 |
|
Популярные авторы:: Борхес Хорхе Луис :: Азимов Айзек :: Грин Александр :: Чехов Антон Павлович :: Раззаков Федор :: Горький Максим :: Толстой Лев Николаевич :: Ламур Луис :: Херберт Фрэнк :: Бережной Василий Популярные книги:: Дюна (Книги 1-3) :: The Boarding House :: Ползущая тень :: After The Race :: Правила русской орфографии и пунктуации :: Плодотворное разрушение сознания :: За Волгой земли для нас не было :: Основы православной веры :: Секрет государственной важности :: Цветок Колриджа |
Сущность технологии СОМ. Библиотека программистаModernLib.Net / Программирование / Бокс Дональд / Сущность технологии СОМ. Библиотека программиста - Чтение (стр. 7)
Чтобы реализовать управляемый таблицей QueryInterface, необходимо сначала определить, что эта таблица будет содержать. Как минимум, каждый элемент таблицы должен содержать указатель на IID и некое дополнительное состояние, которое позволит реализации найти указатель vptr объекта для запрошенного интерфейса. Хранение указателя функции в каждом элементе таблицы придаст этому способу максимальную гибкость, так как это даст возможность добавлять новые методики поиска интерфейсов к обычному вычислению смещения, которое используется для приведения к базовому классу. Исходный код в приложении к данной книге содержит заголовочный файл inttable.h , который определяет элементы таблицы интерфейсов следующим образом: // inttable.h (book-specific header file) // inttable.h (заголовочный файл, специфический для этой книги) // typedef for extensibility function // typedef для функции расширяемости typedef HRESULT (*INTERFACEFINDER) (void *pThis, DWORD dwData, REFIID riid, void **ppv); // pseudo-function to indicate entry is just offset // псевдофункция для индикации того, что запись просто // является смещением #define ENTRYISOFFSET INTERFACEFINDER(-1) // basic table layout // представление базовой таблицы typedef struct INTERFACEENTRY { const IID * pIID; // the IID to match // соответствующий IID INTERFACEFINDER pfnFinder; // функция finder DWORD dwData; // offset/aux data // данные по offset/aux } INTERFACEENTRY; Заголовочный файл также содержит следующие макросы для создания интерфейсных таблиц внутри определения класса: // Inttable.h (book-specific header file) // Inttable.h (заголовочный файл, специфический для данной книги) #define BASEOFFSET(ClassName, BaseName) \ (DWORD(staticcast #define BEGININTERFACETABLE(ClassName) \ typedef ClassName ITCls;\ const INTERFACEENTRY *GetInterfaceTable(void) {\ static const INTERFACEENTRY table [] = {\ #define IMPLEMENTSINTERFACE(Itf) \ {&IID##Itf,ENTRYISOFFSET,BASEOFFSET(ITCls,Itf)}, #define IMPLEMENTSINTERFACEAS(req, Itf) \ {&IID##req,ENTRYISOFFSET, BASEOFFSET(ITCls, Itf)}, #define ENDINTERFACETABLE() \ { 0, 0, 0 } }; return table; } Все, что требуется, – это стандартная функция, которая может анализировать интерфейсную таблицу в ответ на запрос QueryInterface. Такая функция содержится в файле Inttable.h: // inttable.cpp (book-specific source file) // inttable.h (заголовочный файл, специфический для данной книги) HRESULT InterfaceTableQueryInterface(void *pThis, const INTERFACEENTRY *pTable, REFIID riid, void **ppv) { if (InlineIsEqualGUID(riid, IIDIUnknown)) { // first entry must be an offset // первый элемент должен быть смещением *ppv = (char*)pThis + pTable->dwData; ((Unknown*) (*ppv))->AddRef () ; // A2 return SOK; } else { HRESULT hr = ENOINTERFACE; while (pTable->pfnFinder) { // null fn ptr == EOT if (!pTable->pIID || InlineIsEqualGUID(riid,*pTable->pIID)) { if (pTable->pfnFinder == ENTRYISOFFSET) { *ppv = (char*)pThis + pTable->dwData; ((IUnknown*)(*ppv))->AddRef(); // A2 hr = SOK; break; } else { hr = pTable->pfnFinder(pThis, pTable->dwData, riid, ppv); if (hr == SOK) break; } } pTable++; } if (hr!= SOK) *ppv = 0; return hr; } } Получив указатель на запрошенный объект, InterfaceTableQueryInterface сканирует таблицу в поисках элемента, соответствующего запрошенному IID, и либо добавляет соответствующее смещение, либо вызывает соответствующую функцию. Приведенный выше код использует усовершенствованную версию IsEqualGUID, которая генерирует несколько больший код, но результаты по скорости примерно на 20-30 процентов превышают данные по существующей реализации, которая не управляется таблицей. Поскольку код для InterfaceTableQueryInterface появится в исполняемой программе только один раз, это весьма неплохой компромисс. Очень легко автоматизировать поддержку СОМ для любого класса C++, основанную на таком табличном управлении, простым использованием С-препроцессора. Следующий фрагмент из заголовочного файла impunk.h определяет QueryInterface, AddRef и Release для объекта, использующего интерфейсные таблицы и расположенного в динамически распределяемой области памяти: // impunk.h (book-specific header file) // impunk.h (заголовочный файл, специфический для данной книги) // AUTOLONG is just a long that constructs to zero // AUTOLONG – это просто long, с конструктором, // устанавливающим значение в О struct AUTOLONG { LONG value; AUTOLONG (void) : value (0) {} }; #define IMPLEMENTUNKNOWN(ClassName) \ AUTOLONG mcRef; \ STDMETHODIMP QueryInterface(REFIID riid, void **ppv){ \ return InterfaceTableQueryInterface(this, \ GetInterfaceTable(), riid, ppv); \ } \ STDMETHODIMP(ULONG) AddRef(void) { \ return InterlockedIncrement(&mcRef.value); \ } \ STDMETHODIMP(ULONG) Release(void) { \ ULONG res = InterlockedDecrement(&mcRef.value) ; \ if (res == 0) \ delete this; \ return res; \ } Настоящий заголовочный файл содержит дополнительные макросы для поддержки объектов, не находящихся в динамически распределяемой области памяти. Для реализации примера PugCat, уже встречавшегося в этой главе, необходимо всего лишь удалить текущие реализации QueryInterface, AddRef и Release и добавить соответствующие макросы: class PugCat : public IPug, public ICat { protected: virtual ~PugCat(void); public: PugCat(void); // IUnknown methods // методы IUnknown IMPLEMENTUNKNOWN (PugCat) BEGININTERFACETABLE(PugCat) IMPLEMENTSINTERFACE(IPug) IMPLEMENTSINTERFACE(IDog) IMPLEMENTSINTERFACEAS(IAnimal,IDog) IMPLEMENTSINTERFACE(ICat) ENDINTERFACETABLE() // IAnimal methods // методы IAnimal STDMETHODIMP Eat(void); // IDog methods // методы IDog STDMETHODIMP Bark(void); // IPug methods // методы IPug STDMETHODIMP Snore(void); // ICat methods // методы ICat STDMETHODIMP IgnoreMaster(void); }; Когда используются эти макросы препроцессора, для поддержки IUnknown не требуется никакого дополнительного кода. Все, что осталось сделать, это реализовать текущие методы интерфейса, которые делают этот класс уникальным. Типы данных Все интерфейсы СОМ должны быть определены в IDL. IDL позволяет описывать довольно сложные типы данных в стиле, не зависящем от языка и платформы. Рисунок 2.6 показывает базовые типы, которые поддерживаются IDL, и их отображения в языки С, Java и Visual Basic. Целые и вещественные типы не требуют объяснений. Первые «интересные» типы данных, встречающиеся при программировании в СОМ, – это символы и строки.  Все символы в СОМ представлены с использованием типа данных OLECHAR. Для Windows NT, Windows 95, Win32s и Solaris OLECHAR – это просто typedef для типа данных С wchar_t. Специфика других платформ описана в соответствующих документациях. Платформы Win32 используют тип данных wchar_t для представления 16-битных символов Unicode[1]. Поскольку типы указателей в IDL созданы так, что указывают на одиночные переменные, а не на массивы, то IDL вводит атрибут [string], чтобы подчеркнуть, что указатель указывает на массив-строку с завершающим нулем: HRESULT Method([in, string] const OLECHAR *pwsz); Для определения строк и символов, совместимых с OLECHAR, в СОМ введен макрос OLESTR, который приписывает букву L перед строковой или символьной константой, информируя таким образом компилятор о том, что эта константа имеет тип wchar_t. Например, правильным будет такой способ инициализировать указатель OLECHAR с помощью строкового литерала: const OLECHAR *pwsz = OLESTR(«Hello»); Под Win32 или Solaris это эквивалентно const wchar_t *pwsz = L"Hello"; Первый вариант предпочтительней, так как он будет надежно компилироваться на всех платформах. Поскольку часто возникает необходимость копировать строки на основе типа wchar_t в обычные буфера на основе char, то динамическая библиотека С предлагает две процедуры для преобразования типов: size_t mbstowcs(wchar_t *pwsz, const char *psz, int cch); size_t wcstombs(char *psz, const wchar_t *pwsz, int cch); Эти две процедуры работают аналогично динамической С-процедуре strncpy, за исключением того, что в эти процедуры как часть операции копирования включено расширение или сужение строки. Следующий код показывает, как параметр метода, размещенный в OLECHAR, можно скопировать в элемент данных, размещенный в char: class BigDog : public ILabrador { char m_szName[1024] ; public: STDMETHODIMP SetName(/* [in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверяем переполнение буфера или неверное преобразование if (cb == sizeof(m_szName) || cb == (size_t)-1) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } }; Этот код является довольно простым, хотя программист должен осознавать, что используются два различных типа символов. Несколько более сложный (и чаще встречающийся) случай – преобразование между типами данных OLECHAR и TCHAR из Win32. Так как OLECHAR условно компилируется как char или wchar_t, то при реализации метода необходимо должным образом рассмотреть оба сценария: class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName( /*[in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; #ifdef UNICODE // Unicode build (TCHAR == wchar_t) // конструкция Unicode (TCHAR == wchar_t) wcsncpy(m_szName, pwsz, 1024); // check for buffer overflow // проверка на переполнение буфера if (m_szName[1023] != 0) { m_szName[0] = 0; hr = E_INVALIDARG; } #else // Non-Unicode build (TCHAR == char) // не является конструкцией Unicode (TCHAR == char) size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверка переполнения буфера или ошибки преобразования if (cb == sizeof(m_szName) || cb == (size_t)-1) { m_szName[0] =0; hr = E_INVALIDARG; } #endif return hr; } }; Очевидно, операции с преобразованиями OLECHAR в TCHAR значительно сложнее. Но, к сожалению, это самый распространенный сценарий при программировании в СОМ на базе Win32. Одним из подходов к упрощению преобразования текста является применение системы типов C++ и использование перегрузки функций для выбора нужной строковой процедуры, построенной на типах параметров. Заголовочный файл ustring.h из приложения к этой книге содержит семейство библиотечных строковых процедур, аналогичных стандартным библиотечным процедурам С, которые находятся в файле string.h. Например, функция strncpy имеет четыре соответствующих процедуры, зависящие от каждого из параметров, которые могут быть одного из двух символьных типов (wchar_t или char): // from ustring.h (book-specific header) // из ustring.h (заголовок, специфический для данной книги) inline bool ustrncpy(char *p1, const wchar_t *p2, size_t c) { size_t cb = wcstombs(p1, p2, c); return cb != c && cb != (size_t)-1; }; inline bool ustrncpy(wchar_t *p1, const wchar_t *p2, size_t c) { wcsncpy(p1, p2, c); return p1[c – 1] == 0; }; inline bool ustrncpy(char *p1, const char *p2, size_t c) { strncpy(p1, p2, c); return p1[c – 1] == 0; }; inline bool ustrncpy(wchar_t *p1, const char *p2, size_t c) { size_t cch = mbstowcs(p1, p2, c); return cch != c && cch != (size_t)-1; } Отметим, что для любого сочетания типов идентификаторов может быть найдена соответствующая перегруженная функция ustrncpy, причем результат показывает, была или нет вся строка целиком скопирована или преобразована. Поскольку эти процедуры определены как встраиваемые (inline) функции, их использование не внесет никаких затрат при выполнении. С этими процедурами предыдущий фрагмент кода станет значительно проще и не потребует условной компиляции: class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName(/* [in,string] */ const OLECHAR *pwsz) { HRESULT hr = S_OK; // use book-specific overloaded ustrncpy to copy or convert // используем для копирования и преобразования // перегруженную функцию ustrncpy, специфическую для данной книги if (!ustrncpy(m_szName, pwsz, 1024)) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } }; Соответствующие перегруженные функции для процедур strlen, strcpy и strcat также включены в заголовочный файл ustring.h. Использование перегрузки библиотечных функций для копирования строк из одного буфера в другой, как это показано выше, обеспечивает лучшее качество исполнения, уменьшает размер кода и непроизводительные издержки программиста. Однако часто возникает ситуация, когда одновременно используются СОМ и API-функции Win32, что не дает возможности применить эту технику. Рассмотрим следующий фрагмент кода, читающий строку из элемента редактирования и преобразующий ее в IID: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; // call a TCHAR-based Win32 routine // вызываем TCHAR-процедуру Win32 GetWindowText(hwnd, szEditText, 1024); // call an OLECHAR-based СОМ routine // вызываем OLECHAR-процедуру СОМ return IIDFromString(szEditText, &riid); } Допуская, что этот код скомпилирован с указанным символом С-препроцессора UNICODE; он работает безупречно, так как TCHAR и OLECHAR являются просто псевдонимами wchar_t и никакого преобразования не требуется. Если же функция скомпилирована с версией Win32 API, не поддерживающей Unicode, то TCHAR является псевдонимом для char, и первый параметр для IIDFromString имеет неправильный тип. Чтобы решить эту проблему, нужно провести условную компиляцию: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); #ifdef UNICODE return IIDFromString(szEditText, &riid); #else OLECHAR wszEditText[l024]; ustrncpy(wszEditText, szEditText, 1024); return IIDFromString(wszEditText, &riid); #endif } Хотя этот фрагмент и генерирует оптимальный код, очень утомительно применять эту технику всякий раз, когда символьный параметр имеет неверный тип. Можно справиться с этой проблемой, если использовать промежуточный (shim) класс с конструктором, принимающим в качестве параметра любой тип символьной строки. Этот промежуточный класс должен также содержать в себе операторы приведения типа, что позволит использовать его в обоих случаях: когда ожидается const char * или const wchar_t *. В этих операциях приведения промежуточный класс либо выделяет резервный буфер и производит необходимое преобразование, либо просто возвращает исходную строку, если преобразования не требовалось. Деструктор промежуточного класса может затем освободить все выделенные буферы. Заголовочный файл ustring.h содержит два таких промежуточных класса: _U и _UNCC. Первый предназначен для нормального использования; второй используется с функциями и методами, тип аргументов которых не включает спецификатора const[2] (таких как IIDFromString). При возможности применения двух промежуточных классов предыдущий фрагмент кода может быть значительно упрощен: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); // use _UNCC shim class to convert if necessary // используем для преобразования промежуточный класс _UNCC, // если необходимо return IIDFromString(_UNCC(szEditText), &riid); } Заметим, что не требуется никакой условной компиляции. Если код скомпилирован с версией Win32 с поддержкой Unicode, то класс _UNCC просто пропустит исходный буфер через свой оператор приведения типа. Если же код компилируется с версией Win32, не поддерживающей Unicode, то класс _UNCC выделит буфер и преобразует строку в Unicode. Затем деструктор _UNCC освободит буфер, когда операция будет выполнена полностью[3]. Следует обсудить еще один дополнительный тип данных, связанный с текстом, – BSTR. Строковый тип BSTR нужно применять во всех интерфейсах, которые предполагается использовать из языков Visual Basic или Java. Строки BSTR являются OLECHAR-строками с префиксом длины (length-prefix) в начале строки и нулем в ее конце. Префикс длины показывает число байт, содержащихся в строке (исключая завершающий нуль) и записан в форме четырехбайтового целого числа, непосредственно предшествующего первому символу строки. Рисунок 2.7 демонстрирует BSTR на примере строки «Hi». Чтобы позволить методам свободно возвращать строки BSTR без заботы о выделении памяти, все BSTR размещены с помощью распределителя памяти, управляемого СОМ. В СОМ предусмотрено несколько API-функций для управления BSTR: 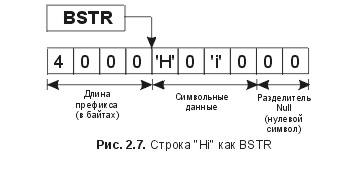 // from oleauto.h // allocate and initialize a BSTR // выделяем память и инициализируем строку BSTR BSTR SysAllocString(const OLECHAR *psz); BSTR SysAllocStringLen(const OLECHAR *psz, UINT cch); // reallocate and initialize a BSTR // повторно выделяем память и инициализируем BSTR INT SysReAllocString(BSTR *pbstr, const OLECHAR *psz); INT SysReAllocStringLen(BSTR *pbstr, const OLECHAR * psz, UINT cch); // free a BSTR // освобождаем BSTR void SysFreeString(BSTR bstr); // peek at length-prefix as characters or bytes // считываем префикс длины как число символов или байт UINT SysStringLen(BSTR bstr); UINT SysStringByteLen(BSTR bstr); При пересылке строк методу в качестве параметров типа [in] вызывающий объект должен заботиться о том, чтобы вызвать SysAllocString прежде, чем запускать сам метод, и чтобы вызвать SysFreeString после того, как метод закончил работу. Рассмотрим следующее определение метода: HRESULT SetString([in] BSTR bstr); Пусть в вызывающей программе уже имеется строка, совместимая с OLECHAR, тогда для того, чтобы преобразовать строку в BSTR до вызова метода, необходимо следующее: // convert raw OLECHAR string to a BSTR // преобразовываем «сырую» строку OLECHAR в строку BSTR BSTR bstr = SysAllocString(OLESTR(«Hello»)); // invoke method // вызываем метод HRESULT hr = p->SetString(bstr); // free BSTR // освобождаем BSTR SysFreeString(bstr); Промежуточный класс для работы с BSTR, _UBSTR, включен в заголовочный файл ustring.h: // from ustring.h (book-specific header file) // из ustring.h (специфический для данной книги заголовочный файл) class _UBSTR { BSTR m_bstr; public: _UBSTR(const char *psz) : m_bstr(SysAllocStringLen(0, strlen(psz))) { mbstowcs(m_bstr, psz, INT_MAX); } _UBSTR(const wchar_t *pwsz) : m_bstr(SysAllocString(pwsz)) { } operator BSTR (void) const { return m_bstr; } ~_UBSTR(void) { SysFreeString(m_bstr); } }; При наличии такого промежуточного класса предыдущий фрагмент кода значительно упростится: // invoke method // вызываем метод HRESULT hr = p->SetString(_UBSTR(OLESTR(«Hello»))); Заметим, что в промежуточном классе UBSTR могут быть в равной степени использованы строки типов char и wchar_t. При передаче из метода строк через параметры типа [out] объект обязан вызвать SysAllocString, чтобы записать результирующую строку в буфер. Затем вызывающий объект должен освободить буфер путем вызова SysFreeString. Рассмотрим следующее определение метода: HRESULT GetString([out, retval] BSTR *pbstr); При реализации метода потребуется создать новую BSTR-строку для возврата вызывающему объекту: STDMETHODIMP MyClass::GetString(BSTR *pbstr) { *pbstr = SysAllocString(OLESTR(«Coodbye!»)) ; return S_OK; } Теперь вызывающий объект должен освободить строку сразу после того, как она скопирована в управляемый приложением строковый буфер: extern OLECHAR g_wsz[]; BSTR bstr = 0; HRESULT hr = p->GetString(&bstr); if (SUCCEEDED(hr)) { wcscpy(g_wsz, bstr); SysFreeString(bstr); } Тут нужно рассмотреть еще один важный аспект BSTR. В качестве BSTR можно передать нулевой указатель, чтобы указать на пустую строку. Это означает, что предыдущий фрагмент кода не совсем корректен. Вызов wcscpy: wcscpy(g_wsz, bstr); должен быть защищен от возможных нулевых указателей: wcscpy (g_wsz, bstr ? bstr : OLESTR("")); Для упрощения использования BSTR в заголовочном файле ustring.h содержится простая встраиваемая функция: intline OLECHAR *SAFEBSTR(BSTR b) { return b ? b : OLESTR(""); } Разрешение использовать нулевые указатели в качестве BSTR делает тип данных более эффективным с точки зрения использования памяти, хотя и приходится засорять код этими простыми проверками. Простые типы, показанные на рис. 2.6, могут компоноваться вместе с применением структур языка С. IDL подчиняется правилам С для пространства имен тегов (tag namespace). Это означает, что большинство IDL-определений интерфейсов либо используют операторы определения типа (typedef): typedef struct tagCOLOR { double red; double green; double blue; } COLOR; HRESULT SetColor([in] const COLOR *pColor); либо должны использовать ключевое слово struct для квалификации имени тега: struct COLOR { double red; double green; double blue; }; HRESULT SetColor([in] const struct COLOR *pColor); Первый вариант предпочтительней. Простые структуры, подобные приведенной выше, можно использовать как из Visual Basic, так и из Java. Однако в то время, когда пишется эта книга, текущая версия Visual Basic может обращаться только к интерфейсам, использующим структуры, но она не может быть использована для реализации интерфейсов, в которых структуры являются параметрами методов. IDL и СОМ поддерживают также объединения (unions). Для обеспечения однозначной интерпретации объединения IDL требует, чтобы в этом объединении имелся дискриминатор (discriminator), который показывал бы, какой именно член объединения используется в данный момент. Этот дискриминатор должен быть целого типа (integral type) и должен появляться на том же логическом уровне, что и само объединение. Если объединение объявлено вне области действия структуры, то оно считается неинкапсулированным (nonencapsulated): union NUMBER { [case(1)] long i; [case(2)] float f; }; Атрибут [case] применен для установления соответствия каждого члена объединения своему дискриминатору. Для того чтобы связать дискриминатор с неинкапсулированным объединением, необходимо применить атрибут [switch_is]: HRESULT Add([in, switch_is(t)] union NUMBER *pn, [in] short t); Если объединение заключено вместе со своим дискриминатором в окружающую структуру, то этот составной тип (aggregate type) называется инкапсулированным, или размеченным объединением (discriminated union): struct UNUMBER { short t; [switch_is(t)] union VALUE { [case(1)] long i; [case(2)] float f; }; }; СОМ предписывает для использования с Visual Basic одно общее размеченное объединение. Это объединение называется VARIANT[4] и может хранить объекты или ссылки на подмножество базовых типов, поддерживаемых IDL. Каждому из поддерживаемых типов присвоено соответствующее значение дискриминатора: VT_EMPTY nothing VT_NULL SQL style Null VT_I2 short VT_I4 long VT_R4 float VT_R8 double VT_CY CY (64-bit currency) VT_DATE DATE (double) VT_BSTR BSTR VT_DISPATCH IDispatch * VT_ERROR HRESULT VT_BOOL VARIANT_BOOL (True=-1, False=0) VT_VARIANT VARIANT * VT_UNKNOWN IUnknown * VT_DECIMAL 16 byte fixed point VT_UI1 opaque byte Следующие два флага можно использовать в сочетании с вышеприведенными тегами, чтобы указать, что данный вариант (variant) содержит ссылку или массив данного типа: VT_ARRAY Указывает, что вариант содержит массив SAFEARRAY VT_BYREF Указывает, что вариант является ссылкой СОМ предлагает несколько API-функций для управления VARIANT: // initialize a variant to empty // обнуляем вариант void VariantInit(VARIANTARG * pvarg); // release any resources held in a variant // освобождаем все ресурсы, используемые в варианте HRESULT VariantClear(VARIANTARG * pvarg); // deep-copy one variant to another // полностью копируем один вариант в другой HRESULT VariantCopy(VARIANTARG * plhs, VARIANTARG * prhs); // dereference and deep-copy one variant into another // разыменовываем и полностью копируем один вариант в другой HRESULT VariantCopyInd(VARIANT * plhs, VARIANTARG * prhs); // convert a variant to a designated type // преобразуем вариант к указанному типу HRESULT VariantChangeType(VARIANTARG * plhs, VARIANTARG * prhs, USHORT wFlags, VARTYPE vtlhs); // convert a variant to a designated type // преобразуем вариант к указанному типу (с явным указанием кода локализации) HRESULT VariantChangeTypeEx(VARIANTARG * plhs, VARIANTARG * prhs, LCID lcid, USHORT wFlags, VARTYPE vtlhs); Эти функции значительно упрощают управление VARIANT'ами. Чтобы понять, как используются эти API-функции, рассмотрим метод, принимающий VARIANT в качестве [in]-параметра: HRESULT UseIt([in] VARIANT var); Следующий фрагмент кода демонстрирует, как передать в этот метод целое число: VARIANT var; 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 |
|||||||