Все под контролем: Кто и как следит за тобой
ModernLib.Net / Публицистика / Гарфинкель Симеон / Все под контролем: Кто и как следит за тобой - Чтение
(стр. 7)
|
Автор:
|
Гарфинкель Симеон |
|
Жанр:
|
Публицистика |
|
-
Читать книгу полностью
(782 Кб)
- Скачать в формате fb2
(673 Кб)
- Скачать в формате doc
(312 Кб)
- Скачать в формате txt
(300 Кб)
- Скачать в формате html
(683 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27
|
|
Вместо того чтобы полагаться на биометрию для решения социальной проблемы телесной идентификации, мы могли бы предложить социальный путь ее решения. Одним из вариантов могло бы быть ужесточение наказания за «подделку личности» при относительно слабой системе биометрической идентификации. Далее мы должны законодательно установить, что при этом ущерб наносится не только банку или учреждению, которое было непосредственно обмануто, но и человеку, чье имя при этом использовалось. В ближайшем будущем биометрия станет неотъемлемой частью всех аспектов нашей жизни. Но, вследствие описанных выше недостатков и проблемы ущемления гражданских свобод, наша цивилизация вряд ли когда-нибудь создаст общество, тотально отслеживающее каждого при помощи биометрии. Вместо отслеживания каждого отдельного человека наша цивилизация все больше склоняется к более простому варианту – отслеживанию событий. Этому аспекту посвящена следующая глава.
4
Что вы делали сегодня?
В юношеские годы я начинал вести дневник. Каждый вечер, перед тем как отправиться спать, я брал ручку и подробно записывал события прошедшего дня. Как раз в это время я начал встречаться с девушками, и вскоре страницы моего блокнота были заполнены моими романтическими историями: я писал, кто мне нравился, а кто нет, с кем я встретился в школе, с кем говорил по телефону. И конечно, я записывал подробности самих свиданий: с кем мы были, куда ходили, что ели и что делали.
Приблизительно через месяц у меня получилась довольно внушительная летопись моих отроческих подвигов. Но со временем записи в дневнике становились все короче и короче, требовалось слишком много усилий, чтобы описывать все подробно. В конечном счете мой проект зачах под весом своих собственных данных.
В современном мире вести подобный дневник гораздо легче. Каждый раз, когда я покупаю что-нибудь по кредитной карте, я получаю маленький желтый слип,
который напомнит мне точное время и место покупки. Еще более детальный отчет о покупках я получаю в ближайшем супермаркете: там указывается название и количество всего, что я приобрел по своей карте. В моей карточке часто летающего пассажира указан каждый город, в который я совершал полет в течение последнего года. Если вдруг я случайно выброшу карточку, то с информацией ничего не произойдет – вся она аккуратно хранится в многочисленных банках данных.
Даже информация о моих телефонных звонках тщательно записывается, распечатывается и предоставляется мне в конце каждого месяца. Помню, когда я еще учился в колледже, моя подружка решила порвать со мной во время междугородного разговора. Мы говорили 20 минут, а затем она повесила трубку. Я звонил ей снова и снова, но каждый раз натыкался на автоответчик. Через несколько недель мне пришел счет с распечаткой звонков: один разговор длительностью 20 минут, а за ним через короткие промежутки еще пять звонков по 15 секунд.
Но самое большое количество информации о моей жизни хранит жесткий диск моего компьютера: архив электронных писем начиная с младших курсов колледжа. Он занимает более 600 мегабайт, что составляет примерно 315 тысяч страниц текста, напечатанного через два интервала, или по 40 страниц каждый день начиная с 3 сентября 1983 года, когда я получил свой первый электронный почтовый ящик в MIT.
«Сохраняй все свои старые электронные письма, – сказал мне мой друг Гарольд перед самым выпуском. – Когда в будущем историки захотят написать о 80-х годах XX века, мы будем одними из тех, кто попадет в историю». И он был прав: с помощью поиска по ключевым словам и современных систем обработки текстов какому-нибудь историку в будущем будет достаточно просто воссоздать очень точную картину моей жизни начиная со студенческих лет путем анализа оставленных мною электронных записей.
Но этот архив фактов и впечатлений – обоюдоострый клинок. Кроме моего собственного дневника, я оставил великое множество «информационных теней» [data shadow], которые могут поведать секреты моей повседневной жизни любому, кто сможет эти тени прочитать.
Термин «информационная тень» предложил в 1960-е годы Алан Уэстин. Профессор Колумбийского университета в Нью-Йорке, Уэстин предупреждал, что записи о кредитах, банковские и страховые записи, а также другая информация, наполняющая электронную инфраструктуру Америки, могут быть легко скомбинированы для создания подробнейших электронных досье. Эта зловещая метафора удивительно точна: очень малое количество людей обращают внимание на то, куда падает их тень, и очень немногие в будущем смогут контролировать свои электронные досье, предполагал Уэстин.
Прошло три десятилетия, и информационные тени переросли из академического предположения в объективную реальность, касающуюся каждого из нас.
Мы стоим на границе информационного кризиса. Никогда ранее такое огромное количество информации о таком количестве людей не собиралось в таком количестве различных мест. Никогда раньше такое огромное количество информации не было так легко доступно такому количеству учреждений таким количеством способов и для такого количества различных целей.
В отличие от электронной почты, которую я храню в моем портативном компьютере, моя информационная тень вышла из-под моего контроля. Распыленные по компьютерам тысяч разных компаний, мои информационные тени стоят по стойке «смирно» плечом к плечу с другими тенями в банках данных корпораций и правительств по всему миру. Эти тени делают выявление человеческих секретов обычным занятием. Эти тени заставляют нас соответствовать новому стандарту ответственности. А поскольку информация, отбрасывающая эти тени, может случайно оказаться некорректной, они делают всех нас уязвимыми против наказания или воздаяния за действия, которых мы никогда не совершали.
Но есть и хорошая новость: мы можем бороться против этого глобального вторжения в частную жизнь. Мы можем бороться за прекращение фиксации всех ежедневных событий. А там, где такая фиксация необходима, мы должны установить соответствующую деловую практику и принять законы, которые будут гарантировать неприкосновенность нашей частной жизни – защиту для живущих рядом с нами информационных теней. Мы уже делали это ранее. Все, что необходимо людям, – это понять, как и где эта информация записывается и как нам это остановить.
Информационный кризис
В качестве эксперимента попробуйте составить список информационных следов, которые вы оставляете ежедневно. Рассчитались за ланч кредитной картой? Запишите. Платили за ланч наличными, но перед этим получили их в банкомате? Если да, то это снятие денег также оставляет еще одну информационную тень. Каждый междугородный звонок, каждое оставленное на автоответчике сообщение и каждый посещенный в Интернете web-сайт – все это части вашего подробнейшего досье. Вы оставляете больше следов, если живете в городе, пользуетесь кредитной картой и если ваша работа связана с использованием телефона или компьютера. Вы будете оставлять меньше следов, если живете в сельской местности или небогаты. В этом нет ничего странного: именно накопление подробной информации сделало возможным современное развитие экономики. Удивительно другое – объем косвенной информации, которую можно получить по этим записям. Каждый раз, когда вы снимаете деньги в банкомате, компьютер записывает не просто количество снятых денег, но сам факт вашего нахождения в конкретном месте в конкретное время. Позвоните на номер, оборудованный автоматическим определителем (АОН), и маленькая коробочка запишет не просто ваш номер (и, возможно, имя), но и точное время, когда вы сделали свой звонок. Попутешествуйте в Интернете, и web-сервер по другую сторону дисплея не просто отметит, какие страницы вы просмотрели, но и скорость вашего модема, тип использованного браузера и даже ваше географическое местоположение. Между тем мы не сделали страшного открытия. Еще в 1986 году Джон Дайболд [John Diebold] писал об одном банке, который:
…установил сеть банкоматов и сделал интересное наблюдение, «что необычное количество снятий денег производится каждую ночь между полуночью и 2 часами»… Заподозрив неладное, банк нанял детективов для установления истины. Выяснилось, что большинство припозднившихся клиентов снимали наличные деньги, направляясь в местный квартал красных фонарей!
В появившейся в
Knight News Serviceпосле инцидента статье говорилось: «Кое-где в Америке существуют банки, которые знают, кто из клиентов платил сутенеру прошедшей ночью».
(Дайболд, один из компьютерных пионеров 1960-х – 1970-х годов, сначала был сторонником создания Национального информационного центра. Но к 1986 году он стал считать, что идея построения центра была огромной ошибкой, так как приводила к слишком большой концентрации информации в одном месте.) Я называю записи, подобные архивам банкоматов, «горячими файлами» [hot files]. Они очень интересны, они могут раскрыть совершенно неожиданную информацию и находятся за пределами понимания большинства людей. Последние 15 лет мы наблюдаем все более широкое использование этой информации. Один из ранних случаев, который я помню, произошел в 1980-е годы. Тогда американское Управление по борьбе с наркотиками [Drug Enforcement Agency, DEA] начало сопоставлять данные из садоводческих магазинов с информацией из электрических компаний. Проект назывался «Операция „Зеленый торговец“». К 1993 году DEA в сотрудничестве с местными правоохранительными органами предотвратило более 4 тысяч готовящихся операций, арестовало более полутора тысяч нарушителей и заморозило миллионы долларов капиталов в виде незаконной прибыли и имущества.
Однако программа подверглась критике, ее называли облавой, жертвами которой стали не только преступники, но и невинные граждане. Сыщики искали людей, тайно выращивающих марихуану. Но вместе с некоторым количеством наркофермеров пострадали и несколько невиновных садовников, включая жившего по соседству с редактором газеты
New York Times. Timesдаже опубликовала передовицу на эту тему, но это не остановило деятельность DEA. Американцы получили и другую порцию сюрпризов в конце 1987 года, когда президент Рональд Рейган выдвинул на пост Верховного судьи США Роберта Борка [Robert Bork]. Выдвижению Борка отчаянно воспротивилась группа женщин, заявлявшая, что Борк замечен в дискриминации женщин; они опасались, что Борк может оказать давление в решении вопроса о запрете абортов. В поисках компромата журналист из либеральной газеты
City Paperиз Вашингтона, федеральный округ Колумбия, получил распечатку названий видеофильмов, которые Борк брал напрокат в ближайшей видеотеке. Журналист надеялся обличить Борка в пристрастии к порнографии, но его вкусы оказались совсем другими: из 146 взятых им напрокат фильмов большинство оказались диснеевскими мультфильмами и фильмами Хичкока. Тем не менее репутация Борка была несколько подпорчена. Некоторые публикации о Борке и множество отпускаемых на приемах бесцеремонных замечаний игнорировали тот факт, что журналист остался с пустыми руками в своих поисках порнографии. Вместо этого формировалось мнение, что Борк увлекается порнографией, или, по крайней мере, читателя подталкивали к такому выводу. Проблема горячих файлов состоит в том, что они слишком горячие: с одной стороны, они открывают такую информацию о нас, которую большинство людей предпочитают не оглашать в приличном обществе; с другой стороны, находящуюся в них информацию легко неправильно интерпретировать. Более того, эта информация может быть и сфальсифицирована: если бы служащий видеотеки захотел, он мог бы добавить в регистрационные записи Борка пару дюжин порнографических киношек, и никто бы никогда не смог доказать, что запись фальшивая. В нашем обществе превалируют компьютеризованные системы записи и хранения информации, и мы вскоре будем наблюдать все большее число случаев, когда информация, собираемая такими системами для одной цели, будет использована совсем для другой. Развитие современных технологий делает этот сценарий все более реалистичным. Раньше компьютеры просто не могли хранить всю доступную им информацию: системы проектировались так, чтобы периодически стирать данные, которые им больше не нужны. Но современный уровень развития технологий хранения информации достиг таких высот, что данные можно хранить месяцы и даже годы после того, как они больше не нужны для текущей работы. В результате сегодня компьютеры могут хранить гораздо более полное досье на каждого из нас, как это произошло с записями судьи Борка в видеотеке. Попробуйте найти ответ на вопрос: с какой целью в видеотеке хранились записи о фильмах, которые Борк брал напрокат, после того, как они были возвращены? Этот океан информации создает новый стандарт подконтрольности в нашем обществе. Вместо доверия людям и презумпции невиновности мы просто сверяемся с записями и видим, кто плохой, а кто хороший. Высокая доступность персональной информации облегчает также жизнь преступникам, бродягам, шантажистам, провокаторам и другим «плохим парням». Одним из наиболее драматичных случаев стало убийство актрисы Ребекки Шефер [Rebecca Schaefer] в 1989 году. Шефер прилагала достаточно много усилий для сохранения своей приватности. Но один помешанный 19-летний поклонник, мечтавший встретиться с ней, нанял частного детектива, чтобы тот нашел домашний адрес его кумира. Детектив обратился в калифорнийское Управление по регистрации транспортных средств [Department of Motor Vehicles], которое в то время предоставляло регистрационную информацию любому желающему, так как она являлась общедоступной. После этого фанат проник в дом Шефер, прождал ее четыре часа и выстрелил ей в грудь, как только она открыла входную дверь.
Синдром фальшивых данных
Еще одна коварная проблема с океаном информации – это то, что я называю «синдром фальшивых данных» [false data syndrom]. Поскольку большинство данных в этом океане информации корректно, мы все предрасположены верить, что они корректны полностью – опасное заблуждение, которому легко подвергаются все. Это заблуждение поддерживают поставщики информации, скрывая недостатки своих систем.
Например, в 1997 году телефонная компания NYNEX (входящая теперь в Bell Atlantic) запустила агрессивную рекламную кампанию по продаже услуги определения номера звонящего абонента своим клиентам. Реклама подзаголовком «Узнайте, кто вам звонит, не поднимая трубки» гласила:
Определитель номера позволяет вам узнать
имяи
номервызывающего абонента, что дает вам возможность принять решение: ответить на звонок сейчас или перезвонить позже. Даже если звонивший не оставил сообщения, ваш определитель номера автоматически запишет имя звонившего, номер телефона и время звонка. Определитель также работает в режиме ожидания вызова, поэтому вы можете узнать, кто вам звонит
даже во время разговора с кем-то другим.
Конечно, NYNEX подменила понятие идентификации личности идентификацией телефонного номера. Определитель показывает не номер телефона, принадлежащий звонившему, а номер, с которого он звонил. Так называемый «расширенный» определитель, высвечивающий имя и номер телефона, на самом деле показывает не имя звонящего, а имя человека, на которого этот номер записан в телефонном справочнике. Если я сделаю непристойный звонок, находясь у вас в гостях на вечеринке, или воспользуюсь им для угроз жизни президента США (государственное преступление), то определитель скажет, что преступник – вы, а не я.
Отслеживаем процесс: Как наша информация может быть обращена против нас
Никто не собирается создавать общество, в котором все незначительные подробности повседневной жизни постоянно записываются для будущих поколений. Но это будущее, к которому мы уверенно движемся благодаря целому ряду социальных, экономических и технологических факторов.
Человеку свойственна склонность к собирательству. Психологически гораздо проще оставить что-то, чем выбросить. Это в полной мере относится и к информации. Никто не чувствует себя комфортно, уничтожая деловую корреспонденцию или стирая старые данные: мы никогда не знаем, когда что-то может понадобиться. Современные технологии позволяют воплотить нашу коллективную мечту никогда ничего не выбрасывать, по крайней мере информацию.
Первый компьютер, который я купил в 1978 году, хранил информацию на магнитофонных кассетах. Я мог поместить 200 килобайт информации на 30-минутную кассету, и я был счастлив. Компьютер, которым я пользуюсь сейчас, имеет внутренний жесткий диск, который может хранить б гигабайт информации.
И это увеличение емкости в 30 тысяч раз произошло всего за два десятилетия. И эта история едва ли уникальна: повсюду в мире бизнесмены, правительства и частные лица ощутили рост своих возможностей по хранению данных. Как цивилизация, мы используем эту новую возможность для хранения все большего количества незначительных подробностей нашего будничного существования. Мы построили мировую
инфосферу[datasphere]
– массив информации, описывающей Землю и наши действия на ней.
Построение мировой инфосферы – трехшаговый процесс, которому мы уже слепо следуем, не принимая во внимание его влияние на будущее приватности. Сначала индустриальное общество создало новые возможности для хранения данных. Затем мы чрезвычайно упростили автоматическую запись информации в компьютеры. Последний шаг – упорядочение этой информации в глобальной базе данных, из которой она может быть легко получена при необходимости в любой момент.
Поскольку ежедневные события, происходящие в нашей жизни, систематически записываются в машиночитаемой форме, эта информация начинает жить сама по себе. Для нее находятся новые применения. Если мы не сделаем шаг назад и не остановим сбор и выпуск данной информации, то вскоре получим мир, в котором каждое мгновение и каждое наше действие постоянно «берутся на карандаш».
Шаг 1: делаем информацию собираемой
Первый шаг на пути построения глобальной инфосферы – создание хорошей системы сбора информации. Представим лес: сами по себе деревья не несут информации. Но если мы пройдем по лесу, пронумеруем деревья, установим их возраст и высоту, запишем точное местоположение, то создадим набор данных, представляющих интерес как для специалистов по окружающей среде, так и для деревообрабатывающей промышленности.
Первую наглядную иллюстрацию описанного шага я получил в 1988 году во время посещения расположенного рядом с Бостоном завода BASF по производству флоппи-дисков. Я узнал, что в процессе изготовления каждый диск маркируется специальным кодом –
номером лота.Возьмите любую дискету, и вы, скорее всего, увидите на обратной стороне эти коды: А2С5114В, S2078274 или 01S1406. Эти коды идентифицируют производителя диска, завод, конкретный аппарат, на котором диск был сделан, дату и время начала производства этого лота. Иногда информация кодируется непосредственно в виде чисел, иногда это просто ссылка на запись в учетной книге или системе контроля качества. В любом случае, для декодирования номера лота необходимо обладать специальной информацией, которой производители редко делятся с общественностью.
Изначальная цель нанесения этих кодов заключалась в облегчении процесса контроля качества. При обнаружении дефектного диска производитель по номеру лота может легко определить его происхождение. Просмотрев учетные записи на заводе, инженер по контролю качества может очень точно выявить оборудование, вызвавшее проблему, что является первым шагом по предотвращению брака в дальнейшем. В конечном счете это сберегает деньги фирмы и ее репутацию.
Как только вы узнаете, как распознавать номера лотов, вы вскоре начнете замечать их повсюду: на обертках конфет, бутылочках с лекарствами, крышке фонарика. Некоторые объекты настолько важны, что каждый из них получает свой уникальный номер, который в этом случае называется
серийным номером.Переверните мышку, присоединенную к вашему компьютеру, и вы найдете на ней такой номер. Другой серийный номер нанесен на сам компьютер, а также на большое число отдельных компонентов внутри него. Все это несколько забавно. На заре индустриальной революции одной из самых сложных технических проблем, с которой столкнулись инженеры, было производство функционально идентичных, взаимозаменяемых частей. Сегодня мы настолько хорошо научились делать вещи неотличимыми друг от друга, что должны наносить на каждую уникальный код, чтобы различать их.
Номера лотов и серийные номера служат одной фундаментальной цели: делая похожие вещи отличимыми друг от друга, номера позволяют фиксировать историю каждой вещи. Однажды нанесенные, эти номера могут быть использованы не только для простого контроля качества: серийные номера и номера лотов все шире используются в деятельности правоохранительных органов.
Номера лотов являются безусловным доказательством, например, при расследовании случаев подделки товаров. Если поддельные продукты в разных магазинах принадлежат к одному лоту, скорее всего, «левая» партия была выпущена прямо на предприятии. Если же они все из разных лотов, т. е. как бы произведены на разных фабриках, то почти очевидно, что подделка имела место прямо в магазине или кустарным способом.
Одним из самых удачных примеров маркировки является идентификационный номер транспортного средства [Vehicle Identification Number, VIN], – 17-символьный код, наносимый на приборную панель, двигатель и мост каждого выпускаемого в мире автомобиля. Как рассказал Томас Кар [Thomas Carr], менеджер по обеспечению безопасности пассажиров Американской ассоциации производителей автотранспорта [American Automobile Manufacturer's Association], VIN был создан в 1970-е годы коалицией производителей автомобилей и правительствами, стремящимися к международной стандартизации.
Первые 16 символов VIN несут информацию о производителе, стране изготовления, марке и модели автомобиля, заводе, где происходила сборка, годе выпуска, ограничениях для этого автомобиля, типе трансмиссии и используемом заднем мосте для грузовиков, а также 6-значный последовательный код.
Последний символ VIN имеет специальное значение. Это так называемая контрольная цифра. Сам по себе он не несет никакой информации, а рассчитывается из остальных символов. Эта цифра дает возможность верифицировать VIN лишь по нему самому, позволяя компьютеру автоматически определять большое число опечаток, таких как случайная перемена символов местами или нажатие смежной клавиши на клавиатуре компьютера. Поскольку VIN является своеобразным ключом, используемым для поиска информации по конкретному автомобилю, чрезвычайно важно, чтобы он был напечатан правильно, объясняет Кар.
VIN используется для отслеживания автомобиля в течение всего процесса производства. После того как автомобиль покидает завод, VIN используется правительством для отслеживания того, кто им владеет, как с целью сбора налогов, так и для помощи в розыске и возвращении законному владельцу угнанного автомобиля. А в последние годы VIN стал выполнять еще одну важную функцию – идентификации автомобиля после взрыва. После взрывов во Всемирном торговом центре в Нью-Йорке
и федеральном здании Murrah в Оклахома-Сити следствию в обоих случаях удалось достаточно быстро найти мосты грузовиков, использованных в преступлении. Нанесенный на мосты VIN позволил установить владельцев машин, что, в свою очередь, позволило найти, кто их арендовал, и выйти, таким образом, на самих подрывников.
Шаг 2: делаем информацию машиночитаемой
Автоматический сбор данных – второй большой шаг, необходимый для создания инфосферы. Автоматизированные системы считывают порции информации и помещают их непосредственно в компьютер, без участия человека. Несмотря на то что автоматизированные системы могут быть достаточно дороги в установке, их функционирование приводит к существенному удешевлению процесса сбора данных, предоставляет возможность создавать огромные массивы информации и поддерживать их в актуальном состоянии. В конечном счете, когда основные игроки рынка начнут переходить на использование автоматизированных систем, остальные сразу же последуют за ними.
PSN корпорации Intel
Фирма Intel неожиданно внедрила серийные номера процессоров [Processor Serial Number, PSN] в микропроцессорах Pentium III. Изначально эти номера были разработаны для идентификации «разогнанных» процессоров (т. е. когда процессор с тактовой частотой 500 мегагерц продавался как 600-мегагерцовый чип) и для облегчения отслеживания перемещения компьютеров в крупных организациях. Когда высшее руководство узнало об этой возможности, PSN были преподнесены как решение для электронной коммерции: Intel предложила web-сайтам использовать специальное программное обеспечение для считывания PSN клиентских компьютеров через Интернет. Когда в январе 1999 года PSN были анонсированы, Intel сделала акцент на их применимости в электронной коммерции, а не как средства активного слежения. Буквально через неделю несколько групп пользователей организовали бойкот микропроцессора, справедливо предположив, что, скорее всего, PSN будут применяться для отслеживания перемещений пользователей по сайтам Интернета. Тем временем известный эксперт в области криптографии Брюс Шнайер [Bruce Schneier] опубликовал разгромную статью, в которой подверг PSN резкой критике, так как не существовало безопасного способа считывания этих номеров. Он писал:
Когда web-сервер запрашивает идентификатор процессора, он не может узнать, является ли полученное в ответ число истинным или поддельным. Аналогично, когда какая-нибудь программа запрашивает PSN, она не может достоверно знать, действительно ли ей возвращен реальный идентификатор или специальным образом модифицированная операционная система перехватила вызов и вернула поддельное число. Поскольку Intel не озаботилась параллельным созданием безопасного способа считывания идентификатора, безопасность нарушить очень легко.
Американская банковская система, в числе крупнейших секторов экономики, одной из первых перешла на использование машиночитаемых кодов. В 1963 году некоторые банки начали печатать чеки с использованием специальных магнитных чернил, что позволило компьютерам автоматически считывать 9-значный код банка, номера счетов и номера чеков, отпечатанные внизу каждого чека. Это была замечательная идея: к 1969 году 90 % чеков в США печатались блестящими черными цифрами, существенно снижая время, необходимое на их обработку.
В 1970-е годы банковская индустрия стала помещать на кредитные карты магнитную полосу, что позволяло считывать информацию проводя картой по считывателю. До этого информация с карты вводилась в компьютер вручную, потом переводилась на слип с использованием копировальной бумаги и ролика. Другие отрасли гораздо медленнее двигались в сторону автоматически считывающих информацию систем. Только в середине 1990-х годов General Motors стала дополнительно наносить на таблички с VIN-кодами машиночитаемый штрих-код. В отличие от старого способа, когда VIN мог быть прочитан только человеком, штрих-код мог считываться высокопроизводительным лазерным сканером с расстояния более шести метров. Быстро появились сторонники нанесения штрих-кодов на VIN. Одним из первых новинкой воспользовалось агентство по прокату автомобилей Avis, начавшее применять лазерные сканеры для автоматической идентификации автомобилей по возвращении их на стоянку. В ближайшие годы машиночитаемый VIN будет иметь все большее значение. Например, городские парковки могут использовать штрих-коды для автоматического открывания ворот постоянным клиентам. Другие компании уже разработали системы технического зрения, которые могут считывать номер стоящего или движущегося автомобиля, и работают над созданием системы, которая могла бы идентифицировать автомобиль на расстоянии.
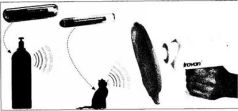
Считыватель номеров автомобилей
Электронные метки служат не только для опознавания машин на открытой дороге. Американская таможня установила считыватели номеров автомобилей на большинстве пограничных пунктов между США и Канадой. Используемая в этих системах видеокамера высокого разрешения позволяет обнаружить и считать номер машины в течение нескольких миллисекунд. Изображенный на рисунке считыватель фирмы Perceptics определяет как сам номер, так и выдавший его штат или округ. В компании говорят: «С нашим считывателем любая магистраль становится открытой книгой». [Фотография любезно предоставлена фирмой Perceptics] Новейшие машиночитаемые метки используются не магнитными или оптическими системами, а сканируются при помощи радиоволн. Эта технология называется RFID (Radio Frequency Identification Device – радиочастотные идентификационные устройства) и состоит из двух частей: крошечного кремниевого чипа с маленькой антенной, называемого
меткой,и
считывателяв форме пистолета. Каждый чип выпускается с уникальным кодом. Достаточно навести считыватель на чип, и на экране высветится соответствующий код. Код передается в присоединенный к считывателю компьютер. Чип не имеет движущихся частей, не нуждается в источниках питания и имеет неограниченный срок службы. Когда вы направляете считыватель на транспондер и нажимаете на кнопку, устройство начинает излучать в сторону чипа радиоволны определенной частоты. Энергия этих радиоволн улавливается антенной транспондера и питает микрочип транспондера со встроенным в него миниатюрным радиопередатчиком. Транспондер в ответ посылает уникальный код чипа (в современных чипах используется 64-битный код) на другой частоте.
Радиочастотные идентификационные устройства (RFID)
Системы на основе радиочастотных идентификационных устройств позволяют встраивать машиночитаемые серийные номера в автомобили и газовые баллоны, вживлять в тело домашних животных и даже в человеческое тело.
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27
|
|