 |
|
Популярные авторы:: Борхес Хорхе Луис :: Грин Александр :: Азимов Айзек :: Лондон Джек :: Горький Максим :: Чехов Антон Павлович :: Раззаков Федор :: Толстой Лев Николаевич :: Лем Станислав :: Картленд Барбара Популярные книги:: Справочник по реестру Windows XP :: Дюна (Книги 1-3) :: Ученик чародея :: Солли :: Другой :: Аригато :: Слепой Дей Канет :: Тени Чернобыля :: Магия Калипсо :: Анна Каренина |
Моделирование рассуждений. Опыт анализа мыслительных актовModernLib.Net / Научно-образовательная / Поспелов Дмитрий Александрович / Моделирование рассуждений. Опыт анализа мыслительных актов - Чтение (стр. 8)
На рис. 28, а показана ситуация, связанная с формированием множества с именем «высокие люди». По-видимому, никто не усомнится, что персонаж А к этому множеству принадлежит. Для него ?=1. Столь же очевидно, что персонаж В должен остаться вне формируемого множества. Для него ?=0. Относительно же персонажа С мнения могут разделиться. Одни будут склонны считать, что рост 170 см уже достаточен для отнесения С к высоким людям. Другие же будут придерживаться противоположного мнения. Мнения относительно принадлежности отдельных элементов нечеткому множеству никогда не становятся однозначными. Это произошло бы в единственном случае, когда понятие «высокий рост» было бы регламентировано ГОСТом, обязательным для всех людей, участвующих в нашем мысленном эксперименте. А пока этого нет, каждый волен иметь по этому поводу свое мнение. 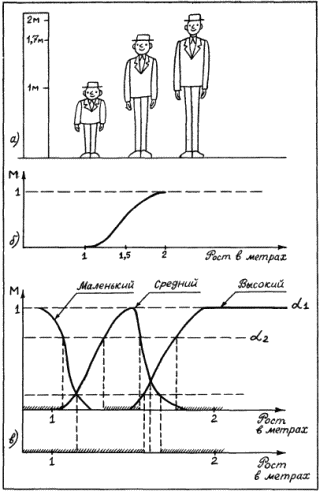
Рис. 28. Если опросить достаточное количество людей, то можно получить усредненные характеристики того, что люди считают высоким ростом. На рис. 28, б показана некоторая функция, называемая функцией принадлежности нечеткого множества. Ее ординаты показывают степень принадлежности людей с тем или иным значением роста, отложенным по горизонтальной оси, к множеству «высокие люди». Конкретные значения ординат этой функции могут меняться при смене тех, кого мы опрашиваем (например, в Юго-Восточной Азии произойдет явное смещение границы высоких людей влево), но качественный вид функции принадлежности будет неизменным. Сначала будет идти нулевая зона, потом начнется рост значений функции, а завершением ее будет опять горизонтальный участок со значением ?=1. «Высокий» – это представитель множества нечетких квантификаторов. Теперь можно сказать, что некоторый квантификатор является нечетким, если для него оказывается возможным построить функцию принадлежности к соответствующему нечеткому множеству. Таких квантификаторов в человеческих рассуждениях немало. Вот несколько примеров из стихотворений Б.Л. Пастернака: «Мне далекое время мерещится, дом на стороне Петербургской», «Огни заката догорали. Распутицей в бору глухом в далекий хутор на Урале тащился человек верхом», «На протяженьи многих зим я помню дни солнцеворота, и каждый был неповторим и повторялся вновь без счета». В них использованы нечеткие квантификаторы, формирующие нечеткие множества с именами «далекое время», «далекое место», «многие зимы». Для них можно построить соответствующие функции принадлежности, использовав, в частности, дополнительную информацию из текста стихотворения или из нормативных знаний о длительности человеческой жизни или об оценках расстояний, преодолеваемых верхом. Введем важное понятие лингвистической шкалы. Лингвистическая шкала – это последовательность нечетких квантификаторов, относящихся к оценке элементов по одному и тому же основанию (расстоянию, длительности, частоте, размерам и т.п.). Примерами лингвистических шкал могут служить шкала расстояний: вплотную, очень близко, близко, ни далеко ни близко, далеко, очень далеко, в бесконечности; или шкала размеров: крошечный, очень маленький, маленький, средний, большой, очень большой, огромный. Особенностью лингвистических шкал является то, что их элементы могут быть отражены в некоторых интервалах значений определенного параметра, измеряемого в натуральных единицах (метрах, часах, квадратных километрах и т.п.). При хорошо устроенной шкале эти интервалы должны покрывать ее плотно без наложений друг на друга. Добиться этого можно путем введения отсечек на графиках функций принадлежности, фиксирующих некоторое их пороговое значение. На рис. 28, в показаны два уровня отсечки ?: ?1 и ?2. Как видно из проекций отсекающих линий на ось абсцисс, ?1 таково, что плотного покрытия интервалами значений параметра «рост» не происходит. Между отрезками, соответствующими нечетким квантификаторам роста «маленький», «средний» и «высокий», образуются пустые отрезки (на рис. 28, в они не помечены косыми линиями). При значении ?2 заполнение почти плотное. Если оставшийся пустым отрезок разделить пополам между двумя соседними, то образуется лингвистическая шкала роста, содержащая три нечетких квантификатора. Величина ? может быть определена как степень уверенности, с которой квантификатор относит значения роста к соответствующим нечетким множествам (в нашем примере это множества «маленькие (в смысле роста) люди», «люди среднего роста» и «высокие люди»). Перейдем теперь к нечетким рассуждениям. Напомним сначала, что один шаг достоверного вывода можно описать в виде схемы следующего вида.  Здесь над чертой стоят те утверждения, истинность которых уже доказана, а ниже черты – утверждения, истинность которых логически следует из верхних утверждений и тех правил вывода, которые используются в данной логической системе. Для большей наглядности рассмотрим один частный, но весьма распространенный случай вывода, с которым мы уже сталкивались, – по правилу модус поненс. Напомним его схему:  Рассмотрим теперь схему вида 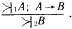 Здесь  Знак вопроса стоит тут на том месте, где должен находиться некоторый нечеткий квантификатор. Интуиция подсказывает нам, что им должен быть квантификатор «часто». Вывод «часто я не выхожу на улицу» выглядит вполне в духе человеческих умозаключений. Рассмотрим еще одну схему: 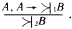 Здесь квантификатор 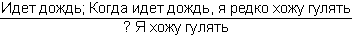 Какой квантификатор надо здесь подставить вместо знака вопроса? Однозначный ответ на этот вопрос вряд ли возможен. В схеме нет информации о частоте события А. А без этой информации трудно сделать сколь-нибудь содержательное заключение. Можно лишь отметить, что если речь идет о сиюминутном решении о прогулке, то положительное решение о ней имеет не слишком большую вероятность. Рассмотрим, наконец, схему 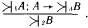 Конкретный случай ее реализации: 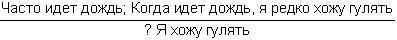 Здесь определение При создании логик, моделирующих нечеткие рассуждения, делалось немало попыток поиска формальных процедур, позволяющих «вычислять» вид В высказываниях «В Ленинграде часто идет дождь» или «Мой ребенок часто болеет» использован один и тот же нечеткий квантификатор «часто». Но каждому ясно, что за ним скрывается неодинаковая фактическая частота. Дожди в Ленинграде, наверное, идут куда чаще, чем болеет ребенок. Один и тот же квантификатор соотносится в этих высказываниях с различными нормами. Норма частоты дождя в Ленинграде иная, чем норма частоты заболевания детей. Если житель Москвы говорит, что он живет недалеко от работы, а житель Ялты говорит то же самое, то за квантификатором «недалеко» у москвича скрывается куда большее расстояние, чем у ялтинца. Таким образом, сами по себе квантификаторы ничего не определяют, кроме положения на лингвистической шкале. В конкретных ситуациях они приобретают некоторый физический смысл, зависящий от этих ситуаций. Поэтому особое значение приобретают исследования, в которых предлагается аппарат, позволяющий делать нечеткие выводы единообразным способом для всего класса однотипных или похожих ситуаций. Известен, например, Принцип ситуативной инвариантности, позволяющий, проведя рассуждение для одной ситуации, преобразовывать его формальным образом для ситуаций, сходных с первоначальной. Этот принцип срабатывает, если имеется лингвистическая шкала. Тогда переход от ситуации к ситуации связан с монотонным смещением всех отрезков, соответствующих квантификаторам шкалы, на определенное число позиций влево или вправо по множеству значений признака, учитываемого данной лингвистической шкалой. Такое смещение позволяет использовать в нечетких рассуждениях элементы, характерные для рассуждений по аналогии. Только вместо диаграммы, отражающей пропорцию Лейбница, в нечетких рассуждениях появляется нечеткая диаграмма моделирования (НДМ), которая имеет вид  В этой диаграмме А обозначает описание некоторой ситуации, а ? – отображение этой ситуации с помощью перехода от качественных параметров, присутствующих в описании А, к их представлению через утверждения с нечеткими квантификаторами. Таким образом, ? есть нечеткая модель ситуации А. Если ситуация А является основанием для перехода с помощью некоторого рассуждения Т к ситуации B, то нам бы хотелось, чтобы существовало нечеткое рассуждение Такая близость рассуждений по аналогии и нечетких рассуждений не случайна. Ибо в основе этих рассуждений лежит идея сходства, похожести. Нечеткая силлогистика Силлогистика Аристотеля совсем недавно вновь стала объектом пристального внимания исследователей. Идеи нечетких рассуждений оказались перенесенными на модусы и фигуры, казавшиеся венцом достоверных рассуждений. Прежде чем изложить эти идеи, опишем одну историю, которую можно было бы назвать «Силлогизм бабушки». «Жара уже спадала, когда Сумбурук и Твидл приехали в один маленький городок – кажется, где-то на юге Франции. Возле автостоянки был бар. Они оставили машину, договорились встретиться в баре вечером и разошлись кто куда. Сумбурук пошел бродить по незнакомым улицам, а Твидл сразу направился в бар: он всегда больше предпочитал сидеть, чем ходить. К вечеру в бар, помахивая бамбуковой тросточкой, вошел Сумбурук. На голове у него был роскошный блестящий цилиндр. – Вырядился, прямо как Макс Линдер. Только полосатых панталон не хватает, – сказал Твидл, когда Сумбурук приблизился к нему. – Красивая тросточка. И цилиндр, кстати, тебе идет. – Хочешь, можешь тоже купить. Они продаются на каждом углу. А кто в цилиндре… – Сумбурук слегка, кончиками пальцев коснувшись цилиндра, сделал незаметный жест, и тросточка в другой его руке завертелась, как пропеллер. – Те, с тросточкой, я заметил, почти всегда, – закончил он и присел за стойку, собираясь заказать себе абсент. Но не успел он это сделать, как с удивлением обнаружил, что рюмка крепкого зеленоватого напитка уже стоит перед ним. – Не удивляйся, – заметил Твидл. Он (Твидл кивнул на бармена) увидел, как ты вертел тросточкой, вот и все. Держу пари, здесь все, кто с тросточкой, пьют исключительно абсент. По крайней мере, за три часа, пока я здесь, он ни разу не ошибся. Да и то сказать, – Твидл еще раз оглядел Сумбурука, – с таким цилиндром и тросточкой можно разве в этом городе пить что-нибудь кроме абсента? Сумбурук сделал глоток и на секунду задумался. – Я, кажется, могу дать ему дельный совет, – сказал он и показал незаметно на бармена. Сумбурук щелкнул пальцами, и бармен поглядел на него. – А тем, кто в цилиндре, вы тоже сразу наливаете абсент? – Да, если в руках еще и тросточка, – ответил бармен. – Но в этом городе все, кто в цилиндре, ходят с тросточкой, разве нет? – Почти все, – поправил бармен. – Вам налить что-нибудь другое? И он с подозрением посмотрел на цилиндр Сумбурука – Все в порядке, – успокоил его Сумбурук. Просто мой вам совет: тому, кто в цилиндре, с тросточкой он или без тросточки, можете, не спрашивая, тоже смело наливать абсент – не ошибетесь никогда. – Не ошибусь? – переспросил бармен. – Никогда? Вы уверены? – Ну, почти никогда. Еще Аристотель говорил, если почти все, кто носит цилиндр, ходят с тросточкой, и почти все, кто ходит с тросточкой, пьют только абсент, то почти все, кто носит цилиндр, тоже пьют только абсент. Согласны? – спросил Сумбурук. Он когда-то изучал логику и немного гордился этим[8]. – Вы не правы, – к удивлению друзей вежливо, но твердо возразил бармен. – Еще моя покойная бабушка, помню, любила повторять, если почти все, кто носит цилиндр, ходят с тросточкой, и вместе с тем почти все, кто ходит с тросточкой, пьют только абсент, то наверняка можно сказать только одно: из тех, кто носит цилиндр, многие пьют только абсент. Многие – да, согласен. А сказать "почти все" – это неверно. Сумбурук никогда не был формалистом, – скорее, напротив. Но тут, немного задетый, он (с кем не бывает!) задал вопрос, который вряд ли пришел бы в голову Максу Линдеру: – А что значит "многие"? – Да-да, – поддержал его Твидл, – "многие" это что, больше 30 %, больше 50 % или, может, больше 90 %? – Ну, 90 % это вряд ли, – сказал бармен, слегка ошарашенный таким обилием неизвестно откуда взявшихся цифр. – Во всяком случае "многие" это не то же самое, что "почти все". В нашем городе вкусы меняются медленно, и поверьте, я на собственном опыте знаю: моя бабушка была права. – По всему выходит, что ваша бабушка умнее Аристотеля, – заметил Твидл. Бармен пожал плечами. – Я, простите, ничего не знаю о человеке по имени Аристотель. Он, наверное, грек, а я наполовину француз. Но могу сказать одно, – тут он взял бутылку абсента и налил нашим друзьям еще по рюмке, – моя бабушка была очень умная и добропорядочная женщина». Постараемся разобраться в силлогизме бабушки. Введем ряд обозначений: а – количество людей, которые ходят в цилиндре; b – количество людей, которые ходят с тросточкой; с – количество людей, которые пьют только абсент; Р(b/а) – доля тех, кто ходит с тросточкой среди тех, кто носит цилиндр; Р(c/b) – доля тех, кто пьет только абсент, среди тех, кто ходит с тросточкой; Р(c/a) – доля тех, кто пьет только абсент, среди тех, кто ходит в цилиндре; Р(а) – доля тех жителей города, которые ходят в цилиндре, от всех жителей города; Р(b) – доля тех, кто ходит с тросточкой, от всех жителей города; Р(c) – доля тех, кто пьет только абсент, от всех жителей города. Получение всей этой информации требует некоторого статистического обследования жителей города и их привычек. Результаты такого обследования могут быть сведены в таблицу сопряженности (табл. 5). Таблица 5  В этой таблице z3, например, доля жителей торода, которые ходят в цилиндре и с тросточкой, но не пьют абсента. Аналогичным образом интерпретируются и остальные ее элементы. Значения z1, удовлетворяют ряду соотношений. 1. z1+z2+z3+z4+z5+z6+z7+z8=1. Это соотношение вытекает из нормировки, так как zi – доли. 2. Восемь ограничений вида zi?0, вытекающие из смысла zi, i=1,2,…,8. 3. Предположим, что в городе множества жителей, которые носят цилиндр, ходят с тросточкой и пьют только абсент, не являются пустыми. Это означает, что должны выполняться следующие неравенства: 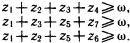 Значение ? выбрано так, чтобы все эти три неравенства были справедливы. 4. Еще два неравенства связаны с тем, что величины Р(b/а) и Р(c/b), входящие в посылку силлогизма бабушки, должны удовлетворять ограничениям P(b/a)?? и P(c/b)??, где ? подобрано таким образом, чтобы оба неравенства выполнялись. Если условные частоты выразить через элементы таблицы сопряженности, то можно получить еще два неравенства:  В этих ограничениях два параметра: ? и ?. Варьируя их, можно вводить различные нечеткие квантификаторы в силлогизм типа силлогизма бабушки или силлогизма Сумбурука. Дадим некоторые необходимые пояснения к приведенной системе. Посылки силлогизма бабушки, как его сформулировал бармен, звучат так: «Из тех, кто носит цилиндр, почти все ходят с тросточкой» И «Из тех, кто ходит с тросточкой, почти все пьют только абсент». Заглавная буква И отделяет один член посылки от другого. Первый член посылки говорит о том, что P(b/a) есть нечеткий квантификатор «почти все», а второй член посылки содержит аналогичное утверждение относительно P(c/b). Если считать, что нечеткому квантификатору «почти все» на лингвистической шкале соответствует некоторый отрезок, то он имеет вид [?,1], где ?>0. Именно в этом смысл двух последних неравенств. В силлогизме бабушки дается оценка нечеткого квантификатора, соответствующего Р(с/а). Бабушка считает, что Р(с/а) соответствует квантификатор «многие». Сумбурук же считает, что Р(с/а) соответствует квантификатор «почти все». Значит, бабушка предполагает, что Р(с/а) на лингвистической шкале соответствует полуинтервал [?,?] и ?>0, а Сумбурук уверен, что это отрезок [?,1]. В этом и состоит их несогласие. Их спор происходит в условиях некоторого «контекста». Этот контекст определяется величинами Р(а), Р(b) и Р(с), характерными для данного городка. В наших ограничениях контекст определяется параметром ?. Силлогизмы бабушки и Сумбурука – это формальный вывод вида А Как разрешить спор? Выход один. Надо задать значения ?, ? и ? и свести проблему к решению типовой задачи линейного целочисленного программирования, которая формулируется следующим образом. Найти целочисленные значения zi?0 (i=1,2,…,8), такие, что удовлетворяются шесть вышеприведенных неравенств, и такие, что минимум функции 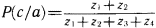 достигает своего максимума. Если задача решена и минимум Р(с/а) есть ? и этот минимум удовлетворяет неравенству ???, то верен силлогизм бабушки. А если ???<?, то верен силлогизм Сумбурука. Если же ?<?, то и бабушка, и Сумбурук ошиблись. Их силлогизмы будут ложными. Значит, все зависит от того, как определены ?, ? и ?. Пусть для определения этих значений мы опросили четырех людей Ч1, Ч2, Ч3 и Ч4. Их ответы сведены в табл. 6. Таблица 6  Интерпретация чисел в таблице следующая. Опрашиваемый считает, что можно говорить «почти все», когда явление это встречается не реже, чем в 95 случаях из 100. Аналогично интерпретируются и остальные элементы таблицы. В первом столбце стоят значения ?, во втором ?, а в третьем ?. Каждая строка может быть использована для решения задачи линейного программирования, которую мы сформулировали. Если решить возникающие четыре задачи, то выяснится, что силлогизм бабушки оказывается истинным во всех случаях, кроме третьего. В третьем случае прав Сумбурук, а бабушка ошибается. Из сказанного ясно, что при исследовании нечетких силлогизмов (или D-cиллогизмов, как их принято называть) необходимо анализировать области в пространстве параметров ?, ?, ?, в которых будут истинны или ложны те или иные силлогизмы. В частности, для силлогизма бабушки доказывается следующее утверждение, которое естественно было бы назвать Теоремой бармена: «Силлогизм бабушки истинен только в тех точках параметрического пространства, в которых выполняется соотношение ??max[0,2?1/?, 1?(1??)(?+1/?)]». Но, наверное, ни бармен, ни Сумбурук не смогли бы так четко сформулировать нужный для разрешения их спора результат. Рассуждая о споре в баре, мы незаметно сформулировали метод формального поиска оценок нечетких квантификаторов в схемах рассуждений. Ведь если вернуться к схемам предшествующего раздела, то становится ясным, что метод решения силлогизма бабушки вполне пригоден для поиска Коллекция схем Среди схем правдоподобных рассуждений встречаются не только те, которые мы расссмотрели и которые основаны на индуктивном выводе, аналогиях или нечетких квантификаторах. Многими исследователями предлагались и иные схемы. Их количество достаточно велико и продолжает расти. В этом разделе мы приведем (практически без комментариев) примеры схем, в основе которых лежат соображения, связанные с теорией вероятностей и аналогией, а также несколько схем, типичных для теории возможностей, активно развивающейся в последние годы ветви теории рассуждений. Рассмотрим прежде всего схемы рассуждений, опирающиеся на свойства вероятностей, т.е. вероятностные схемы рассуждений.  Рассуждением, основанным, например, на схеме 2, может служить следующее: «С вероятностью, большей 0,7, при переохлаждении двигателя он не заводится с помощью стартера. Вероятность того, что он не заводится, меньше 0,5. Следовательно, вероятность того, что двигатель переохлажден, меньше min(1,1–0,7+0,5), т.е. меньше 0,8». Так же нетрудно придумать примеры и для других схем вероятностных рассуждений. Рассмотрим две схемы рассуждения с учетом необходимых условий.  Значения q и r необходимости в этих схемах могут оцениваться в каких-то специальных единицах. Можно считать, например, что имеется лингвистическая шкала нечетких квантификаторов необходимости. Тогда q и r будут соответствовать некоторые интервалы или усредненные характеристики этих интервалов. В качестве примера рассуждения с учетом необходимых условий в соответствии со схемой 5 приведем следующее рассуждение: «Если у меня будет дача, то необходимо будет купить велосипед. Дача мне крайне необходима. Тогда покупка велосипеда для меня необходима». Рассмотрим еще две схемы, в которых наряду с необходимостью учитывается возможность некоторых фактов, явлений или действий. Подобные схемы (как и две предшествующие) характерны для упоминавшейся теории возможностей.  Пример рассуждения, основанного на схеме 7: «Когда поднимается температура в реакторе, чрезвычайно необходимо понизить в нем давление. Возможность повышения температуры в реакторе высока. Следовательно, возможность того, что надо будет снижать давление в реакторе, либо больше нуля, либо больше той возможности, которая приписана событию повышения температуры». Альтернативный характер этого рассуждения обусловлен тем, что q и r при проведении его не были оценены количественно. Это не позволяет сделать окончательный альтернативный вывод в следствии. Завершим раздел еще тремя схемами рассуждений, в которых учитывается возможная взаимосвязь А и В, а также некоторые соображения из рассуждений по аналогии.  Каждый, кого интересуют схемы правдоподобных рассуждений, может без труда увеличить нашу коллекцию, например, заимствовав их из книги Д. Пойи, приведенной в списке литературы. Нам же необходимо двигаться дальше к тем человеческим схемам рассуждений, в которых активно используются знания, хранящиеся в его памяти, т.е. к рассуждениям, на которые опирается интеллектуальная деятельность человека и ее моделирование в современных интеллектуальных системах. Глава пятая. ВЫВОД В БАЗЕ ЗНАНИЙ Приходится порой простые мысли доказывать всерьез, как теоремы. Что такое интеллектуальная система Проблема моделирования человеческих рассуждений стала чрезвычайно актуальной в конце 70-х годов, когда в области искусственного интеллекта появились практически интересные системы. В последующие несколько лет возникла новая отрасль индустрии – производство интеллектуальных систем. Причин скачкообразного развития работ по созданию систем искусственного интеллекта было несколько. Главнейшими из них можно считать три: необходимость создания ЭВМ пятого поколения, переход к роботизированным производствам и появление экспертных систем. Как известно, ЭВМ пятого поколения отличаются от машин предыдущих поколений тем, что в них встроены функции программиста. По словесному заданию задачи, сформулированному на ограниченном профессиональном языке, эти ЭВМ способны сами построить необходимую рабочую программу (синтезировать ее из отдельных модулей, хранящихся в памяти ЭВМ) и выполнить ее. Для этого в состав ЭВМ должна входить база знаний, в которой хранится информация о закономерностях, присущих данной проблемной области, и методах решения характерных для нее задач. Кроме того, в состав ЭВМ должен входить специальный блок – решатель, в который встроены процедуры, подобные логическому выводу. С помощью решателя на основании сведений из базы знаний автоматически синтезируются нужные для пользователя программы. На рис. 29 приведена общая структура ЭВМ пятого поколения. Отметим, что процессор, показанный на рисунке, – это обычное арифметическое устройство с необходимой оперативной памятью, а внешняя память служит для хранения данных, нужных для решения задач. Таким образом, база знаний является новым специфическим блоком (как и система общения и решатель) в структуре ЭВМ пятого поколения. 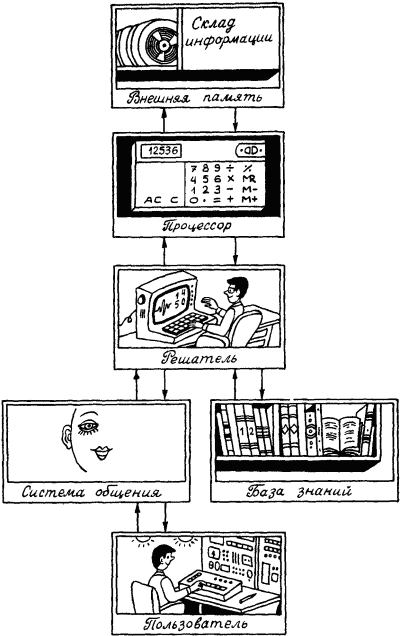
Рис. 29. В роботизированных производствах используются роботы третьего поколения. Они должны быть достаточно автономны в своих действиях и уметь выполнять необходимый набор операций в динамически изменяющихся условиях производства. Это означает, что они не могут довольствоваться набором встроенных в них программ жесткого поведения. Интеллектуальный уровень таких роботов должен быть достаточно высоким. В их систему управления необходимо включить специальный блок – планировщик, задачей которого является составление программы действий робота в тех реальных условиях окружающей среды, которые в данный момент наблюдаются рецепторной системой робота. Для планирования целесообразной деятельности робот третьего поколения должен обладать определенными знаниями о свойствах окружающей среды и методах достижения целей в ней. Эти знания хранятся в его базе знаний, показанной в общей структуре робота на рис. 30. Глядя на этот рисунок, легко установить аналогии со схемой, показанной на предыдущем рисунке. В ЭВМ пятого поколения и в роботах третьего поколения осуществляется планирование будущей деятельности: автоматический синтез программы, выполняемый решателем, и программа деятельности, создаваемая планировщиком. Оба блока работают на основе знаний, хранящихся в базе знаний. 
Рис. 30. Экспертные системы, структура которых показана на рис. 31, также содержат базу знаний и логический блок, функции которого похожи на функции решателя и планировщика. Задача логического блока состоит в поиске вывода, ответа на входное сообщение, поступившее в систему. В базе знаний хранится необходимая информация о проблемной области, в которой работает пользователь. Его запросы поступают на профессиональном ограниченном естественном языке. В системе общения они преобразуются во внутреннее представление, с которым работает логический блок. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 |
|||||||
 1 – нечеткий квантификатор, показывающий, что истинность А не является абсолютной. Конечно, вывод, который следует из подобной посылки, также не может быть достоверным. Степень его правдоподобности оценивается нечетким квантификатором
1 – нечеткий квантификатор, показывающий, что истинность А не является абсолютной. Конечно, вывод, который следует из подобной посылки, также не может быть достоверным. Степень его правдоподобности оценивается нечетким квантификатором  , с помощью которого из ? получалось бы описание
, с помощью которого из ? получалось бы описание  , и между А и ?, а также между В и
, и между А и ?, а также между В и  В. Здесь А – посылка силлогизма, общая для бабушки и Сумбурука, а В – заключение, которое у бабушки имеет вид «Р(с/а) есть нечеткий квантификатор «многие»», а у Сумбурука – вид «Р/(c/a) есть нечеткий квантификатор «почти все»». Вывод: силлогизм происходит в условиях контекстных ограничений, характеризуемых параметром ?.
В. Здесь А – посылка силлогизма, общая для бабушки и Сумбурука, а В – заключение, которое у бабушки имеет вид «Р(с/а) есть нечеткий квантификатор «многие»», а у Сумбурука – вид «Р/(c/a) есть нечеткий квантификатор «почти все»». Вывод: силлогизм происходит в условиях контекстных ограничений, характеризуемых параметром ?.