 |
|
Популярные авторы:: Борхес Хорхе Луис :: Грин Александр :: Азимов Айзек :: Лондон Джек :: Горький Максим :: Чехов Антон Павлович :: Раззаков Федор :: Толстой Лев Николаевич :: Лем Станислав :: Картленд Барбара Популярные книги:: Справочник по реестру Windows XP :: Дюна (Книги 1-3) :: Ученик чародея :: Солли :: Другой :: Аригато :: Слепой Дей Канет :: Тени Чернобыля :: Магия Калипсо :: Анна Каренина |
Моделирование рассуждений. Опыт анализа мыслительных актовModernLib.Net / Научно-образовательная / Поспелов Дмитрий Александрович / Моделирование рассуждений. Опыт анализа мыслительных актов - Чтение (стр. 7)
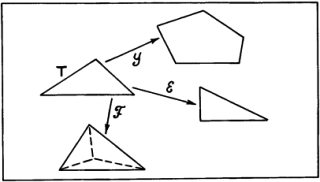
Рис. 24. Первая попытка формализовать понятие рассуждения по аналогии была предпринята Лейбницем. В своем сочинении «Фрагменты логики» он ввел понятие пропорции для отношения аналогии. Пропорция Лейбница формулируется следующим образом: «Вещь А так относится к вещи В, как вещь А’ к вещи В’». Обычно пропорцию Лейбница представляют в виде диаграммы: 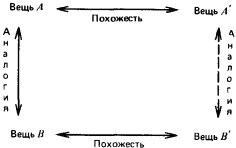 Для иллюстрации того, как может быть использована диаграмма Лейбница, рассмотрим семантическое пространство Осгуда. Это пространство, которое американский психолог Чарльз Осгуд строил экспериментально, проводя опыты с людьми, должно было, по его мнению, характеризовать организацию размещения информации в памяти человека. Мы не будем здесь останавливаться на способе его построения. В комментарии к данному разделу имеется некоторая информация по этому вопросу, а в библиографии заинтересовавшиеся читатели могут найти нужные работы. Скажем только, что упрощенное пространство Осгуда является обычным трехмерным евклидовым пространством. Близость по метрике этого пространства характеризует семантическую близость понятий, фактов и утверждений, а рассуждения, проведенные в пространстве относительно группы элементов, могут проецироваться по аналогии на группы, состоящие из семантически близких элементов. Проиллюстрируем эту мысль, взяв «кусок» пространства Осгуда, относящийся к понятиям, используемым для указания родства. То, что они в семантическом пространстве расположены компактно, было доказано экспериментально. Этот «кусок» пространства Осгуда показан на рис. 25. Для удобства введена система координат и сделано такое преобразование, чтобы все точки, соответствующие интересующим нас понятиям, оказались лежащими в вершинах единичного куба (правомочность такого преобразования в пространстве Осгуда мы тут не обсуждаем). 
Рис. 25. Пусть даны три элемента пропорции Лейбница А, А’ и В. И необходимо узнать элемент В’. Для рассматриваемого примера примем следующий способ нахождения координат понятия В’: b’i=bi+а’i–аi где i=1,2,3. Пусть, например, нас интересует пропорция Сын:Дочь=Дядя:? Для определения неизвестного члена пропорции произведем необходимые вычисления, используя координаты понятий, отмеченные на рис. 25. Получим b’1=0+1–0=1; b’2=1+0–0=1; b’3=0+1–0=1. Таким образом, понятие В’ имеет координаты (1,1,1). Этим координатам соответствует понятие «Тетя». Для дальнейшего необходимо уточнить понятия «похожесть» и «аналогия», использованные в диаграмме для пропорции Лейбница, и придать им по возможности строгий смысл. Сделать это можно следующим образом. Выберем некоторый алгебраический язык для описания A и В, который обозначим Чтобы все сказанное стало понятнее, рассмотрим конкретный пример. На рис. 26 показана серия изображений, соответствующая пропорции Лейбница, в которой, как всегда, надо восстановить недостающее звено, т.е. осуществить (если это возможно) вывод по аналогии. Для описания изображений введем языки 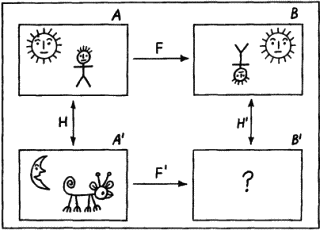
Рис. 26. Введем теперь элементы языка Рассмотренная процедура носит общий характер. Можно строго доказать, что если в пропорции Лейбница А, А’ и В описаны с помощью алгебраического языка, использующего лишь двуместные отношения, задан характер преобразований F и установлено взаимно однозначное соответствие между Заметим, что из этого утверждения вытекает, что необходимым условием для возможности рассуждений по аналогии с использованием пропорции Лейбница служит требование коммутативности ее диаграммы. Требование коммутативности диаграммы означает, что описание В’, полученное из A с помощью F и взаимно однозначного соответствия H’, ничем не отличается от описания В’, полученного из A с помощью взаимно однозначного соответствия H и последующего применения к этому результату преобразования F’. С требованием коммутативности диаграмм мы еще столкнемся в последующих разделах этой главы. Несмотря на все сказанное, полное описание модели рассуждений по аналогии всё еще не получено, так как пропорция Лейбница явно не исчерпывает всех случаев рассуждений подобного типа. Да и в случае, когда мы имеем дело действительно с пропорцией Лейбница, остаются нерешенными по крайней мере два вопроса: как построить языки  Рис. 27. Готовы ли мы признать описанные две ситуации аналогичными? И должен ли Тристан действовать так же, как Ромео? Из соответствующих литературных произведений мы знаем, что развитие ситуации А было таково, что оно привело к совместной смерти Ромео и Джульетты. А Тристан и Изольда имели другую судьбу. Почему это произошло? И можно было бы это формально установить в процессе сравнения ситуаций А и А’? Ведь во второй ситуации имелся король Марк, а различное число отношений заведомо не позволяло установить взаимно однозначное отношение между их описаниями. Но может быть вместо изоморфизма (т.е. взаимно однозначного отношения) для Этот вопрос пока остается без ответа. Поэтому ограничимся лишь тем, что для рассуждений по аналогии можно считать твердо установленным. В следующем разделе попытаемся объединить то, что нам уже известно об индуктивном методе Милля и рассуждениях по аналогии. ДСМ-метод Сокращение ДСМ, вынесенное в название метода, означает Джон Стюарт Милль. Оно показывает, что метод поиска закономерностей по множествам положительных и отрицательных примеров, к описанию которого мы переходим, опирается на методы индукции, предложенные этим ученым. Их реализация в виде комплекса действующих программ на ЭВМ выполнена современными исследователями. Введем три множества: причин А={а1,а2,…,аp}, следствий B={b1,b2,…,bm} и оценок Q={q1,q2,…,ql}. Выражение вида аi Пусть мы вдруг оказались в стране, где до этого нам не приходилось бывать. Выйдя из гостиницы, мы увидели, что у подъезда стоит такси, выкрашенное в ярко-желтый цвет. Через некоторое время рядом останавливается еще одно такси такого же цвета. В нашей голове возникает положительная гипотеза вида «В этой стране, если автомобиль выполняет роль такси, то цвет его будет желтым». Оценка достоверности этой гипотезы при двух наблюдениях будет невелика. Но если во время прогулки по улицам города мы увидим, что такси окрашены в тот же желтый цвет, то оценка выдвинутой при выходе из гостиницы гипотезы будет все время возрастать. Станет ли она когда-нибудь равной единице? Если после недельного пребывания в стране наша гипотеза будет подтверждаться лишь положительными примерами, то на родине, рассказывая знакомым и друзьям о своих впечатлениях, связанных с поездкой, мы вполне можем заявить: «А такси у них покрашены в ярко-желтый цвет, что очень удобно – сразу можно найти его, когда нужно». Значит ли это, что гипотеза о цвете такси приобрела оценку достоверности, равную 1? Можно ввести два типа истинности: эмпирическую истину и теоретическую истину. В нашем примере высказыванию о цвете такси мы, конечно, приписываем эмпирическую истину. Просто все наши наблюдения были в пользу данной гипотезы. Но мы вполне можем допустить, что есть небольшое количество такси иного цвета. Они ни разу не попадались нам на глаза. Совсем другое положение будет в том случае, когда в путеводителе, обнаруженном в гостинице, будет сказано, что закон данной страны запрещает окрашивать такси в какие-либо другие цвета, кроме желтого. При такой информации высказывание о желтом цвете такси будет оценено как теоретическая истина. На этом простом примере видна разница между дедуктивным и индуктивным умозаключением. При использовании информации из путеводителя о цвете такси вы уже не нуждаетесь в эксперименте. Полученное знание носит общий характер. В каждом конкретном случае (например, при поиске такси) его можно механически применять, фиксируя цвета проходящих машин. Никакого нового знания при решении конкретных задач, связанного с цветом такси, получить нельзя. При получении же информации из наблюдений формируется новое знание, которого раньше не было. Гипотеза о цвете такси в данной стране – это новая информация. Таким образом, индуктивное рассуждение способно порождать новые знания. В этом смысле оно куда более «интеллектуально», чем дедуктивное рассуждение. Достижение эмпирической истины (а только такая истина и возможна при индуктивных рассуждениях) вполне возможно. Для этого достаточно некоторого множества положительных примеров при полном отсутствии отрицательных примеров, опровергающих выдвинутую гипотезу. А число необходимых положительных примеров, необходимых для того, чтобы считать гипотезу эмпирически истинной, может быть разным в различных обстоятельствах и у разных людей. Недаром же все представители рода человеческого делятся на тех, кто готов верить в нечто всего по одному примеру, и тех, кто подобно евангельскому Фоме никогда не может уверовать до конца даже в самые очевидные для остальных истины. Рассмотренный пример иллюстрирует процесс оценивания степени достоверности гипотезы, когда предполагаемая причина (в нашем случае – принадлежность автомашины к множеству такси) уже выделена из множества возможных причин. В ДСМ-методе формализован не только этот этап, но и предшествующий ему этап нахождения кандидата в причины, которая могла бы вызвать интересующее нас следствие. В примере это соответствовало бы следующему. Наблюдая на улицах города потоки автотранспорта и выделяя среди автомашин ярко-желтые, надо «сообразить», что желтыми являются только такси. Причины могут быть различными по типу. Наиболее редкими являются необходимые и достаточные причины. Если аi – причина такого типа, то bj происходит всегда, и если bj произошло, то наверняка было аi. Примерами такой «жесткой» связи двух явлений может служить падение тела, если для него отсутствует опора. Чаще встречаются достаточные причины, всегда вызывающие появление bj. Но появление bj не служит стопроцентным обоснованием того, что до этого было аi. Следствие bj могло быть вызвано и какими-то другими достаточными причинами. Если, например, ваш друг не пришел в условленное место и в условленное время на свидание, то, возможно, он заболел, ибо болезнь – достаточная причина для отказа от свидания, но весьма вероятно, что были какие-то другие причины нарушения им своего обещания. Дополнительные причины обладают тем свойством, что их наличие не вызывает следствия bj. Для того чтобы bj появилось, нужен вполне определенный набор дополнительных причин, который выступает в роли обобщенной достаточной причины появления bj. Легко себе представить такой набор причин, который приводит к попаданию мяча в сетку ворот при игре в футбол. Перечисление и обсуждение дополнительных причин, приведших к голу, – знакомое занятие для каждого истинного любителя футбола. Среди дополнительных причин могут быть необходимые дополнительные причины. Их вхождение в набор, образующий обобщенную достаточную причину, обязательно для того, чтобы bj реализовалось. Остальные дополнительные причины можно назвать факультативными. В окончательный набор могут входить те или иные комбинации факультативных причин. Так, в ситуации забивания гола две дополнительные причины являются заведомо необходимыми: удар, посылающий мяч в ворота, и ошибка вратаря. Остальные дополнительные причины являются факультативными. Наконец, возможные причины аi обладают тем свойством, что появление аi необязательно вызывает bj, но увеличивает возможность появления bj. Кроме причин аi важную роль в процессах реализации причинно-следственных зависимостей играют так называемые тормоза. Наличие тормоза наряду с причиной, вызывающей bj в обычных условиях, приводит к тому, что bj не появляется. Так, принятие смертельной дозы яда не приводит к ожидаемому исходу, если до этого было принято противоядие. Вернемся к ДСМ-методу. После сказанного становится ясным, что нахождение причин – кандидатов для формируемых гипотез – дело далеко не простое. В положительных и отрицательных примерах эти причины скрыты в описаниях реальных объектов, обладающих или не обладающих интересующими нас свойствами. Из этих описаний надо выделить кандидатов в причины, а затем убедиться, что выбор оказался не случайным. При первом реальном использовании ДСМ-метода одной из конкретных задач была задача нахождения причин того, что некоторое органическое химическое соединение будет обладать свойством биологической активности. Постулировалась, что информация о причинах биологической активности скрыта в структурной формуле того или иного соединения. Какие-то особенности этих формул оказывали влияние на интересующее исследователей свойство. Экспериментально для многих соединений было установлено наличие или отсутствие в них биологической активности. Эти экспериментальные факты составляли множество положительных и отрицательных примеров. На основании их программы, реализующие ДСМ-метод, должны были найти новые, не известные химикам и фармакологам закономерности, позволяющие без экспериментальной проверки (весьма дорогой и длительной) оценивать возможность того, что вновь синтезированное вещество будет обладать биологической активностью. Суть того, как это делалось с помощью ДСМ-метода, состоит в следующем. Рассмотрим группу положительных примеров. Находим некоторую часть описания объектов, общую для определенной совокупности примеров из этой группы. Например, обнаруживаем в значительной части структурных формул соединений, обладающих свойством биологической активности, кольцевую структуру с фиксированным заполнением позиций в этой структуре. Тогда есть основания считать ее кандидатом в причины. Таких кандидатов может оказаться несколько. Образуем матрицу М+, в которой строки соответствуют выделенным кандидатам аi, а столбцы – интересующим нас следствиям bj (при одном интересующем нас следствии в М+будет один столбец). На пересечении строк и столбцов будем записывать оценки достоверности qk гипотез hi+jk. Об их нахождении будет сказано ниже. Для множества отрицательных примеров аналогичным образом строится другая матрица М–, в которой содержатся оценки достоверности отрицательных гипотез hi–jk. Кандидаты в причины в матрицах М+и М?могут частично совпадать, так как положительные и отрицательные примеры не образуют полной выборки из всего множества возможных примеров. На каждом шаге работы ДСМ-метода используются новые наблюдения, пополняющие множества положительных и отрицательных примеров. Эти новые наблюдения могут либо подтверждать сформированные гипотезы hi+jk и hi–jk либо противоречить им. В первом случае надо увеличивать оценки достоверности соответствующих гипотез, а во втором – уменьшать их. Механизм изменения оценок qk может быть различным. В ДСМ-методе он устроен следующим образом. Значение n совпадает с числом имеющихся в данный момент положительных или отрицательных примеров. Таким образом, для М+и М–значение n может оказаться различным. С ростом n растет «дробность» оценок достоверности. Оценка 1/n играет особую роль. Она соответствует полному незнанию о достоверности гипотезы. Поэтому в начальный момент М+и М–заполнены лишь нулями, единицами и оценками 1/n. Значения истинности и лжи могут иметь гипотезы, у которых в качестве причин даны полные описания объектов, образующих множества примеров. Если некоторая положительная или отрицательная гипотеза hijk имела оценку k/n, то при появлении нового примера (n заменяется на n+1) проверяется, подтверждает или не подтверждает новый пример эту гипотезу. При подтверждении оценка k/n заменяется на (k+1)/(n+1), а при неподтверждении новым примером ранее выдвинутой гипотезы ее оценка меняется с k/n на (k–1)/(n+1). Таким образом, в процессе накопления новой информации оценки гипотез либо приближаются к 0 или 1, либо ведут себя каким-либо «колеблющимся» образом. В первом случае гипотеза может на некотором шаге (когда будет пройден некоторый априорно заданный нижний порог достоверности) исчезнуть из М+или М–. Во втором случае при достижении некоторого верхнего порога достоверности гипотеза может получить оценку, отражающую эмпирическую истину, и запомниться как некий установленный факт в системе или эта гипотеза сообщается человеку, работающему с ДСМ-программами. В третьем случае, если колебания оценок достаточно сильны, может также произойти исключение сформированной ранее гипотезы из тех, которые описаны в М+и М?. Новые гипотезы формируются не только на основании выделения в примерах определенного сходства (общей части в описании). Они могут использовать и метод различия, также сформулированный Миллем. Различие выявляется для примеров, относящихся к группам положительных и отрицательных примеров. Найденное различие служит кандидатом для гипотез, включаемых в М+или М–. Кроме выявления кандидатов в причины аi для положительных и отрицательных гипотез в описываемом методе ищутся также тормоза, наличие которых снимает влияние аi на появление bj. В новых версиях метода в качестве аi выступают весьма сложные утверждения, в которых отдельные части описаний объектов могут быть связаны между собой произвольными логическими выражениями, например, следующего типа: «Если в объекте есть а’ и а’’ и нет а’’’ или в объекте есть а’’’’, то свойство b имеет место». Как уже было сказано, в ДСМ-методе кроме прямой реализации идей Милля используются еще некоторые выводы по аналогии. Для этого на множестве описаний объектов вводится тем или иным способом понятие сходства. Если, например, речь идет о структурных формулах химических соединений, то мерой сходства для них могут быть совпадение самих структур при различных заполнителях позиций или, наоборот, наличие в некоторых фиксированных позициях структур одинаковых элементов. Если установлено отношение сходства, то в ДСМ-методе происходит вывод по аналогии. Он осуществляется следующим способом. Если гипотеза hijk имеет оценку k/n и такова, что причина, используемая в ней, сходна с причиной в гипотезе h’ijk, имеющейся в той же матрице М и оцениваемой с точки зрения достоверности значением 1/n, то на гипотезу h’ijk переносится оценка гипотезы hijk и она получает оценку достоверности k/n. Подобная процедура в ДСМ-методе называется правилом положительной аналогии. Существует в этом методе и правило отрицательной аналогии, а также градация тех и других правил по силе учитывающегося в них сходства. Таким образом, ДСМ-метод демонстрирует возможность проведения правдоподобных рассуждений весьма широкого спектра. Нечеткий вывод Ранее мы говорили о кванторах общности и существования в исчислении предикатов и о близких к ним по смыслу кванторах в силлогистике Аристотеля. Эти кванторы – не единственные. Могут встречаться и более сложные указатели. И как раз их-то чаще всего используют в своих рассуждениях люди. Эти кванторы в отличие от классических кванторов будем называть квантификаторами. Вот, например, квантификатор «только». Какова его роль в наших рассуждениях? Если кто-то говорит: «Маша из всех каш ест только гречневую», то квантификатор «только» выделяет из множества сущностей с именем «каши» одну определенную сущность. В этом случае рассматриваемый квантификатор играет роль выделителя определенной группы элементов. В другом утверждении «Только тропические страны пригодны для возделывания кофе» квантификатор «только» выполняет именно эту роль – выделителя из множества стран тех, которые относятся к тропическим. Утверждение, приведенное нами, порождает два других утверждения: «Существуют тропические страны, в которых возделывается кофе» и «Для всех стран, которые не являются тропическими, неверно утверждение, что в них можно возделывать кофе». Но в естественном языке «только» может использоваться и для указания на другие способы вычленения событий. Вот несколько примеров: «Я купил только чашки» (т.е. я купил чашки, а не что-либо иное), «На лекцию пришло только пять студентов» (т.е. именно пять, а не другое число), «Он приедет только завтра» (а не сегодня? не послезавтра?). Число подобных примеров можно неограниченно продолжать. «Только» – не единственный экзотический квантификатор. Чего стоит, например, квантификатор «Даже»! Сравним два утверждения: «Даже Джек смог догнать эту лисицу» и «Даже Джек не смог догнать эту лисицу». Внешне оба утверждения весьма похожи. Но квантификатор «даже» выполняет в них различную роль. В первом утверждении Джек стоит на нижнем конце шкалы, по которой упорядочены все собаки, пригодные для охоты на лис, а во втором утверждении квантификатор «даже» ставит Джека на первое место в этой шкале. До настоящего времени не создана теория рассуждений с подобными квантификаторами. Поэтому в данном разделе рассмотрим лишь вполне определенную группу квантификаторов, которую будем называть нечеткими квантификаторами. Обозначим их, как это традиционно принято для кванторов в логике, перевернутыми буквами. Прежде всего определим, какие же квантификаторы будем считать нечеткими. Их название указывает на тесную связь с новым разделом математики – нечеткой математикой. Слово «нечеткая» да еще в применении к математике вызывает законное недоумение. Но такова калька английского слова fuzzy, которое можно переводить еще как «размытая» или «расплывчатая». Именно это слово использовал Л. Заде – основатель нечеткой математики. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 |
|||||||
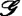 1 и некоторый (вообще говоря, другой) алгебраический язык для описания А’ и В’, который обозначим
1 и некоторый (вообще говоря, другой) алгебраический язык для описания А’ и В’, который обозначим 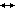 l и m
l и m bj; qk будем называть положительной гипотезой. Оно связано с утверждением типа «аi является причиной bj, с оценкой достоверности qk». Выражение вида аi
bj; qk будем называть положительной гипотезой. Оно связано с утверждением типа «аi является причиной bj, с оценкой достоверности qk». Выражение вида аi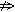 bj;qk будем называть отрицательной гипотезой. Оно связано с утверждением типа «аi не является причиной bj, с оценкой достоверности qk». Для сокращения записи положительные гипотезы будем обозначать hi+jk, а отрицательные – hi-jk. Среди значений qi выделим два специальных, которые можно обозначить 0 и 1. Значение 0, приписанное положительной или отрицательной гипотезе, означает, что соответствующее утверждение является ложным. Приписывание гипотезам значения 1 означает, что данная гипотеза является тождественно истинной. Таким образом, гипотезы с оценками 0 и 1 можно рассматривать как высказывания, ложность и истинность которых твердо установлены. Все остальные оценки, отличные от 0 и 1, будем обозначать рациональными числами вида s/n, где s пробегает значения от 1 до n–1. Величина n характеризует «дробность» используемых оценок достоверности. Чем больше n, тем с большей точностью оценивается степень достоверности гипотез.
bj;qk будем называть отрицательной гипотезой. Оно связано с утверждением типа «аi не является причиной bj, с оценкой достоверности qk». Для сокращения записи положительные гипотезы будем обозначать hi+jk, а отрицательные – hi-jk. Среди значений qi выделим два специальных, которые можно обозначить 0 и 1. Значение 0, приписанное положительной или отрицательной гипотезе, означает, что соответствующее утверждение является ложным. Приписывание гипотезам значения 1 означает, что данная гипотеза является тождественно истинной. Таким образом, гипотезы с оценками 0 и 1 можно рассматривать как высказывания, ложность и истинность которых твердо установлены. Все остальные оценки, отличные от 0 и 1, будем обозначать рациональными числами вида s/n, где s пробегает значения от 1 до n–1. Величина n характеризует «дробность» используемых оценок достоверности. Чем больше n, тем с большей точностью оценивается степень достоверности гипотез.