выделенном процессу (таблица эта называется таблицей пользовательских дескрипторов файлов), и запоминает указатель на эту запись. Указателем выступает дескриптор файла, возвращаемый пользователю. Запись в таблице пользовательских файлов указывает на запись в глобальной таблице файлов.
алгоритм open
входная информация:
имя файла
режим открытия
права доступа (при создании файла)
выходная информация: дескриптор файла
{
превратить имя файла в идентификатор индекса (алгоритм namei);
if (файл не существует или к нему не разрешен доступ) return
(код ошибки);
выделить для индекса запись в таблице файлов, инициализировать счетчик, смещение;
выделить запись в таблице пользовательских дескрипторов файла, установить указатель на запись в таблице файлов;
if (режим открытия подразумевает усечение файла)
освободить все блоки файла (алгоритм free);
снять блокировку (с индекса); /* индекс заблокирован выше, в алгоритме namei */
return (пользовательский дескриптор файла);
}
Рисунок 5.2. Алгоритм открытия файла
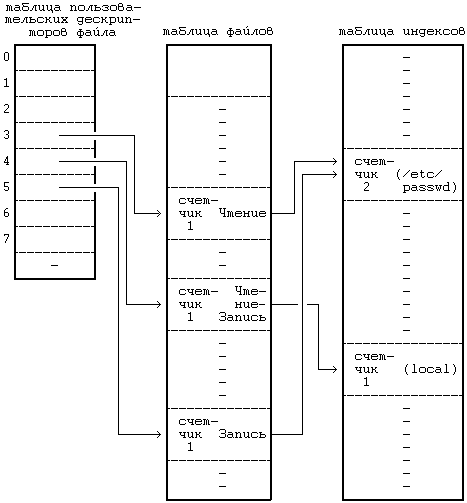
Предположим, что процесс, открывая файл «/etc/passwd» дважды, один раз только для чтения и один раз только для записи, и однажды файл «local» для чтения и для записи
, выполняет следующий набор операторов:
fd1 = open("/etc/passwd", O_RDONLY); fd2 = open("local", O_RDWR); fd3 = open("/etc/passwd", O_WRONLY);
На Рисунке 5.3 показана взаимосвязь между таблицей индексов, таблицей файлов и таблицей пользовательских дескрипторов файла. Каждый вызов функции open возвращает процессу дескриптор файла, а соответствующая запись в таблице пользовательских дескрипторов файла указывает на уникальную запись в таблице файлов ядра, пусть даже один и тот же файл ("/etc/passwd") открывается дважды. Записи в таблице файлов для всех экземпляров одного и того же открытого файла указывают на одну запись в таблице индексов, хранящихся в памяти. Процесс может обращаться к файлу «/etc/passwd» с чтением или записью, но только через дескрипторы файла, имеющие значения 3 и 5 (см. Рисунок). Ядро запоминает разрешение на чтение или запись в файл в строке таблицы файлов, выделенной во время выполнения функции open. Предположим, что второй процесс выполняет следующий набор операторов:
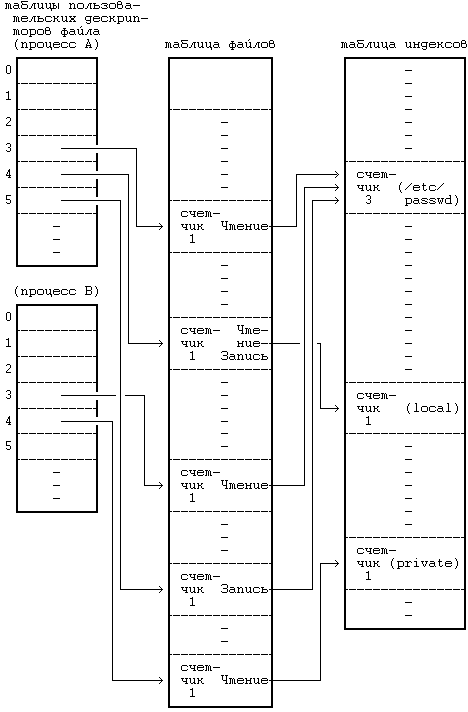
fd1 = open("/etc/passwd", O_RDONLY); fd2 = open("private", O_RDONLY);
Рисунок 5.3. Структуры данных после открытия
На Рисунке 5.4 показана взаимосвязь между соответствующими структурами данных, когда оба процесса (и больше никто) имеют открытые файлы. Снова результатом каждого вызова функции open является выделение уникальной точки входа в таблице пользовательских дескрипторов файла и в таблице файлов ядра, и ядро хранит не более одной записи на каждый файл в таблице индексов, размещенных в памяти. Запись в таблице пользовательских дескрипторов файла по умолчанию хранит смещение в файле до адреса следующей операции ввода-вывода и указывает непосредственно на точку входа в таблице индексов для файла, устраняя необходимость в отдельной таблице файлов ядра. Вышеприведенные примеры показывают взаимосвязь между записями таблицы пользовательских дескрипторов файла и записями в таблице файлов ядра типа «один к одному». Томпсон, однако, отмечает, что им была реализована таблица файлов как отдельная структура, позволяющая совместно использовать один и тот же указатель смещения нескольким пользовательским дескрипторам файла (см. [Thompson 78], стр.1943). В системных функциях dup и fork, рассматриваемых в разделах 5.13 и 7.1, при работе со структурами данных допускается такое совместное использование.
Рисунок 5.4. Структуры данных после того, как два процесса произвели открытие файлов
Первые три пользовательских дескриптора (0, 1 и 2) именуются дескрипторами файлов: стандартного ввода, стандартного вывода и стандартного файла ошибок. Процессы в системе UNIX по договоренности используют дескриптор файла стандартного ввода при чтении вводимой информации, дескриптор файла стандартного вывода при записи выводимой информации и дескриптор стандартного файла ошибок для записи сообщений об ошибках. В операционной системе нет никакого указания на то, что эти дескрипторы файлов являются специальными. Группа пользователей может условиться о том, что файловые дескрипторы, имеющие значения 4, 6 и 11, являются специальными, но более естественно начинать отсчет с 0 (как в языке Си). Принятие соглашения сразу всеми пользовательскими программами облегчит связь между ними при использовании каналов, в чем мы убедимся в дальнейшем, изучая главу 7. Обычно операторский терминал (см. главу 10) служит и в качестве стандартного ввода, и в качестве стандартного вывода и в качестве стандартного устройства вывода сообщений об ошибках.
5.2 READ
Синтаксис вызова системной функции read (читать):
number = read(fd, buffer, count)
где fd — дескриптор файла, возвращаемый функцией open, buffer — адрес структуры данных в пользовательском процессе, где будут размещаться считанные данные в случае успешного завершения выполнения функции read, count — количество байт, которые пользователю нужно прочитать, number — количество фактически прочитанных байт. На Рисунке 5.5 приведен алгоритм read, выполняющий чтение обычного файла. Ядро обращается в таблице файлов к записи, которая соответствует значению пользовательского дескриптора файла, следуя за указателем (см. Рисунок 5.3). Затем оно устанавливает значения нескольких параметров ввода-вывода в адресном пространстве процесса (Рисунок 5.6), тем самым устраняя необходимость в их передаче в качестве параметров функции. В частности, ядро указывает в качестве режима ввода-вывода «чтение», устанавливает флаг, свидетельствующий о том, что ввод-вывод направляется в адресное пространство пользователя, значение поля счетчика байтов приравнивает количеству байт, которые будут прочитаны, устанавливает адрес пользовательского буфера данных и, наконец, значение смещения (из таблицы файлов), равное смещению в байтах внутри файла до места, откуда начинается ввод-вывод. После того, как ядро установит значения параметров ввода-вывода в адресном пространстве процесса, оно обращается к индексу, используя указатель из таблицы файлов, и блокирует его прежде, чем начать чтение из файла.
алгоритм read
входная информация:
пользовательский дескриптор файла
адрес буфера в пользовательском процессе
количество байт, которые нужно прочитать
выходная информация: количество байт, скопированных в пользовательское пространство
{
обратиться к записи в таблице файлов по значению пользовательского дескриптора файла;
проверить доступность файла;
установить параметры в адресном пространстве процесса, указав адрес пользователя, счетчик байтов, параметры ввода-вывода для пользователя;
получить индекс по записи в таблице файлов;
заблокировать индекс;
установить значение смещения в байтах для адресного пространства процесса по значению смещения в таблице файлов;
do (пока значение счетчика байтов не станет удовлетворительным)
{
превратить смещение в файле в номер дискового блока (алгоритм bmap);
вычислить смещение внутри блока и количество байт, которые будут прочитаны;
if (количество байт для чтения == 0) /* попытка чтения конца файла */
break; /* выход из цикла */
прочитать блок (алгоритм breada, если производится чтение с продвижением, и алгоритм bread — в противном случае);
скопировать данные из системного буфера по адресу пользователя;
скорректировать значения полей в адресном пространстве процесса, указывающие смещение в байтах внутри файла, количество прочитанных байт и адрес для передачи в пространство пользователя;
освободить буфер; /* заблокированный в алгоритме bread */
}
разблокировать индекс;
скорректировать значение смещения в таблице файлов для следующей операции чтения;
return (общее число прочитанных байт);
}
Рисунок 5.5. Алгоритм чтения из файла
modeчтение или запись
countколичество байт для чтения или записи
offsetсмещение в байтах внутри файла
addressадрес места, куда будут копироваться данные, в памяти пользователя или ядра
flagотношение адреса к памяти пользователя или к памяти ядра
Рисунок 5.6. Параметры ввода-вывода, хранящиеся в пространстве процесса
Затем в алгоритме начинается цикл, выполняющийся до тех пор, пока операция чтения не будет произведена до конца. Ядро преобразует смещение в байтах внутри файла в номер блока, используя алгоритм bmap, и вычисляет смещение внутри блока до места, откуда следует начать ввод-вывод, а также количество байт, которые будут прочитаны из блока. После считывания блока в буфер, возможно, с продвижением (алгоритмы bread и breada) ядро копирует данные из блока по назначенному адресу в пользовательском процессе. Оно корректирует параметры ввода-вывода в адресном пространстве процесса в соответствии с количеством прочитанных байт, увеличивая значение смещения в байтах внутри файла и адрес места в пользовательском процессе, куда будет доставлена следующая порция данных, и уменьшая число байт, которые необходимо прочитать, чтобы выполнить запрос пользователя. Если запрос пользователя не удовлетворен, ядро повторяет весь цикл, преобразуя смещение в байтах внутри файла в номер блока, считывая блок с диска в системный буфер, копируя данные из буфера в пользовательский процесс, освобождая буфер и корректируя значения параметров ввода-вывода в адресном пространстве процесса. Цикл завершается, либо когда ядро выполнит запрос пользователя полностью, либо когда в файле больше не будет данных, либо если ядро обнаружит ошибку при чтении данных с диска или при копировании данных в пространство пользователя. Ядро корректирует значение смещения в таблице файлов в соответствии с количеством фактически прочитанных байт; поэтому успешное выполнение операций чтения выглядит как последовательное считывание данных из файла. Системная операция lseek (раздел 5.6) устанавливает значение смещения в таблице файлов и изменяет порядок, в котором процесс читает или записывает данные в файле.
#include ‹fcntl.h›
main()
{
int fd;
char lilbuf[20], bigbuf[1024];
fd = open("/etc/passwd", O_RDONLY);
read(fd, lilbuf, 20);
read(fd, bigbuf, 1024);
read(fd, lilbuf, 20);
}
Рисунок 5.7. Пример программы чтения из файла
Рассмотрим программу, приведенную на Рисунке 5.7. Функция open возвращает дескриптор файла, который пользователь засылает в переменную fd и использует в последующих вызовах функции read. Выполняя функцию read, ядро проверяет, правильно ли задан параметр «дескриптор файла», а также был ли файл предварительно открыт процессом для чтения. Оно сохраняет значение адреса пользовательского буфера, количество считываемых байт и начальное смещение в байтах внутри файла (соответственно: lilbuf, 20 и 0), в пространстве процесса. В результате вычислений оказывается, что нулевое значение смещения соответствует нулевому блоку файла, и ядро возвращает точку входа в индекс, соответствующую нулевому блоку. Предполагая, что такой блок существует, ядро считывает полный блок размером 1024 байта в буфер, но по адресу lilbuf копирует только 20 байт. Оно увеличивает смещение внутри пространства процесса на 20 байт и сбрасывает счетчик данных в 0. Поскольку операция read выполнилась, ядро переустанавливает значение смещения в таблице файлов на 20, так что последующие операции чтения из файла с данным дескриптором начнутся с места, расположенного со смещением 20 байт от начала файла, а системная функция возвращает число байт, фактически прочитанных, т. е. 20.
При повторном вызове функции read ядро вновь проверяет корректность указания дескриптора и наличие соответствующего файла, открытого процессом для чтения, поскольку оно никак не может узнать, что запрос пользователя на чтение касается того же самого файла, существование которого было установлено во время последнего вызова функции. Ядро сохраняет в пространстве процесса пользовательский адрес bigbuf, количество байт, которые нужно прочитать процессу (1024), и начальное смещение в файле (20), взятое из таблицы файлов. Ядро преобразует смещение внутри файла в номер дискового блока, как раньше, и считывает блок. Если между вызовами функции read прошло непродолжительное время, есть шансы, что блок находится в буферном кеше. Однако, ядро не может полностью удовлетворить запрос пользователя на чтение за счет содержимого буфера, поскольку только 1004 байта из 1024 для данного запроса находятся в буфере. Поэтому оно копирует оставшиеся 1004 байта из буфера в пользовательскую структуру данных bigbuf и корректирует параметры в пространстве процесса таким образом, чтобы следующий шаг цикла чтения начинался в файле с байта 1024, при этом данные следует копировать по адресу байта 1004 в bigbuf в объеме 20 байт, чтобы удовлетворить запрос на чтение.
Теперь ядро переходит к началу цикла, содержащегося в алгоритме read. Оно преобразует смещение в байтах (1024) в номер логического блока (1), обращается ко второму блоку прямой адресации, номер которого хранится в индексе, и отыскивает точный дисковый блок, из которого будет производиться чтение. Ядро считывает блок из буферного кеша или с диска, если в кеше данный блок отсутствует. Наконец, оно копирует 20 байт из буфера по уточненному адресу в пользовательский процесс. Прежде чем выйти из системной функции, ядро устанавливает значение поля смещения в таблице файлов равным 1044, то есть равным значению смещения в байтах до места, куда будет производиться следующее обращение. В последнем вызове функции read из примера ядро ведет себя, как и в первом обращении к функции, за исключением того, что чтение из файла в данном случае начинается с байта 1044, так как именно это значение будет обнаружено в поле смещения той записи таблицы файлов, которая соответствует указанному дескриптору.
Пример показывает, насколько выгодно для запросов ввода-вывода работать с данными, начинающимися на границах блоков файловой системы и имеющими размер, кратный размеру блока. Это позволяет ядру избегать дополнительных итераций при выполнении цикла в алгоритме read и всех вытекающих последствий, связанных с дополнительными обращениями к индексу в поисках номера блока, который содержит данные, и с конкуренцией за использование буферного пула. Библиотека стандартных модулей ввода-вывода создана таким образом, чтобы скрыть от пользователей размеры буферов ядра; ее использование позволяет избежать потерь производительности, присущих процессам, работающим с небольшими порциями данных, из-за чего их функционирование на уровне файловой системы неэффективно (см. упражнение 5.4).
Выполняя цикл чтения, ядро определяет, является ли файл объектом чтения с продвижением: если процесс считывает последовательно два блока, ядро предполагает, что все очередные операции будут производить последовательное чтение, до тех пор, пока не будет утверждено обратное. На каждом шаге цикла ядро запоминает номер следующего логического блока в копии индекса, хранящейся в памяти, и на следующем шаге сравнивает номер текущего логического блока со значением, запомненным ранее. Если эти номера равны, ядро вычисляет номер физического блока для чтения с продвижением и сохраняет это значение в пространстве процесса для использования в алгоритме breada. Конечно же, пока процесс не считал конец блока, ядро не запустит алгоритм чтения с продвижением для следующего блока.
Обратившись к Рисунку 4.9, вспомним, что номера некоторых блоков в индексе или в блоках косвенной адресации могут иметь нулевое значение, пусть даже номера последующих блоков и ненулевые. Если процесс попытается прочитать данные из такого блока, ядро выполнит запрос, выделяя произвольный буфер в цикле read, очищая его содержимое и копируя данные из него по адресу пользователя. Этот случай не имеет ничего общего с тем случаем, когда процесс обнаруживает конец файла, говорящий о том, что после этого места запись информации никогда не производилась. Обнаружив конец файла, ядро не возвращает процессу никакой информации (см. упражнение 5.1).
Когда процесс вызывает системную функцию read, ядро блокирует индекс на время выполнения вызова. Впоследствии, этот процесс может приостановиться во время чтения из буфера, ассоциированного с данными или с блоками косвенной адресации в индексе. Если еще одному процессу дать возможность вносить изменения в файл в то время, когда первый процесс приостановлен, функция read может возвратить несогласованные данные. Например, процесс может считать из файла несколько блоков; если он приостановился во время чтения первого блока, а второй процесс собирался вести запись в другие блоки, возвращаемые данные будут содержать старые данные вперемешку с новыми. Таким образом, индекс остается заблокированным на все время выполнения вызова функции read для того, чтобы процессы могли иметь целостное видение файла, то есть видение того образа, который был у файла перед вызовом функции.
Ядро может выгружать процесс, ведущий чтение, в режим задачи на время между двумя вызовами функций и планировать запуск других процессов. Так как по окончании выполнения системной функции с индекса снимается блокировка, ничто не мешает другим процессам обращаться к файлу и изменять его содержимое. Со стороны системы было бы несправедливо держать индекс заблокированным все время от момента, когда процесс открыл файл, и до того момента, когда файл будет закрыт этим процессом, поскольку тогда один процесс будет держать все время файл открытым, тем самым не давая другим процессам возможности обратиться к файлу. Если файл имеет имя «/etc/ passwd», то есть является файлом, используемым в процессе регистрации для проверки пользовательского пароля, один пользователь может умышленно (или, возможно, неумышленно) воспрепятствовать регистрации в системе всех остальных пользователей. Чтобы предотвратить возникновение подобных проблем, ядро снимает с индекса блокировку по окончании выполнения каждого вызова системной функции, использующей индекс. Если второй процесс внесет изменения в файл между двумя вызовами функции read, производимыми первым процессом, первый процесс может прочитать непредвиденные данные, однако структуры данных ядра сохранят свою согласованность.
Предположим, к примеру, что ядро выполняет два процесса, конкурирующие между собой (Рисунок 5.8). Если допустить, что оба процесса выполняют операцию open до того, как любой из них вызывает системную функцию read или write, ядро может выполнять функции чтения и записи в любой из шести последовательностей: чтение1, чтение2, запись1, запись2, или чтение1, запись1, чтение2, запись2, или чтение1, запись1, запись2, чтение2 и т. д. Состав информации, считываемой процессом A, зависит от последовательности, в которой система выполняет функции, вызываемые двумя процессами; система не гарантирует, что данные в файле останутся такими же, какими они были после открытия файла. Использование возможности захвата файла и записей (раздел 5.4) позволяет процессу гарантировать сохранение целостности файла после его открытия.
#include ‹fcntl.h›
/* процесс A */
main()
{
int fd;
char buf[512];
fd = open("/etc/passwd", O_RDONLY);
read(fd, buf, sizeof(buf)); /* чтение1 */
read(fd, buf, sizeof(buf)); /* чтение2 */
}
/* процесс B */
main()
{
int fd, i;
char buf[512];
for (i = 0; i ‹ sizeof(buf); i++)
buf[i] = 'a';
fd = open("/etc/passwd", O_WRONLY);
write(fd, buf, sizeof(buf)); /* запись1 */
write(fd, buf, sizeof(buf)); /* запись2 */
}
Рисунок 5.8. Процессы, ведущие чтение и запись файла
Наконец, программа на Рисунке 5.9 показывает, как процесс может открывать файл более одного раза и читать из него, используя разные файловые дескрипторы. Ядро работает со значениями смещений в таблице файлов, ассоциированными с двумя файловыми дескрипторами, независимо, и поэтому массивы buf1 и buf2 будут по завершении выполнения процесса идентичны друг другу при условии, что ни один процесс в это время не производил запись в файл «/etc/passwd».
#include ‹fcntl.h›
main()
{
int fd1, fd2;
char buf1[512], buf2[512];
fd1 = open("/etc/passwd", O_RDONLY);
fd2 = open("/etc/passwd", O_RDONLY);
read(fd1, buf1, sizeof(buf1));
read(fd2, buf2, sizeof(buf2));
}
Рисунок 5.9. Чтение из файла с использованием двух дескрипторов
5.3 WRIТЕ
Синтаксис вызова системной функции write (писать):
number = write(fd, buffer, count);
где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако, если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, используя алгоритм alloc, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индекса. Если смещение в байтах совпадает со смещением для блока косвенной адресации, ядру, возможно, придется выделить несколько блоков для использования их в качестве блоков косвенной адресации и информационных блоков. Индекс блокируется на все время выполнения функции write, так как ядро может изменить индекс, выделяя новые блоки; разрешение другим процессам обращаться к файлу может разрушить индекс, если несколько процессов выделяют блоки одновременно, используя одни и те же значения смещений. Когда запись завершается, ядро корректирует размер файла в индексе, если файл увеличился в размере.
Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации.
Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|