Архитектура операционной системы UNIX
ModernLib.Net / Интернет / Бах Морис / Архитектура операционной системы UNIX - Чтение
(стр. 11)
|
Автор:
|
Бах Морис |
|
Жанр:
|
Интернет |
|
-
Читать книгу полностью
(2,00 Мб)
- Скачать в формате fb2
(764 Кб)
- Скачать в формате doc
(336 Кб)
- Скачать в формате txt
(288 Кб)
- Скачать в формате html
(762 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|
Буферный пул все еще содержит блоки с «отложенной записью», не переписанные на диск, поэтому ядро «вымывает» их из буферного пула. Ядро удаляет записи с разделяемым текстом, которые находятся в таблице областей, но не являются действующими (подробности в главе 7), записывает на диск все недавно скорректированные суперблоки и корректирует дисковые копии всех индексов, которые требуют этого. Казалось, было бы достаточно откорректировать дисковые блоки, суперблок и индексы только для демонтируемой файловой системы, однако в целях сохранения преемственности изменений ядро выполняет аналогичные действия для всей системы в целом. Затем ядро освобождает корневой индекс монтированной файловой системы, удерживаемый с момента первого обращения к нему во время выполнения функции mount, и запускает из драйвера процедуру закрытия устройства, содержащего файловую систему. Впоследствии ядро просматривает буферы в буферном кеше и делает недействительными те из них, в которых находятся блоки демонтируемой файловой системы; в хранении информации из этих блоков в кеше больше нет необходимости. Делая буферы недействительными, ядро вставляет их в начало списка свободных буферов, в то время как блоки с актуальной информацией остаются в буферном кеше. Ядро сбрасывает в индексе системы, где производилось монтирование, флаг «точки монтирования», установленный функцией mount, и освобождает индекс. Пометив запись в таблице монтирования свободной для общего использования, функция umount завершает работу.
алгоритм umount
входная информация: имя специального файла, соответствующего демонтируемой файловой системе
выходная информация: отсутствует
{
if (пользователь не является суперпользователем)
return (ошибку);
получить индекс специального файла (алгоритм namei);
извлечь старший и младший номера демонтируемого устройства;
получить в таблице монтирования запись для демонтируемой системы, исходя из старшего и младшего номеров;
освободить индекс специального файла (алгоритм iput);
удалить из таблицы областей записи с разделяемым текстом для файлов, принадлежащих файловой системе;
/* глава 7ххх */
скорректировать суперблок, индексы, выгрузить буферы на диск;
if (какие-то файлы из файловой системы все еще используются) return (ошибку);
получить из таблицы монтирования корневой индекс монтированной файловой системы;
заблокировать индекс;
освободить индекс (алгоритм iput);
/* iget был при монтировании */
запустить процедуру закрытия для специального устройства;
сделать недействительными (отменить) в пуле буферы из демонтируемой файловой системы;
получить из таблицы монтирования индекс точки монтирования;
заблокировать индекс;
очистить флаг, помечающий индекс как «точку монтирования»;
освободить индекс (алгоритм iput);
/* iget был при монтировании */
освободить буфер, используемый под суперблок;
освободить в таблице монтирования место, занятое ранее;
}
Рисунок 5.27. Алгоритм демонтирования файловой системы
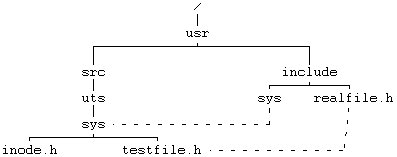
Рисунок 5.28. Файлы в дереве файловой системы, связанные с помощью функции link
5.15 LINК
Системная функция link связывает файл с новым именем в структуре каталогов файловой системы, создавая для существующего индекса новую запись в каталоге. Синтаксис вызова функции link:
link(source file name, target file name);
где source file name — существующее имя файла, а target file name — новое (дополнительное) имя, присваиваемое файлу после выполнения функции link. Файловая система хранит имя пути поиска для каждой связи, имеющейся у файла, и процессы могут обращаться к файлу по любому из этих имен. Ядро не знает, какое из имен файла является его подлинным именем, поэтому имя файла специально не обрабатывается. Например, после выполнения набора функций:
link("/usr/src/uts/sys", "/usr/include/sys");
link("/usr/include/realfile.h", "/usr/src/uts/sys/testfile.h");
на один и тот же файл будут указывать три имени пути поиска: «/usr/src/uts/sys/testfile.h», «/usr/include/sys/testfile.h» и «/usr/include/realfile» (см. Рисунок 5.28).
Ядро позволяет суперпользователю (и только ему) связывать каталоги, упрощая написание программ, требующих пересечения дерева файловой системы. Если бы это было разрешено произвольному пользователю, программам, пересекающим иерархическую структуру файлов, пришлось бы заботиться о том, чтобы не попасть в бесконечный цикл в том случае, если пользователь связал каталог с вершиной, стоящей ниже в иерархии. Предполагается, что суперпользователи более осторожны в указании таких связей. Возможность связывать между собой каталоги должна была поддерживаться в ранних версиях системы, так как эта возможность требуется для реализации команды mkdir, которая создает новый каталог. Включение функции mkdir устраняет необходимость в связывании каталогов.
алгоритм link
входная информация:
существующее имя файла
новое имя файла
выходная информация: отсутствует
{
получить индекс для существующего имени файла (алгоритм namei);
if (у файла слишком много связей или производится связывание каталога без разрешения суперпользователя)
{
освободить индекс (алгоритм iput);
return (ошибку);
}
увеличить значение счетчика связей в индексе;
откорректировать дисковую копию индекса;
снять блокировку с индекса;
получить индекс родительского каталога для включения нового имени файла (алгоритм namei);
if (файл с новым именем уже существует или существующий файл и новый файл находятся в разных файловых системах)
{
отменить корректировку, сделанную выше;
return (ошибку);
}
создать запись в родительском каталоге для файла с новым именем;
включить в нее новое имя и номер индекса существующего файла;
освободить индекс родительского каталога (алгоритм iput);
освободить индекс существующего файла (алгоритм iput);
}
Рисунок 5.29. Алгоритм связывания файлов
На Рисунке 5.29 показан алгоритм функции link. Сначала ядро, используя алгоритм namei, определяет местонахождение индекса исходного файла, увеличивает значение счетчика связей в индексе, корректирует дисковую копию индекса (для обеспечения согласованности) и снимает с индекса блокировку. Затем ядро ищет файл с новым именем; если он существует, функция link завершается неудачно и ядро восстанавливает прежнее значение счетчика связей, измененное ранее. В противном случае ядро находит в родительском каталоге свободную запись для файла с новым именем, записывает в нее новое имя и номер индекса исходного файла и освобождает индекс родительского каталога, используя алгоритм iput. Поскольку файл с новым именем ранее не существовал, освобождать еще какой-нибудь индекс не нужно. Ядро, освобождая индекс исходного файла, делает заключение: счетчик связей в индексе имеет значение, на 1 большее, чем то значение, которое счетчик имел перед вызовом функции, и обращение к файлу теперь может производиться по еще одному имени в файловой системе. Счетчик связей хранит количество записей в каталогах, которые (записи) указывают на файл, и тем самым отличается от счетчика ссылок в индексе. Если по завершении выполнения функции link к файлу нет обращений со стороны других процессов, счетчик ссылок в индексе принимает значение, равное 0, а счетчик связей — значение, большее или равное 2.
Например, выполняя функцию, вызванную как:
link("source", "/dir/target");
ядро обнаруживает индекс для файла «source», увеличивает в нем значение счетчика связей, запоминает номер индекса, скажем 74, и снимает с индекса блокировку. Ядро также находит индекс каталога «dir», являющегося родительским каталогом для файла «target», ищет свободное место в каталоге «dir» и записывает в него имя файла «target» и номер индекса 74. По окончании этих действий оно освобождает индекс файла «source» по алгоритму iput. Если значение счетчика связей файла «source» раньше было равно 1, то теперь оно равно 2.
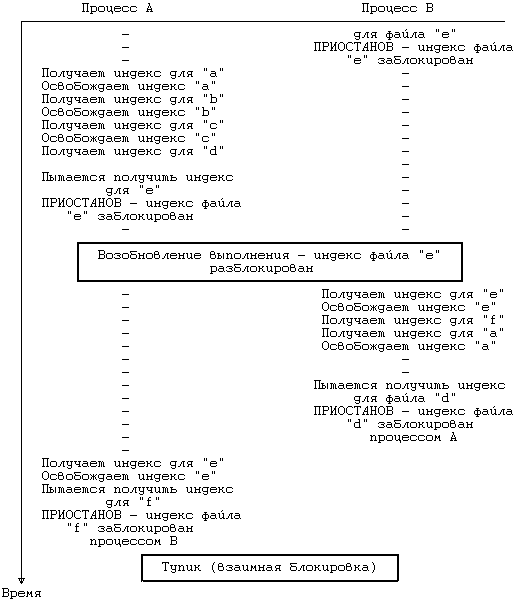
Стоит упомянуть о двух тупиковых ситуациях, явившихся причиной того, что процесс снимает с индекса исходного файла блокировку после увеличения значения счетчика связей. Если бы ядро не снимало с индекса блокировку, два процесса, выполняющие одновременно следующие функции:
процесс A: link("a/b/c/d", "e/f/g");
процесс B: link("e/f", "a/b/c/d/ee");
зашли бы в тупик (взаимная блокировка). Предположим, что процесс A обнаружил индекс файла «a/b/c/d» в тот самый момент, когда процесс B обнаружил индекс файла «e/f». Фраза «в тот же самый момент» означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. (Рисунок 5.30 иллюстрирует стадии выполнения процессов.) Когда же теперь процесс A попытается получить индекс файла «e/f», он приостановит свое выполнение до тех пор, пока индекс файла «f» не освободится. В то же время процесс B пытается получить индекс каталога «a/b/c/d» и приостанавливается в ожидании освобождения индекса файла «d». Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, нужный процессу A. На практике этот классический пример взаимной блокировки невозможен благодаря тому, что ядро освобождает индекс исходного файла после увеличения значения счетчика связей. Поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимная блокировка не происходит.
Следующий пример показывает, как два процесса могут зайти в тупик, если с индекса не была снята блокировка. Одиночный процесс может также заблокировать самого себя. Если он вызывает функцию:
link("a/b/c", "a/b/c/d");
то в начале алгоритма он получает индекс для файла «c»; если бы ядро не снимало бы с индекса блокировку, процесс зашел бы в тупик, запросив индекс «c» при поиске файла «d». Если бы два процесса, или даже один процесс, не могли продолжать свое выполнение из-за взаимной блокировки (или самоблокировки), что в результате произошло бы в системе? Поскольку индексы являются теми ресурсами, которые предоставляются системой за конечное время, получение сигнала не может быть причиной возобновления процессом своей работы (глава 7). Следовательно, система не может выйти из тупика без перезагрузки. Если к файлам, заблокированным процессами, нет обращений со стороны других процессов, взаимная блокировка не затрагивает остальные процессы в системе. Однако, любые процессы, обратившиеся к этим файлам (или обратившиеся к другим файлам через заблокированный каталог), непременно зайдут в тупик. Таким образом, если заблокированы файлы «/bin» или «/usr/bin» (обычные хранилища команд) или файл «/bin/sh» (командный процессор shell), последствия для системы будут гибельными.
5.16 UNLINК
Системная функция unlink удаляет из каталога точку входа для файла. Синтаксис вызова функции unlink:
unlink(pathname);
где pathname указывает имя файла, удаляемое из иерархии каталогов. Если процесс разрывает данную связь файла с каталогом при помощи функции unlink, по указанному в вызове функции имени файл не будет доступен, пока в каталоге не создана еще одна запись с этим именем. Например, при выполнении следующего фрагмента программы: unlink("myfile"); fd = open("myfile", O_RDONLY); функция open завершится неудачно, поскольку к моменту ее выполнения в текущем каталоге больше не будет файла с именем myfile. Если удаляемое имя является последней связью файла с каталогом, ядро в итоге освобождает все информационные блоки файла. Однако, если у файла было несколько связей, он остается все еще доступным под другими именами.
Рисунок 5.30. Взаимная блокировка процессов при выполнении функции link
На Рисунке 5.31 представлен алгоритм функции unlink. Сначала для поиска файла с удаляемой связью ядро использует модификацию алгоритма namei, которая вместо индекса файла возвращает индекс родительского каталога. Ядро обращается к индексу файла в памяти, используя алгоритм iget. (Особый случай, связанный с удалением имени файла».», будет рассмотрен в упражнении). После проверки отсутствия ошибок и (для исполняемых файлов) удаления из таблицы областей записей с неактивным разделяемым текстом (глава 7) ядро стирает имя файла из родительского каталога: сделать значение номера индекса равным 0 достаточно для очистки места, занимаемого именем файла в каталоге. Затем ядро производит синхронную запись каталога на диск, гарантируя тем самым, что под своим прежним именем файл уже не будет доступен, уменьшает значение счетчика связей и с помощью алгоритма iput освобождает в памяти индексы родительского каталога и файла с удаляемой связью. При освобождении в памяти по алгоритму iput индекса файла с удаляемой связью, если значения счетчика ссылок и счетчика связей становятся равными 0, ядро забирает у файла обратно дисковые блоки, которые он занимал. На этот индекс больше не указывает ни одно из файловых имен и индекс неактивен. Для того, чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индекса, освобождая все блоки прямой адресации немедленно (в соответствии с алгоритмом free). Что касается блоков косвенной адресации, ядро освобождает все блоки, появляющиеся на различных уровнях косвенности, рекурсивно, причем в первую очередь освобождаются блоки с меньшим уровнем. Оно обнуляет номера блоков в таблице содержимого индекса и устанавливает размер файла в индексе равным 0. Затем ядро очищает в индексе поле типа файла, указывая тем самым, что индекс свободен, и освобождает индекс по алгоритму ifree. Ядро делает необходимую коррекцию на диске, так как дисковая копия индекса все еще указывает на то, что индекс используется; теперь индекс свободен для назначения другим файлам.
алгоритм unlink
входная информация: имя файла
выходная информация: отсутствует
{
получить родительский индекс для файла с удаляемой связью (алгоритм namei);
/* если в качестве файла выступает текущий каталог… */
if (последней компонентой имени файла является ".")
увеличить значение счетчика ссылок в индексе;
else
получить индекс для файла с удаляемой связью (алгоритм iget);
if (файл является каталогом, но пользователь не является суперпользователем)
{
освободить индексы (алгоритм iput);
return (ошибку);
}
if (файл имеет разделяемый текст и текущее значение счетчика связей равно 1)
удалить записи из таблицы областей;
в родительском каталоге:
обнулить номер индекса для удаляемой связи;
освободить индекс родительского каталога (алгоритм iput);
уменьшить число связей файла;
освободить индекс файла (алгоритм iput);
/* iput проверяет, равно ли число связей 0, если да, освобождает блоки файла (алгоритм free) и освобождает индекс (алгоритм ifree); */
}
Рисунок 5.31. Алгоритм удаления связи файла с каталогом
5.16.1 Целостность файловой системы
Ядро посылает свои записи на диск для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя. Например, когда ядро удаляет имя файла из родительского каталога, оно синхронно переписывает каталог на диск — перед тем, как уничтожить содержимое файла и освободить его индекс. Если система дала сбой до того, как произошло удаление содержимого файла, ущерб файловой системе будет нанесен минимальный: один из индексов будет иметь число связей, на 1 превышающее число записей в каталоге, которые ссылаются на этот индекс, но все остальные имена путей поиска файла останутся допустимыми. Если запись на диск не была сделана синхронно, точка входа в каталог на диске после системного сбоя может указывать на свободный (или переназначенный) индекс. Таким образом, число записей в каталоге на диске, которые ссылаются на индекс, превысило бы значение счетчика ссылок в индексе. В частности, если имя файла было именем последней связи файла, это имя указывало бы на не назначенный индекс. Не вызывает сомнения, что в первом случае ущерб, наносимый системе, менее серьезен и легко устраним (см. раздел 5.18).
Предположим, например, что у файла есть две связи с именами «a» и «b», одна из которых — «a» — разрывается процессом с помощью функции unlink. Если ядро записывает на диске результаты всех своих действий, то оно, очищая точку входа в каталог для файла «a», делает то же самое на диске. Если система дала сбой после завершения записи результатов на диск, число связей у файла «b» будет равно 2, но файл «a» уже не будет существовать, поскольку прежняя запись о нем была очищена перед сбоем системы. Файл «b», таким образом, будет иметь лишнюю связь, но после перезагрузки число связей переустановится и система будет работать надлежащим образом.
Теперь предположим, что ядро записывало на диск результаты своих действий в обратном порядке и система дала сбой: то есть, ядро уменьшило значение счетчика связей для файла «b», сделав его равным 1, записало индекс на диск и дало сбой перед тем, как очистить в каталоге точку входа для файла «a». После перезагрузки системы записи о файлах «a» и «b» в соответствующих каталогах будут существовать, но счетчик связей у того файла, на который они указывают, будет иметь значение 1. Если затем процесс запустит функцию unlink для файла «a», значение счетчика связей станет равным 0, несмотря на то, что файл «b» ссылается на тот же индекс. Если позднее ядро переназначит индекс в результате выполнения функции creat, счетчик связей для нового файла будет иметь значение, равное 1, но на файл будут ссылаться два имени пути поиска. Система не может выправить ситуацию, не прибегая к помощи программ сопровождения (fsck, описанной в разделе 5.18), обращающихся к файловой системе через блочный или строковый интерфейс.
Для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя, ядро освобождает индексы и дисковые блоки также в особом порядке. При удалении содержимого файла и очистке его индекса можно сначала освободить блоки, содержащие данные файла, а можно освободить индекс и заново переписать его. Результат в обоих случаях, как правило, одинаковый, однако, если где-то в середине произойдет системный сбой, они будут различаться. Предположим, что ядро сначала освободило дисковые блоки, принадлежавшие файлу, и дало сбой. После перезагрузки системы индекс все еще содержит ссылки на дисковые блоки, занимаемые файлом прежде и ныне не хранящие относящуюся к файлу информацию. Ядру файл показался бы вполне удовлетворительным, но пользователь при обращении к файлу заметит искажение данных. Эти дисковые блоки к тому же могут быть переназначены другим файлам. Чтобы очистить файловую систему программой fsck, потребовались бы большие усилия. Однако, если система сначала переписала индекс на диск, а потом дала сбой, пользователь не заметит каких-либо искажений в файловой системе после перезагрузки. Информационные блоки, ранее принадлежавшие файлу, станут недоступны для системы, но каких-нибудь явных изменений при этом пользователи не увидят. Программе fsck так же было бы проще забрать назад освободившиеся после удаления связи дисковые блоки, нежели производить очистку, необходимую в первом из рассматриваемых случаев.
5.16.2 Поводы для конкуренции
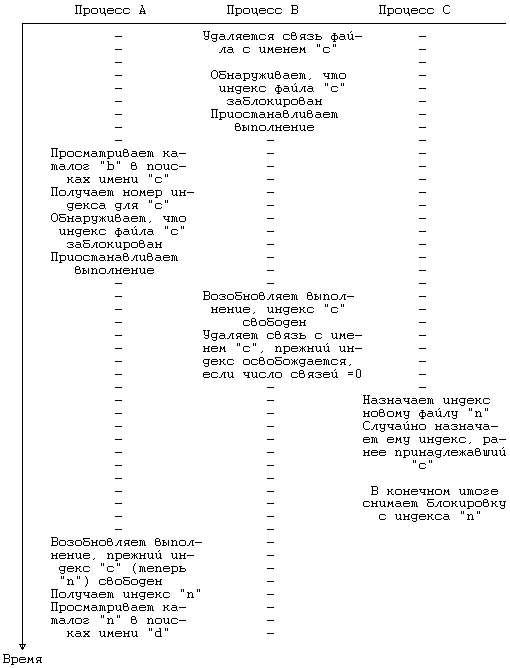
Поводов для конкуренции при выполнении системной функции unlink очень много, особенно при удалении имен каталогов. Команда rmdir удаляет каталог, убедившись предварительно в том, что в каталоге отсутствуют файлы (она считывает каталог и проверяет значения индексов во всех записях каталога на равенство нулю). Но так как команда rmdir запускается на пользовательском уровне, действия по проверке содержимого каталога и удаления каталога выполняются не так уж просто; система должна переключать контекст между выполнением функций read и unlink. Однако, после того, как команда rmdir обнаружила, что каталог пуст, другой процесс может предпринять попытку создать файл в каталоге функцией creat. Избежать этого пользователи могут только путем использования механизма захвата файла и записи. Тем не менее, раз процесс приступил к выполнению функции unlink, никакой другой процесс не может обратиться к файлу с удаляемой связью, поскольку индексы родительского каталога и файла заблокированы. Обратимся еще раз к алгоритму функции link и посмотрим, каким образом система снимает с индекса блокировку до завершения выполнения функции. Если бы другой процесс удалил связь файла пока его индекс свободен, он бы тем самым только уменьшил значение счетчика связей; так как значение счетчика связей было увеличено перед удалением связи, это значение останется положительным. Следовательно, файл не может быть удален и система работает надежно. Эта ситуация аналогична той, когда функция unlink вызывается сразу после завершения выполнения функции link. Другой повод для конкуренции имеет место в том случае, когда один процесс преобразует имя пути поиска файла в индекс файла по алгоритму namei, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени «a/ b/c/d» и приостанавливается во время получения индекса для файла «c». Он может приостановиться при попытке заблокировать индекс или при попытке обратиться к дисковому блоку, где этот индекс хранится (см. алгоритмы iget и bread). Если процессу B нужно удалить связь для каталога с именем «c», он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога «c» и его содержимое по этой связи. Позднее, процесс A попытается обратиться к несуществующему индексу, который уже был удален. Алгоритм namei, проверяющий в первую очередь неравенство значения счетчика связей нулю, сообщит об ошибке. Такой проверки, однако, не всегда достаточно, поскольку можно предположить, что какой-нибудь другой процесс создаст в любом месте файловой системы новый каталог и получит тот индекс, который ранее использовался для «c». Процесс A будет заблуждаться, думая, что он обратился к нужному индексу (см. Рисунок 5.32). Как бы то ни было, система сохраняет свою целостность; самое худшее, что может произойти, это обращение не к тому файлу — с возможным нарушением защиты — но соперничества такого рода на практике довольно редки.
Рисунок 5.32. Соперничество процессов за индекс при выполнении функции unlink
#include ‹sys/types.h›
#include ‹sys/stat.h›
#include ‹fcntl.h›
main(argc, argv)
int argc;
char *argv[];
{
int fd;
char buf[1024];
struct stat statbuf;
if (argc != 2) /* нужен параметр */
exit();
fd = open(argv[1], O_RDONLY);
if (fd == -1) /* open завершилась неудачно */
exit();
if (unlink(argv[1]) == -1) /* удалить связь с только что открытым файлом */
exit();
if (stat(argv[1], &statbuf) == -1) /* узнать состояние файла по имени */
printf("stat %s завершилась неудачно\n", argv[1]); /* как и следовало бы */
else
printf("stat %s завершилась успешно!\n", argv[1]);
if (fstat(fd, &statbuf) == -1) /* узнать состояние файла по идентификатору */
printf("fstat %s сработала неудачно!\n", argv[1]);
else
printf("fstat %s завершилась успешно\n", argv[1]); /* как и следовало бы */
while (read(fd, buf, sizeof(buf)) › 0) /* чтение открытого файла с удаленной связью */
printf("%1024s", buf); /* вывод на печать поля размером 1 Кбайт */
}
Рисунок 5.33. Удаление связи с открытым файлом
Процесс может удалить связь файла в то время, как другому процессу нужно, чтобы файл оставался открытым. (Даже процесс, удаляющий связь, может быть процессом, выполнившим это открытие). Поскольку ядро снимает с индекса блокировку по окончании выполнения функции open, функция unlink завершится успешно. Ядро будет выполнять алгоритм unlink точно так же, как если бы файл не был открыт, и удалит из каталога запись о файле. Теперь по имени удаленной связи к файлу не сможет обратиться никакой другой процесс. Однако, так как системная функция open увеличила значение счетчика ссылок в индексе, ядро не очищает содержимое файла при выполнении алгоритма iput перед завершением функции unlink. Поэтому процесс, открывший файл, может производить над файлом все обычные действия по его дескриптору, включая чтение из файла и запись в файл. Но когда процесс закрывает файл, значение счетчика ссылок в алгоритме iput становится равным 0, и ядро очищает содержимое файла. Короче говоря, процесс, открывший файл, продолжает работу так, как если бы функция unlink не выполнялась, а unlink, в свою очередь, работает так, как если бы файл не был открыт. Другие системные функции также могут продолжать выполняться в процессе, открывшем файл. В приведенном на Рисунке 5.33 примере процесс открывает файл, указанный в качестве параметра, и затем удаляет связь только что открытого файла. Функция stat завершится неудачно, поскольку первоначальное имя после unlink больше не указывает на файл (предполагается, что тем временем никакой другой процесс не создал файл с тем же именем), но функция fstat завершится успешно, так как она выбирает индекс по дескриптору файла. Процесс выполняет цикл, считывая на каждом шаге по 1024 байта и пересылая файл в стандартный вывод. Когда при чтении будет обнаружен конец файла, процесс завершает работу: после завершения процесса файл перестает существовать. Процессы часто создают временные файлы и сразу же удаляют связь с ними; они могут продолжать ввод-вывод в эти файлы, но имена файлов больше не появляются в иерархии каталогов. Если процесс по какой-либо причине завершается аварийно, он не оставляет от временных файлов никакого следа.
5.17 АБСТРАКТНЫЕ ОБРАЩЕНИЯ К ФАЙЛОВЫМ СИСТЕМАМ
Уайнбергером было введено понятие «тип файловой системы» для объяснения механизма работы принадлежавшей ему сетевой файловой системы (см. краткое описание этого механизма в [Killian 84]) и в позднейшей версии системы V поддерживаются основополагающие принципы его схемы. Наличие типа файловой системы дает ядру возможность поддерживать одновременно множество файловых систем, таких как сетевые файловые системы (глава 13) или даже файловые системы из других операционных систем. Процессы пользуются для обращения к файлам обычными функциями системы UNIX, а ядро устанавливает соответствие между общим набором файловых операций и операциями, специфичными для каждого типа файловой системы.
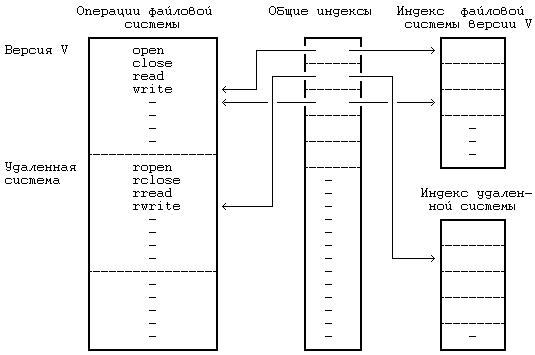
Рисунок 5.34. Индексы для файловых систем различных типов
Индекс выступает интерфейсом между абстрактной файловой системой и отдельной файловой системой. Общая копия индекса в памяти содержит информацию, не зависящую от отдельной файловой системы, а также указатель на частный индекс файловой системы, который уже содержит информацию, специфичную для нее. Частный индекс файловой системы содержит такую информацию, как права доступа и расположение блоков, а общий индекс содержит номер устройства, номер индекса на диске, тип файла, размер, информацию о владельце и счетчик ссылок. Другая частная информация, описывающая отдельную файловую систему, содержится в суперблоке и структуре каталогов. На Рисунке 5.34 изображены таблица общих индексов в памяти и две таблицы частных индексов отдельных файловых систем, одна для структур файловой системы версии V, а другая для индекса удаленной (сетевой) системы. Предполагается, что последний индекс содержит достаточно информации для того, чтобы идентифицировать файл, находящийся в удаленной системе. У файловой системы может отсутствовать структура, подобная индексу; но исходный текст программ отдельной файловой системы позволяет создать объектный код, удовлетворяющий семантическим требованиям файловой системы UNIX и назначающий свой «индекс», который соответствует общему индексу, назначаемому ядром. Файловая система каждого типа имеет некую структуру, в которой хранятся адреса функций, реализующих абстрактные действия. Когда ядру нужно обратиться к файлу, оно вызывает косвенную функцию в зависимости от типа файловой системы и абстрактного действия (см. Рисунок 5.34). Примерами абстрактных действий являются: открытие и закрытие файла, чтение и запись данных, возвращение индекса для компоненты имени файла (подобно namei и iget), освобождение индекса (подобно iput), коррекция индекса, проверка прав доступа, установка атрибутов файла (прав доступа к нему), а также монтирование и демонтирование файловых систем. В главе 13 будет проиллюстрировано использование системных абстракций при рассмотрении распределенной файловой системы.
5.18 СОПРОВОЖДЕНИЕ ФАЙЛОВОЙ СИСТЕМЫ
Ядро поддерживает целостность системы в своей обычной работе. Тем не менее, такие чрезвычайные обстоятельства, как отказ питания, могут привести к фатальному сбою системы, в результате которого содержимое системы утрачивает свою согласованность: большинство данных в файловой системе доступно для использования, но некоторая несогласованность между ними имеет место. Команда fsck проверяет согласованность данных и в случае необходимости вносит в файловую систему исправления. Она обращается к файловой системе через блочный или строковый интерфейс (глава 10) в обход традиционных методов доступа к файлам. В этом разделе рассматриваются некоторые примеры противоречивости данных, которая обнаруживается командой fsck.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37
|
|