 |
|
Популярные авторы:: Азимов Айзек :: Грин Александр :: Борхес Хорхе Луис :: БСЭ :: Сименон Жорж :: Горький Максим :: Раззаков Федор :: Лесков Николай Семёнович :: Чехов Антон Павлович :: Толстой Лев Николаевич Популярные книги:: The Boarding House :: Миф Свободы и путь медитации :: История Таурена :: 200 км танков. О российско-грузинской войне :: Небесные творцы :: Глухая тропа :: Атака Боло :: Свидание :: Отражение в неправильном зеркале :: Десятое правило волшебника, или Фантом |
Какой сейчас век?ModernLib.Net / Альтернативная история / Носовский Глеб Владимирович / Какой сейчас век? - Чтение (стр. 12)
Оказывается, аналогичная картина затухания наблюдается и для столбцов матрицы. Это означает, что частота употребления в "главе" X(Q) имен более раннего происхождения "в среднем" тоже падает по мере удаления поколения Т, породившего эти имена, от фиксированного поколения Q. 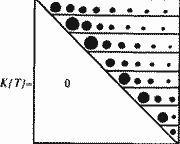 Рис. 5.13 Для оценки скорости затухания частот удобно пользоваться усредненным графиком 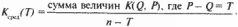
В этой формуле суммирование выполняется по всем парам (Q, Р), для которых разность Р – Q фиксирована и равна Т. Другими словами, график Ксред (T) получается усреднением матрицы К{Т} по ее диагоналям, параллельным главной. Он изображает "усредненную строку" или "усредненный столбец" частотной матрицы. Здесь Т изменяется от 0 до n – 1. Конечно, экспериментальные графики могут не совпадать с теоретическим. Если теперь изменить нумерацию "глав" в летописи, то изменятся и числа K(Q, T), поскольку возникает довольно сложное перераспределение "впервые появившихся имен". Следовательно, меняются частотная матрица К{T} и ее элементы. Будем менять порядок "глав" летописи с помощью различных перестановок s. Каждый раз вычислим новую частотную матрицу K(sT), где sT – новая нумерация, соответствующая перестановке s. Будем искать такой порядок "глав" летописи, при котором все или почти все графики будут иметь вид, показанный на рис. 5.12. В этом случае экспериментальная частотная матрица K{sT} будет наиболее близка к теоретической матрице на рис. 5.13. Тот порядок "глав" летописи, при котором отклонение экспериментальной матрицы от "идеальной" будет наименьшим, и следует признать хронологически правильным и искомым. Наш метод также позволяет датировать события. Пусть дан какой-то исторический текст Y, о котором известно только, что он рассказывает о неких событиях из эпохи (А, В), уже описанной в тексте X, разбитом на "главы-поколения", причем порядок этих "глав" в летописи X хронологически правилен. Как узнать, какое именно поколение описано в интересующем нас тексте Y? При этом мы хотим использовать только количественные характеристики текстов, не апеллируя к их смысловому содержанию, которое может быть разным или допускать сильно разнящиеся трактовки. Ответ таков. Присоединим текст Y к совокупности "глав" хроники X, считая при этом Уновой "главой" и приписав ей какой-то номер Q. Затем установим оптимальный, хронологически правильный порядок всех "глав" получившейся "летописи". При этом мы найдем правильное место и для новой "главы" Y. В простейшем случае, построив для нее график K(Q, T), можно добиться, меняя ее положение относительно других "глав", чтобы этот график был как можно ближе к идеальному. То положение, которое Y займет среди других "глав", и следует признать за искомое. Тем самым мы датируем события, описанные в Y. Методика применима и тогда, когда рассматриваются не все имена, а только одно или несколько имен, например, какие-либо "знаменитые имена". Но в этом случае требуется дополнительный анализ, поскольку уменьшение числа используемых имен делает результаты неустойчивыми. Метод был проверен на больших текстах с большим числом имен и с заранее известной достоверной датировкой. Во всех этих случаях эффективность метода подтвердилась. 4. Принцип дублирования частот. Метод обнаружения дубликатов Настоящий метод является в некотором смысле частным случаем предыдущего, но ввиду важности для датировки мы выделили прием обнаружения дубликатов в отдельный раздел. Этот метод был предложен А. Т. Фоменко. Затем он был существенно развит в серии работ совместно с Г. В. Носовским. Пусть интервал времени (А, В) описан в летописи X, разбитой на "главы-поколения" Х(Т). Пусть они в целом занумерованы хронологически верно, но среди них есть два дубликата, то есть две "главы", говорящие об одном и том же поколении, дублирующие, повторяющие друг друга. Рассмотрим простейшую ситуацию, когда одна и та же "глава" встречается в летописи X ровно два раза, а именно с номером Q и с номером R. Пусть Q меньше R. Наша методика позволяет обнаружить и отождествить эти дубликаты. В самом деле, ясно, что частотные графики K(Q, T) и K(R, T) имеют вид, показанный на рис. 5.14. Первый график явно не удовлетворяет принципу затухания частот. Поэтому нужно переставить "главы" внутри летописи X, чтобы добиться лучшего соответствия с теоретическим, идеальным графиком. Все числа K(R, T) равны нулю, так как в "главе" X(R) нет ни одного "нового имени" – все они уже появились в X(Q). Ясно, что наилучшее совпадение с идеальным графиком на рис. 5.12 получится тогда, когда мы поместим эти два дубликата рядом или просто отождествим их. 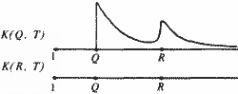
Рис. 5.14 Итак, если среди "глав" летописи, в целом занумерованных правильно, обнаружились две "главы", графики которых имеют приблизительно вид графиков на рис. 5.14, то эти "главы", скорее всего, являются дубликатами. То есть, говорят примерно об одних и тех же исторических событиях, и их следует отождествить. Все сказанное переносится на случай, когда есть несколько дубликатов – три и более. 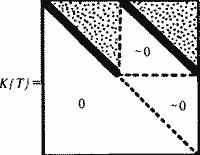 Рис. 5.15 Эта методика также была проверена на экспериментальном материале. В качестве простого примера было взято издание "Истории Флоренции" Макиавелли 1973 года (Ленинград), снабженное развернутыми комментариями. Ясно, что комментарии можно рассматривать как серию "глав", дублирующих основной текст Макиавелли. Основной текст был разбит на "главы-поколения", что позволило построить квадратную частотную матрицу К{Т), охватывающую и комментарий к "Истории". Эта матрица имеет вид, условно показанный на рис. 5.15, где жирные наклонные отрезки состоят из клеток, заполненных максимумами. Это означает, что наша методика успешно обнаруживает известные дубликаты. В данном случае – комментарии к основному тексту "Истории" Макиавелли. 5. Статистический анализ Библии 5.1. Обнаружение известных ранее дубликатов в Библии Следующий пример имеет большое значение для анализа скалиге-ровской хронологии. В Библии содержится несколько десятков тысяч упоминаний имен. Известно, что в Библии есть две серии дубликатов. А именно, каждое поколение, описанное в книгах 1 Царств, 2 Царств, 3 Царств, 4 Царств, затем повторно описано в книгах 1 Паралипоме-нон, 2 Паралипоменон. А. Т. Фоменко разбил Ветхий и Новый заветы на отдельные "главы-поколения". Оказалось, что Ветхий завет состоит из 191 глав-поколений, а Новый завет состоит из глав-поколений с номерами 192-218. Рассмотрим для начала первые 170 глав-поколений, охватывающие так называемые исторические книги Ветхого завета. В 1974– 1979 годах В. П. Фоменко и Т. Г. Фоменко провели огромную работу по составлению полного списка всех имен Библии с учетом всех их кратностей и точным распределением упоминаний имен по всем "главам-поколениям". Оказалось, что всего в Библии упомянуто около 2000 имен, а число их упоминаний, с кратностями, составляет несколько десятков тысяч. Это позволило построить все частотные графики K(Q, T), где номер Г пробегает перечисленные "главы". Оказалось, что графики, построенные для "глав" из книг 1-4 Царств, имеют вид графика на рис. 5.14. То есть имена, впервые появившиеся в этих "главах", затем снова "возрождаются" в прежнем количестве в соответствующих "главах" из книг 1-2 Паралипоменон. Соответствующая часть матрицы К{Т} показана на рис. 5.16. Двумя жирными линиями отмечены две параллельные диагонали, заполненные абсолютными максимумами строк. 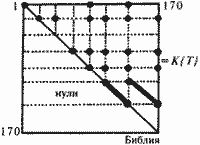 Рис. 5.16 Итак, наша методика успешно обнаружила и отождествила те дубликаты в Библии, которые и ранее были известны как таковые. Подчеркнем, что наши методы оперируют лишь с количественными, числовыми характеристиками текстов и не требуют "вникания в смысловое содержание" хроник. В этом – определенное достоинство новых методов, поскольку они не опираются на субъективные и потому неоднозначные толкования старых текстов. Применение описанных статистических методов иногда облегчается тем, что для многих исторических текстов комментаторами уже проведена большая работа по выявлению повторяющихся фрагментов. Под "повтором" можно понимать не только повторение имени, но и повторное описание какого-то события и т. п. Например, в Библии много раз повторяются одинаковые описания, списки имен, одинаковые религиозные формулы и т.д. Все эти повторы в Библии давно обнаружены, систематизированы и собраны в так называемом аппарате параллельных мест. А именно, рядом с некоторыми стихами указано, какие стихи Библии в этой же или в других книгах Библии считаются его "повторами", то есть ему "параллельными". Если исследуемый исторический текст X снабжен таким или похожим аппаратом, то можно применить наш метод обнаружения дубликатов, считая повторяющиеся фрагменты за "повторяющиеся имена". Рассмотрим подряд все книги Библии, как ветхозаветные, так и новозаветные. В книге[МЕТ1] приведено разбиение Библии на 218 "глав-поколений". Занумеруем их в том порядке, в каком они следуют друг за другом в каноническом упорядочении книг Библии. Известно, что аппарат "повторов", параллельных мест в Библии содержит около 20 тысяч повторяющихся стихов. В каждой "главе-поколении" X(Q) подсчитаем количество стихов, которые еще ни разу не появлялись в предыдущих "главах" Х(Т). То есть впервые появившихся в X(Q). Их количество обозначим через П(Q, Q). Затем мы подсчитаем, сколько раз эти стихи повторяются в последующих "главах-поколениях" Х(Т). Полученные числа обозначим через П(Q, Т). После этого построим все 218 частотных графиков П(Q, T). Их отличие от графиков K(Q, T) лишь в том, что здесь вместо ИМЕН берутся СТИХИ, а вместо повторений имен – повторения стихов. Стихи, не являющиеся повторами друг друга или какого-то другого стиха, рассматриваются здесь как "различные имена". Вся эта огромная работа была проведена В. П. Фоменко. Следовательно, при правильном хронологическом порядке "глав-поколений" и при отсутствии дубликатов частотные графики повторов стихов П(Q, Т) должны примерно иметь вид идеального затухающего графика (рис. 5.12). Как и в случае использования имен, летописец – при правильном порядке описываемых им событий, – говоря о событиях поколения Q, ничего не сообщает об этих событиях в предыдущих "главах-поколениях". Дело в том, что эти события еще не произошли. А в последующих "главах-поколениях" летописец вспоминает о событиях поколения (?все реже и реже. Следовательно, "хронологически правильный" график частот должен иметь абсолютный максимум в точке Q, равняться нулю слева от Q и монотонно падать, затухать справа от Q. Экспериментальная проверка, выполненная нами, подтвердила принцип затухания частот для всех перечисленных ниже отдельных кусков Библии: 1) Бытие, гл. 1-5, 2) Бытие, гл. 6-10, 3) Бытие, гл. 11, 4) Бытие, гл. 12-38, 5) Бытие, гл. 59-50 + Исход + Левит + Числа + Второзаконие + Иисус Навин + Судьи, гл. 1-18, 6) Судьи гл. 19-21 + Руфь + 1-3 Царств + 4 Царств, гл. 1-23, 7) 1– 2 Паралипоменон + Ездра + Неемия. Оказалось, что все частотные графики П(Q, T) имеют для каждого из этих текстов (1-7) вид затухающего теоретического графика (на рис. 5.12). Это означает, что принцип затухания частот в указанных случаях подтверждается и, кроме того, в каждом тексте порядок "глав-поколений" хронологически более или менее правилен. Причем существенные дубликаты внутри них отсутствуют. Если все "главы-поколения" летописи занумерованы в целом правильно, то наличие среди них дубликатов можно обнаружить, построив графики "повторов стихов" П(Q, T). Если две "главы" X(Q) и X(R) являются дубликатами, то их частотные графики П (Q, T) и П(R, Т) имеют вид, показанный на рис. 5.14. Эта методика была также экспериментально проверена для описанного выше примера, а именно, книги 1-4 Царств дублируют книги 1-2 Паралипоменон. Построение частотных графиков П(Q, Т) для Библии обнаружило, что дубликатами оказываются именно те "главы" из книг 1-4 Царств и книг 1-2 Паралипоменон, которые оказались дубликатами и с точки зрения частотных графиков K(Q, Т). Это указывает на полное согласование результатов применения обеих методик. При этом следует отметить, что аппарат "параллельных мест" вовсе не тождественен с аппаратом "повторов имен", так как "параллельными" считаются, например, многие фрагменты, стихи Библии, вообще не содержащие имен. 5.2. Новые, ранее неизвестные дубликаты, обнаруженные нами в Библии Теперь мы переходим к краткому изложению результатов применения разработанных методов к "античному" и средневековому хронологическому материалу, обычно относимому к эпохам ранее XIII – XIV веков. При этом неожиданно были обнаружены дубликаты, считающиеся в скалигеровской истории событиями различными и датируемыми сегодня существенно разными эпохами. Применим, например, методику обнаружения дубликатов на основе частотных графиков K(Q, Т) и П(Q, Т) к Библии. А именно, к книгам Ветхого завета от книги Бытие до книги Есфирь. Полученный результат мы изобразим в виде условной строки Б, в которой одинаковыми символами-буквами обозначены обнаруженные нами дубликаты. То есть фрагменты Библии, по-видимому, говорящие об одних и тех же событиях, как это следует из описанной выше проверки принципа дублирования частот. Итак, 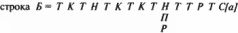
Этот наш результат означает, что вся историческая часть Ветхого завета состоит из нескольких кусков: Т, К, Н, П, Р, С[а], некоторые из них повторены в Библии по нескольку раз и поставлены в разные места библейского канона, что и дает описанную выше "длинную" строку-хронику Б. Другими словами, в Ветхом завете многие куски, указанные нами в строке-хронике Б, по-видимому описывают в действительности одни и те же события. Этот факт противоречит скалигеровской хронологии, согласно которой разные книги Библии – за исключением книг 1-4 Царств и КНИТ 1 – 2 Паралипоменон – описывают разные события. Поясним теперь смысл указанных символов в библейской строке-хронике Б. Указывая какой-либо символ, мы приводим соответствующие ему фрагменты Библии. Итак, Б = Т = Бытие, гл. 1-3 К = Бытие, гл. 4-5 Т = Бытие, гл. 6-8 Н = Бытие, гл.9-10 Т = Бытие, гл. 11:1-9 К = Бытие, гл. 11:10-32 Т = Бытие, гл. 12 К = Бытие, гл. 13-38 Т = Бытие, гл. 39-50 Т = Исход Н/П/Р = Левит + Числа + Второзаконие + Иисус Навин + Судьи, гл. 1-18 Т = Судьи, гл. 19-21 Т = Руфь + 1-2 Царств + 3 Царств, гл. 1-11 Р = 3 Царств, гл. 12-22, + 4 Царств, гл. 1-23 Г = 4 Царств, гл.24 С[а]= 4 Царств, гл. 25 + Ездра + Неемия + Есфирь. Кроме того, последовательность фрагментов Т Р Т C[a] в конце строки-хроники Б повторно описана в книгах 1-2 Паралипоменон. Эти две последние серии дубликатов – единственные, ранее известные. Остальные дубликаты, предъявленные нами выше, ранее известны не были. Эти дубликаты среди "глав" 1-170 в Библии обнаруживаются на частотной матрице К(T) так. Две серии ранее известных дубликатов: "главы" 98-137 и дублирующие их "главы" 138-167 – дают следующий эффект. Наряду с максимумами, заполняющими главную диагональ, в строках с номерами 98-137 имеется еще диагональ, также заполненная максимумами и параллельная главной (рис. 5.16). Эти диагонали изображены на рис. 5.16 черными наклонными отрезками. Строки 138-167 состоят практически из одних нулей. Остальные дубликаты обнаруживаются примерно одинаковыми по величине локальными всплесками, расположенными на пересечениях соответствующих строк и столбцов, отвечающих дубликатам. Затем мы дополнительно проанализировали частотные матрицы K{Т} и П{T}. Каждая серия обнаруженных нами дубликатов была объединена в одну главу-поколение. После этого были заново вычислены матрицы K{Т} и П{T}. Оказалось, что эти новые матрицы – то есть после отождествления дубликатов – заметно отличаются от первоначальных и существенно лучше удовлетворяют принципу затухания частот. Применение нашего метода к полной частотной матрице К{T} размером 218x218 – то есть для всей Библии, разбитой на 218 глав-поколений, – обнаружило, что принятая сегодня скалигеровская хронология книг Ветхого и Нового заветов, по-видимому, неверна. Выяснилось следующее. Чтобы последовательность библейских "глав" 1-218 стала хронологически правильной, нужно некоторым, вполне определенным образом перетасовать "главы" 1-191, то есть Ветхий завет, и "главы" 192-218, то есть Новый завет. Следует вдвинуть ветхозаветные и новозаветные книги друг в друга, перемешав их наподобие того, как вдвигаются навстречу друг другу зубья двух гребенок. Детали этой перестановки мы здесь опускаем ввиду громоздкости материала и ниже приведем лишь один, но зато очень яркий пример. После такой "упорядочивающей перестановки" и отождествления обнаруженных нами ветхозаветных и новозаветных дубликатов обе матрицы K{Т} и П{T} становятся практически идеально затухающими. Эти результаты указывают, что вероятно, Книги Ветхого и Нового заветов создавались более или менее одновременно, в одну и ту же историческую эпоху. И лишь затем были искусственно раздвинуты скалиге-ровской хронологией на многие сотни лет, в даль друг от друга, и отнесены в глубокое прошлое. Напомним, что скалигеровская хронология уверяет нас, будто Ветхий завет был создан задолго до Нового завета, якобы на несколько сотен лет. 5.3. Яркий пример: новая статистическая датировка Апокалипсиса. Он перемещается из Нового завета в Ветхий завет? Проиллюстрируем описанный выше эффект перемешивания ветхозаветных и новозаветных книг на примере известной книги Апокалипсис (Откровение святого Иоанна). В скалигеровском упорядочении она занимает последнее место в Новом завете. Поэтому в нашей нумерации "скалигеровских глав-поколений" эта книга получила последний номер 218. Если ли бы такое, принятое сегодня, расположение Апокалипсиса в Библии было хронологически верным, то его частотный график-столбец имен К{Т, 218}, то есть при Q = 218, должен был бы иметь вид, показанный на рис. 5.17 (см. нижний график). ОДНАКО РЕАЛЬНЫЙ ЧАСТОТНЫЙ ГРАФИК ДЛЯ АПОКАЛИПСИСА СОВСЕМ ДРУГОЙ! (См. верхний график на рис. 5.17.) Поразительно, что максимум графика приходится отнюдь не на "главы", близкие к Апокалипсису, то есть к номеру 218, а на удаленные "главы" 70-80 для частотного графика имен и на удаленные главы 74-77 и 171-179 для частотного графика параллельных мест, ссылок. Другими словами, абсолютный максимум обоих графиков приходится не на новозаветные книги, а на книги Ветхого завета, отделяемые сегодня от Апокалипсиса несколькими сотнями лет. Таким образом, мы обнаружили яркое противоречие с принципом затухания частот, надежно подтвержденным ранее на достоверно датированных и хронологически правильно упорядоченных текстах. Мы уже знаем, как нужно поступать в таких случаях. Нужно переставить библейские "главы" таким образом, чтобы их частотные графики стали затухать. В результате мы найдем хронологически верный порядок "глав" Библии. Такая операция хронологически правильного "перемешивания" библейских книг была описана выше. Любопытно, что при обнаруженном нами "перемешивании" новозаветный Апокалипсис оказывается рядом с ветхозаветными пророчествами и с ветхозаветными "главами" 69-75. В частности, Апокалипсис попадает в одну группу с ветхозаветным пророчеством Даниила. Это прекрасно согласуется с известной точкой зрения, что пророчество Даниила – это "апокалипсис, во многих отношениях сходный с новозаветным". 6. Метод анкет-кодов. Сравнение двух длинных потоков царских биографий В скалигеровской истории распространены штампы и заимствования, использовавшиеся, например, при описании правителей. Считается, что летописцы иногда приписывали современным им правителям качества и деяния каких-то других, давно умерших древних царей. Скалигеровская история уверяет нас, будто такое странное увлечение летописцев "стариной" было широко распространено. Не зная якобы ничего достоверного о жизни своих собственных современных царей, летописцы будто бы поступали очень просто. Они снабжали своих царей "громкими биофафиями" каких-то давным-давно умерших великих правителей. О жизни которых они, следовательно, были осведомлены куда лучше, чем о жизни своих современников. Что уже само по себе странно. Наверное, такие случаи действительно бывали, но скорее всего они были редки. Наши исследования показали, что к этому странному "скалигеровскому эффекту" следует присмотреться повнимательнее, поскольку за ним стоит нечто куда более серьезное, чем простая "любовь летописцев к литературным штампам". 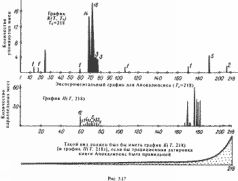
Для выявления и изучения таких штампов, повторов, а также для обнаружения дубликатов мы ввели понятие анкет-кода или формализованной биографии. Реальный правитель, будучи описан в летописях, приобретает тем самым "историческое летописное жизнеописание". Которое может не иметь ничего общего с реальной его биофафией, может быть полностью легендарным. Мы не собираемся здесь обсуждать вопрос – насколько точно летописная биофафия царя отражает реальность. Эта прошедшая реальность сегодня нам уже неизвестна. Поэтому мы вряд ли можем восстановить подлинные древние биофа-фии. Да это нам сейчас и не нужно. Наша цель другая. А именно, попытаться выявить среди множества биофафических текстов те, которые на самом деле рассказывают об одном и том же человеке. Речь идет о текстах, которые, будучи написаны разными людьми, не были распознаны позднейшими средневековыми летописцами и хронологами как биофафии одного и того же персонажа. И – как следствие – были помещены ими в разные разделы "скалигеровского учебника истории", в разные исторические эпохи. Как якобы биофа-фии совсем разных лиц. Так один реальный персонаж "размножился" – но лишь на бумаге! – и породил несколько своих фантомных отражений. На основе изучения большого числа исторических биографий мы разработали таблицу, названную анкет-кодом АК. Таблица-анкета иерархически упорядочивает факты "биофафии" по мере уменьшения их инвариантности относительно субъективных оценок хронистов. Анкет-код состоит из 34 пунктов, каждый из которых содержит несколько подпунктов: 1. Пол: а) мужской, б) женский. 2. Длительность жизни. 3. Длительность правления. Конец правления практически всегда однозначно фиксирован. Обычно это смерть царя. Начало правления допускает иногда несколько вариантов. Отмечаются как равноправные все варианты. 4. Социальное положение и занимаемый пост: а) царь, император, король, б) полководец, в) политик, общественный деятель, г) ученый, писатель и т. д., д) религиозный вождь, папа, епископ и т. д. 5. Смерть правителя: а) естественная смерть в мирной обстановке, б) убит на поле боя противниками или смертельно ранен, в) убит в результате заговора, вне войны, г) убит в результате заговора во время войны, д) специальные, экзотические обстоятельства смерти. 6. Стихийные бедствия во время правления: а) голод, б) наводнения, в) повальные болезни, г) землетрясения, д) извержения вулканов; при этом отмечаются также длительность бедствий и год или годы, когда они имели место. 7. Астрономические явления во время правления: а) есть (какие именно, с указанием дат), б) нет, в) затмения, г) кометы, д) "вспышки звезд". 8. Войны во время правления: а) есть, б) нет. 9. В = число войн. 10. Основные временные характеристики войн Bv… Bp. А именно, ак = на каком году правления происходит или началась война Вк; ск х = временное расстояние от войны Вк до войны Вх. 11. "Сила", "напряженность" войны Вк, согласно летописи, для каждого номера к: а) сильная, б) слабая. Более точно, сколькими строками описана война в данной летописи. 12. Число противников в войне Вк и схема их взаимоотношений – союзники, противники, нейтральные силы, посредники и т. д. 13. Географическая локализация войны Вк: а) около столицы, б) внутри государства, в) вне государства, внешняя война, где именно, г) одновременно внутренняя и внешняя война. 14. Результат войны: а) победа, б) поражение, в) неопределенный исход. 15. Мирные договоры: а) заключение мирного договора при неопределенном исходе, б) заключение мирного договора после поражения. 16. О захвате столицы: а) захвачена, б) не захвачена. 17. Судьба мирного договора: а) нарушен (кем), б) не нарушен во время правления. 18. Обстоятельства захвата, падения столицы. 19. Схема траекторий походов во время войны. 20. Участие правителя в войне: а) участвует, б) не участвует. 21. Заговоры при жизни правителя: а) есть, б) нет. 22. Географическая локализация заговоров, войн, восстаний. 23. Название столицы, с переводом на разные языки. 24. Название государства и народа, с переводами. 25. Географическая локализация столицы. 26. Географическая локализация государства. 27. Законодательная деятельность правителя: а) реформы и их характер, б) издание нового свода законов, в) реставрация старых законов и каких именно. 28. Список всех имен правителя, с их переводами. 29. Этническая принадлежность правителя, а также членов его семьи, состав семьи. 30. Этническая принадлежность народа, племени, клана. 31. Основание новых городов, столиц и т. п. 32. Религиозная обстановка: а) введение новой религии, б) борьба сект, каких именно, в) религиозные восстания и войны, г) церковные соборы, религиозные собрания. 33. Династическая борьба внутри родственного клана правителя, убийства родственников, противников, претендентов и т.д. 34. Остальные факты "биографии". Мы не будем дифференцировать их подробно и условно назовем этот пункт 34 – "остатком биографии". Обозначим перечисленные пункты АК-1, АК-2,… АК-34. Итак, каждую "летописную биографию" можно теперь записать в виде таблицы-анкеты, некоторые пункты которой могут оказаться пустыми, если соответствующая информация о персонаже не сохранилась. Допустим, что некоторая реальная династия описана в какой-то летописи. Занумеруем правителей, и на основе этой летописи составим для каждого из них его анкет-код АК. Получим последовательность анкет-кодов, которую мы назовем потоком анкет-кодов династии. Поскольку одна и та же реальная династия может описываться в разных летописях, то она может изображаться и разными потоками анкет-кодов. Как узнать, описывают ли две разные летописи одну и ту же реальную династию или же описываемые ими династии действительно разные? Если в летописях указаны длительности правлений царей, то можно применить методику распознавания летописных династий. Однако если таких числовых данных не сохранилось, задача заметно усложняется. Итак, как распознать в множестве всех потоков анкет-кодов одну и ту же реальную династию царей? Для решения этого вопроса мы разработали методику, основанную на аналоге принципа "малых династических искажений", который в данном случае кратко формулируется так. Если потоки анкет-кодов двух династий "мало" отличаются друг от друга, то они изображают одну и ту же реальную династию. Если же два потока анкет-кодов изображают разные династии, то эти потоки анкет-кодов "далеки" друг от друга. Как можно сравнивать потоки анкет-кодов двух династий и отвечать на вопрос: "похожи" они или нет? А если "похожи", то в какой степени? Пусть АКк АК' – анкет-коды двух правителей из разных династий, имеющих один и тот же порядковый номер в своей династии. Сравним эти два анкет-кода в каждом их пункте. Расхождение между пунктами будем оценивать в баллах. Для разных пунктов эти баллы следует установить различными, в зависимости от их важности и степени инвариантности сравниваемых "биографических фактов" относительно субъективных оценок летописцев. В результате экспериментирования с конкретными "летописными биографиями" мы выработали следующую систему баллов, позволяющую быстрее обнаруживать возможные зависимости. Для пунктов 1-10, за исключением пункта 3 (то есть длительности правления), будем использовать баллы 0, +1, – 1. Для пунктов 11-21 будем использовать баллы 0, +1/2, – 1/2. Для пунктов 22-33 – баллы 0, +1/3, – 1/3.. При сравнении пунктов анкет-кодов возможны три случая. Проиллюстрируем их на примере пунктов с номером 5, то есть АК-5: "обстоятельства смерти правителя". A. Сравниваемые сведения СОВПАДАЮТ. Например, и в АК, и в АК' сказано, что оба сравниваемых царя умерли естественной смертью. В этом случае этой паре пунктов мы придадим балл +1 (совпадение). Будем условно записывать это так: Е= +1. Б. Сравниваемые сведения ЯВНО НЕ СОВПАДАЮТ, противоречат друг другу. Например, в АК сказано, что царь умер естественной смертью, а в АК сообщено, что сравниваемый с ним царь был убит в результате заговора. В этой ситуации мы дадим балл – 1 (противоречие). При этом запишем: Е5 – 1. B. Сравниваемые сведения НЕЙТРАЛЬНЫ, то есть не совпадают, но и не противоречат друг другу. Например, в АК сказано, что "царь умер", а в АК' сообщено, что "царь был убит". Здесь дадим балл 0 (нейтральная ситуация), то есть напишем: Е = 0. Итак, для каждой пары пунктов с номером i (сравниваемых анкет-кодов) мы получаем некоторое число Е… Следовательно, для пары анкет-кодов АК и АК двух сравниваемых царей можно подсчитать сумму всех получившихся чисел Е: f(АК, АК') = E1 + Е2 + Е4 + Е5 +… + Е34. Напомним, что коэффициент Е3 мы здесь не рассматриваем, поскольку для сравнения длительностей правлений у нас разработана другая методика, подробно изложенная выше. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32 |
|||||||