 |
|
Популярные авторы:: Борхес Хорхе Луис :: Азимов Айзек :: Грин Александр :: Чехов Антон Павлович :: Раззаков Федор :: Горький Максим :: Толстой Лев Николаевич :: Ламур Луис :: Херберт Фрэнк :: Бережной Василий Популярные книги:: Дюна (Книги 1-3) :: The Boarding House :: Ползущая тень :: After The Race :: Правила русской орфографии и пунктуации :: Плодотворное разрушение сознания :: За Волгой земли для нас не было :: Основы православной веры :: Секрет государственной важности :: Цветок Колриджа |
Сущность технологии СОМ. Библиотека программистаModernLib.Net / Программирование / Бокс Дональд / Сущность технологии СОМ. Библиотека программиста - Чтение (стр. 5)
Эти два макроса используют тот факт, что при трактовке НRESULT как целого числа со знаком бит серьезности ошибки он является также знаковым битом. Заголовки SDK содержат определения всех стандартных HRESULT. Эти HRESULT имеют символические имена, соответствующие трем компонентам HRESULT, и используются в следующем формате: Например, HRESULT с именем STG_S_CONVERTED показывает, что кодом устройства является FACILITY_STORAGE. Это означает, что результат относится к структурированному хранилищу (Structured Storage) или к персистентности (Persistence). Код серьезности ошибки – SEVERITY_SUCCESS. Это означает, что вызов смог успешно выполнить операцию. Третья составляющая – CONVERTED – означает, что в данном случае было произведено преобразование базового файла для поддержки структурированного хранилища. HRESULT-значения, являющиеся универсальными и не привязанными к определенной технологии, используют FACILITY_NULL, и их символическое имя не содержит префикса кода устройства. Вот некоторые стандартные имена HRESULT-значений с кодом FACILITY_NULL: S_OK – успешная нормальная операция S_FALSE – используется для возвращения логического false в случае успеха E_FAIL – общий сбой E_NOTIMPL – метод не реализован E_UNEXPECTED – метод вызван в неподходящее время FACILITY_ITF используется в специфически интерфейсных HRESULT-значениях и является в то же время единственным допустимым кодом устройства для HRESULT, определяемых пользователем. При этом значения FACILITY_ITF должны быть уникальными в контексте каждого отдельного интерфейса. Стандартные заголовки определяют макрос MAKE_HRESULT для определения пользовательского HRESULT из трех необходимых полей: const HRESULT CALC_E_IAMHOSED = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0х200 + 15); Для пользовательских HRESULT принято соглашение, что значения информационного кода должны превышать 0х200 , чтобы избежать повторного использования значений, уже задействованных в системных HRESULT -значениях. Хотя это не опасно, таким образом предотвращается повторное использование значений, уже имеющих смысл для стандартных интерфейсов. Например, большинство HRESULT имеют текстовые описания для пользователя, которые можно получить на этапе выполнения с помощью функции API FormatMessage. Выбор HRESULT, не пересекающихся со значениями, определенными в системе, служит гарантией того, что неверные сообщения об ошибках не будут получены. Чтобы позволить методам возвращать логический результат, не имеющий отношения к их физическому HRESULT -значению, язык СОМ IDL поддерживает атрибут параметров retval . Атрибут retval показывает, что соответствующий параметр физического метода в действительности является логическим результатом операции и, если контекст это позволяет, должен быть представлен как результат операции. Рассмотрим IDL-описание следующего метода: HRESULT Method2([in] short arg1, [out, retval] short *parg2); на языке Java это соответствует: public short Method2(short arg1); в то время как Visual Basic дает такое описание метода: Function Method2(arg1 as Integer) As Integer Поскольку C++ не использует поддержку контекста выполнения для обращения к СОМ-интерфейсам, представление этого метода в Microsoft C++ имеет вид: virtual HRESULT stdcall Method2(short arg1, short *parg2) = 0; Это значит, что следующий клиентский код на языке C++: short sum = 10; short s; HRESULT hr = pItf->Method2(20, &s); if (FAILED(hr)) throw hr; sum += s; примерно эквивалентен такому Java-коду: short sum == 10; short s = Itf.Method2(20); sum += s; Если HRESULT, возвращенный методом, сообщает об аварийном результате, то Java Virtual Machine преобразует HRESULT в исключение Java. Во фрагменте кода на языке C++ необходимо проверить вручную HRESULT, возвращенный этим методом, и соответствующим образом обработать этот аварийный результат. Интерфейсы и IDL Определения методов в IDL являются просто аннотированными аналогами С-функций. Определения интерфейсов в IDL требуют расширения по сравнению с С, так как С не имеет встроенной поддержки этого понятия. Определение интерфейса в IDL начинается с ключевого слова interface. Это определение состоит их четырех частей: имя интерфейса, базовое имя интерфейса, тело интерфейса и атрибуты интерфейса. Тело интерфейса представляет собой просто набор определений методов и операторов определения типов: [ attribute1, attribute2, …] interface IThisInterface : IBaseInterface { typedef1; typedef2; : : method1; method2; } Каждый интерфейс СОМ должен иметь как минимум два атрибута IDL. Атрибут [object] служит признаком того, что данный интерфейс является СОМ-, а не DCE-интерфейсом. Второй обязательный атрибут указывает на физическое имя интерфейса (в предшествующем IDL-фрагменте IThisInterface является логическим именем интерфейса). Чтобы понять, почему СОМ-интерфейсы требуют физическое имя, отличное от логического имени интерфейса, рассмотрим следующую ситуацию. Два разработчика независимо друг от друга решили создать интерфейс, моделирующий ручной калькулятор. Два их определения интерфейса будут, вероятно, похожими, будучи заданными в общей проблемной области, но скорее всего фактический порядок определений методов и, возможно, сигнатур методов могут в чем-то различаться. Несмотря на это, оба разработчика, вероятно, выберут одно и то же логическое имя: ICalculator. Клиентская программа на машине какого-нибудь конечного пользователя может реализовать определение интерфейса от первого разработчика, а запустить объект, созданный вторым. Поскольку оба интерфейса имеют одно и то же логическое имя, то если клиент запросит объект для поддержки ICalculator, просто использовав строку «ICalculator», объект ответит на запрос возвратом ненулевого указателя интерфейса. Однако представление клиента о том, на что похож ICalculator, вступит в конфликт с тем, какое представление о нем имеет этот объект, и результирующий указатель будет не тем, которого ожидает клиент. Ведь эти два интерфейса могут быть совершенно разными, несмотря на то, что оба используют одно и то же логическое имя. Чтобы исключить коллизию имен, всем СОМ-интерфейсам на этапе проектирования назначается уникальное двоичное имя, которое является физическим именем интерфейса. Эти физические имена называются глобально уникальными идентификаторами (Globally Unique Identifiers – GUIDs), что рифмуется со словом squids [1]. GUID используются в СОМ повсюду для именования статических сущностей, таких как интерфейсы или реализации. GUID являются чрезвычайно большими 128-битными числами, что гарантирует их уникальность как во времени, так и в пространстве. GUID в СОМ основаны на универсальных уникальных идентификаторах (Universally Unique Identifiers – UUIDs), используемых в DCE RPC. При использовании GUID для именования СОМ-интерфейсов их часто называют идентификаторами интерфейса (Interface IDs – IIDs). Реализации в СОМ также именуются с помощью GUID, и в этом случае GUID называются идентификаторами класса (Class IDs – CLSIDs ). Будучи представленными в текстовой форме, GUID всегда имеют следующий канонический вид: BDA4A270-A1BA-11d0-8C2C-0080C73925BA Эти 32 шестнадцатеричные цифры представляют 128-битное значение GUID. Именование интерфейсов и реализации с помощью GUID важно для предотвращения коллизий между разными компонентами. Для создания нового GUID в СОМ имеется API-функция, которая использует децентрализованный алгоритм уникальности для генерирования нового 128-битного числа, которое никогда больше не встретится в природе: HRESULT CoCreateGuid(GUID *pguid); Алгоритм, задействованный в функции CoCreateGuid, использует локальный сетевой интерфейсный адрес машины, текущее машинное время и два постоянных счетчика для компенсации точности часов и нестандартных изменении в них (таких, как переход на летнее время или ручная коррекция системных часов). Если данная машина не имеет сетевого интерфейса, то синтезируется статистически уникальная величина и CoCreateGuid возвращает особого вида HRESULT, показывающий, что данная величина является глобально уникальной только статистически и может считаться таковой только при использовании на локальной машине. Хотя прямой вызов функции CoCreateGuid иногда полезен, большинство разработчиков вызывают ее в неявной форме, применяя из SDK программу GUIDGEN.EXE. На рис. 2.3 показана работа GUIDGEN. GUIDGEN вызывает CoCreateGuid и преобразует полученный GUID в один из четырех форматов, удобных для включения в исходный код на C++ или IDL. При работе в IDL используется четвертый формат (каноническая текстовая форма).  Чтобы связать физическое имя интерфейса с его определением на IDL, используется второй обязательный атрибут интерфейса – [uuid] . Атрибут [uuid] содержит один параметр – каноническую текстовую форму GUID: [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IBaseInterface { HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); } При использовании при программировании на С или C++ физического имени интерфейса IID данного интерфейса представляет собой просто логическое имя интерфейса, предшествуемое префиксом IID_. Например, интерфейс ICalculator будет иметь IID, которым можно программно манипулировать, используя сгенерированную IDL константу IID_ICalculator. Для предотвращения коллизий между символическими именами интерфейсов можно использовать пространство имен C++. Поскольку лишь немногие из компиляторов C++ могут поддерживать 128-битные числа, СОМ определяет С-структуру для представления 128-битовой величины GUID и предлагает псевдонимы для типов IID и CLSID с использованием следующего определения типов: typedef struct GUID { DWORD Data1; WORD Data2; WORD Data3; BYTE Data4[8]; } GUID; typedef GUID IID; typedef GUID CLSID; Внутренняя структура GUID для большинства программистов несущественна, так как единственная значимая операция, которую можно выполнить с GUID, – это проверка их эквивалентности. Для обеспечения эффективной передачи величин GUID как аргументов функций СОМ предусматривает также постоянные псевдонимы для ссылок (constant reference aliases) для каждого типа GUID: #define REFGUID const GUID& #define REFIID const IID& #define REFCLSID const CLSID& Чтобы иметь возможность сравнивать величины GUID, СОМ обеспечивает функции эквивалентности и перегружает операторы == и != для постоянных ссылок GUID: inline BOOL IsEqualGUID(REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); } #def1ne IsEqualIID(r1, r2) IsEqualGUID((r1) , (r2)) #define IsEqualCLSID(r1, r2) IsEqualGUID((r1), (r2)) inline BOOL operator == (REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); } inline BOOL operator != (REFGUID r1, REFGUID r2) { return !(r1 == r2); } Фактические заголовки SDK содержат условно компилируемые совместимые с С версии определений типа, макросов и встраиваемых функций, как показано выше. Поскольку показано, что представления имен интерфейсов на этапе выполнения являются GUID, а не строками; это означает, что метод Dynamic_Cast, описанный в предыдущей главе, следует пересмотреть. Действительно, весь интерфейс IЕхtensibleObject должен быть изменен и преобразован в свой аналог IUnknown, совместимый с СОМ. Интерфейс IUnknown СОМ-интерфейс IUnknown имеет то же назначение, что и интерфейс IExtensibleObject, определенный в предыдущей главе. Последняя версия IExtensibleObject, появившаяся в конце предыдущей главы, имеет вид: class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void DuplicatePointer(void) = 0; virtual void DestroyPointer(void) = 0; } Для определения типа на этапе выполнения был применен метод Dynamic_Cast, аналогичный оператору C++ dynamic_cast. Для извещения объекта о том, что указатель интерфейса дублировался, использовался метод DuplicatePointer. Для сообщения объекту, что указатель интерфейса уничтожен и все используемые им ресурсы могут быть освобождены, был применен метод DestroyPointer. Вот как выглядит определение IUnknown на C++: extern "С" const IID IID_IUnknown: interface IUnknown { virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, void **ppv) = 0; virtual ULONG STDMETHODCALLTYPE AddRef(void) = 0; virtual ULONG STDMETHODCALLTYPE Release(void) = 0; }; Заголовочные файлы SDK дают псевдоним interface ключевому слову C++ struct, используя препроцессор С. Поскольку интерфейсы в СОМ определены не как классы, а как структуры, то для того, чтобы сделать методы интерфейса общедоступными, ключевое слово public не требуется. Чтобы создать для целевой платформы СОМ-совместимые стековые фреймы, необходим макрос STDMETHODCALLTYPE. Если целевыми являются платформы Win32, то при использовании компилятора Microsoft C++ этот макрос раскрывается в _stdcall. IUnknown функционально эквивалентен IExtensibleObject. Метод QueryInterface используется для динамического определения типа и аналогичен С++-оператору dynamic_cast. Метод AddRef используется для сообщения объекту, что указатель интерфейса дублирован. Метод Release используется для сообщения объекту, что указатель интерфейса уничтожен и все ресурсы, которые объект поддерживал от имени клиента, могут быть отключены. Главное различие между IUnknown и интерфейсом, определенным в предыдущей главе, заключается в том, что IUnknown использует идентификаторы GUID, а не строки для идентификации типов интерфейса на этапе выполнения. IDL-определение IUnknown можно найти в файле unknwn.idl из директории SDK, содержащей заголовочные файлы: // unknwn.idl – system IDL file // unknwn.idl – системный файл IDL [ local, object, uuid (00000000-0000-0000-C000-000000000046) ] interface IUnknown { HRESULT QueryInterface([in] REFIID riid, [out] void **ppv); ULONG AddRef(void); ULONG Release(void); } Атрибут local подавляет генерирование сетевого кода для этого интерфейса. Этот атрибут необходим для того, чтобы смягчить требования СОМ о том, что все методы при вызове с удаленных машин должны возвращать HRESULT. Как будет показано в следующих главах, интерфейс IUnknown трактуется особым образом при работе с удаленными объектами. Заметим, что фактические, то есть использующиеся на практике IDL-описания интерфейсов, которые содержатся в заголовках SDK, немного отличаются от определений, данных в этой книге. Фактические определения часто содержат дополнительные атрибуты для оптимизации генерируемого сетевого кода, которые не имеют отношения к нашему обсуждению. В случае сомнений обратитесь за полными определениями к последней версии заголовочных файлов SDK. Интерфейс IUnknown является родительским для всех СОМ-интерфейсов. IUnknown – единственный интерфейс СОМ, который не наследует от другого интерфейса. Любой другой допустимый интерфейс СОМ должен быть прямым потомком IUnknown или какого-нибудь другого допустимого интерфейса СОМ, который, в свою очередь, должен сам наследовать или прямо от IUnknown, или от какого-нибудь другого допустимого интерфейса СОМ. Это означает, что на двоичном уровне все интерфейсы СОМ являются указателями на таблицы vtbl, которые начинаются с трех точек входа: QueryInterface, AddRef и Release. Все специфические для интерфейсов методы будут иметь точки входа в vtbl, которые появляются после этих трех общих точек входа. Чтобы наследовать от интерфейса IDL, нужно или определить базовый интерфейс в том же IDL-файле, или использовать директиву import, чтобы сделать внешнее IDL-определение базового интерфейса явным в данной области действия: // calculator.idl [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IUnknown { import «unknwn.idl»; // bring in def. of IUnknown // импортируем определение IUnknown HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); } Оператор import может появляться или внутри определения интерфейса, как показано здесь, или предшествовать описанию интерфейса в глобальной области действия. В любом из этих случаев действия оператора import одинаковы, он может многократно импортировать один IDL-файл без всякого ущерба. Поскольку сгенерированный C/C++ заголовочный файл будет требовать С/С++-версии импортируемого IDL-файла, чтобы обеспечить наследование, оператор import из IDL-файла будет странслирован в команду #include в генерируемом заголовочном С/С++-файле: // calculator.h – generated by MIDL // calculator.h – генерированный MIDL // bring in def. of IUnknown // вводим определения IUnknown #include «unknwn.h» extern "C" const IID IID_ICalculator; interface ICalculator : public IUnknown { virtual HRESULT STDMETHODCALLTYPE Clear(void) = 0; virtual HRESULT STDMETHODCALLTYPE Add(long n) = 0; virtual HRESULT STDMETHODCALLTYPE Sum(long *pn) = 0; } Компилятор MIDL также создаст С-файл, содержащий фактические определения всех GUID, имеющихся в исходном IDL-файле: // calculator_i.с – generated by MIDL const IID IID_ICalculator = { 0xBDA4A270, 0xA1BA, 0x11d0, { 0x8C, 0x2C, 0x00, 0х80, 0хC7, 0х39, 0x25, 0xBA } }; Каждый проект, который будет использовать этот интерфейс, должен или добавить calculator_i.c к своему файлу сборки (makefile), или включить calculator_i.c в один из исходных файлов на С или C++ с использованием препроцессора С. Если это не сделано, то идентификатору IID_ICalculator не будет выделено памяти для его 128-битного значения и проект не будет скомпонован по причине неразрешенных внешних идентификаторов. СОМ не накладывает никаких ограничений на глубину иерархии интерфейсов при условии, что конечным базовым интерфейсом является IUnknown. Нижеследующий IDL является вполне допустимым и корректным для СОМ: import «unknwn.idl»; [object, uuid(DF12E151-A29A-11d0-8C2D-0080C73925BA)] interface IAnimal : IUnknown { HRESULT Eat(void); } [object, uuid(DF12E152-A29A-11d0-8C2D-0080C73925BA)] interface ICat : IAnimal { HRESULT IgnoreMaster(void); } [object, uuid(DF12E153-A29A-11d0-8C2D-0080C73925BA)] interface IDog : IAnimal { HRESULT Bark(void); } [object, uuid(DF12E154-A29A-11d0-8C2D-0080C73925BA)] interface IPug : IDog { HRESULT Snore(void); } [object, uuid(DF12E155-A29A-11d0-8C2D-0080C73925BA)] interface IOldPug : IPug { HRESULT SnoreLoudly(void); } СОМ накладывает одно ограничение на наследование интерфейсов: интерфейсы СОМ не могут быть прямыми потомками более чем одного интерфейса. Следующий фрагмент в СОМ недопустим: [object, uuid(DF12E156-A29A-11d0-8C2D-0080C73925BA)] interface ICatDog : ICat, IDog { // illegal, multiple bases // неверно, несколько базовых интерфейсов HRESULT Meowbark(void); } СОМ запрещает наследование от нескольких интерфейсов по целому ряду причин. Одна из них состоит в том, что двоичное представление результирующего абстрактного базового класса C++ не будет независимым от компилятора. В этом случае СОМ уже не будет являться двоичным стандартом, независимым от разработчика. Другая причина кроется в тесной связи между СОМ и DCE RPC. При ограничении наследования интерфейсов одним базовым интерфейсом преобразование между интерфейсами СОМ и интерфейсными векторами DCE RPC вполне однозначно. В конце концов, отсутствие поддержки нескольких базовых интерфейсов не является ограничением, так как каждая реализация может выбрать для открытия столько интерфейсов, сколько пожелает. Это означает, что основанный на СОМ Cat/Dog по-прежнему допустим на уровне реализации: class CatDog : public ICat, public IDog { // ... }; Клиент, желающий трактовать объект как Cat/Dog, просто использует QueryInterface для привязки к объекту обоих типов указателей. Если один из вызовов QueryInterface не достигает успеха, то данный объект не является Cat/Dog и клиент может справляться с этим, как сумеет. Поскольку реализации могут открывать несколько интерфейсов, то запрет для интерфейсов наследовать более чем от одного интерфейса является лишь небольшой потерей в смысле семантической информации или информации о типе. СОМ поддерживает стандарт обозначений, который показывает, какие интерфейсы доступны из объекта. Этот способ придерживается философии СОМ относительно отделения интерфейса от реализации и не раскрывает никаких деталей реализации объекта иначе, чем через список выставляемых им интерфейсов. 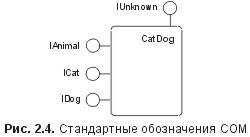 Рисунок 2.4 показывает стандартное обозначение класса CatDog. Заметим, что из этой схемы можно сделать единственный вывод: если не произойдет катастрофических сбоев, объекты CatDog выставят четыре интерфейса: ICat, IDog, IAnimal и IUnknown. Управление ресурсами и IUnknown Как было в случае с DuplicatePointer и DestroyPointer из предыдущей главы, методы AddRef и Release из IUnknown имеют очень простой протокол, которого должны придерживаться все, кто пользуется указателями этих интерфейсов. Эти правила освобождают клиента от необходимости управлять временем жизни объекта, когда несколько интерфейсных указателей могут указывать или не указывать на один и тот же объект. Клиентам необходимо только следовать простым правилам AddRef/Release единообразно для всех интерфейсных указателей, с которыми им приходится сталкиваться, а объект будет сам управлять своим временем жизни. Спецификация модели компонентных объектов (Component Object Model Specification) содержит четкие определения правил подсчета ссылок СОМ. Понимание мотивировки этих определений имеет решающее значение при СОМ-программировании на C++. Эти правила СОМ о подсчете ссылок могут быть сведены к трем простым аксиомам: Когда ненулевой указатель интерфейса копируется из одной ячейки памяти в другую, должен вызываться AddRef для извещения объекта о дополнительной ссылке. Перед тем как произойдет перезапись той ячейки памяти, где содержится ненулевой указатель интерфейса, необходимо вызвать Release, чтобы известить объект, что ссылка уничтожается. Избыточное количество вызовов AddRef и Release можно сократить, если иметь дополнительную информацию о связях между двумя и более ячейками памяти. Аксиома о дополнительной информации введена главным образом для того, чтобы ввести возможность преобразования запутанных ситуаций в разумные и осмысленные идиомы программирования (например, стеки временных вызовов и сгенерированное компилятором занесение переменной в регистр не нуждаются в подсчете ссылок). Можно провести месяцы в поиске особых связей между переменными, содержащими явные указатели на интерфейс в программе и оптимизировать избыточные вызовы AddRef и Release , но поступать так было бы неосмотрительно. Выгода от удаления этих избыточных вызовов явно незначительна, так как даже в худшем случае, когда объект вызывается с расстояния более 8500 миль со средней скоростью передачи 14.4 кбит/сек, эти избыточные вызовы никогда не уйдут из вызывающего потока и нечасто требуют множество инструкций для выполнения. Если руководствоваться приведенными выше тремя простыми аксиомами о подсчете ссылок в интерфейсных указателях, то можно записать это в виде руководящих принципов программирования, чтобы установить, когда вызывать и когда не вызывать AddRef и Release . Вот несколько типичных ситуаций, требующих вызова метода AddRef: А1. Когда ненулевой интерфейсный указатель записывается в локальную переменную. А2. Когда вызываемый объект пишет ненулевой интерфейсный указатель в параметр [out] или [in, out] метода или функции. A3. Когда вызываемый объект возвращает ненулевой интерфейсный указатель как физический результат (physical result) функции. А4. Когда ненулевой интерфейсный указатель пишется в элемент данных объекта. Некоторые типичные ситуации, требующие вызова метода Release : R1. Перед перезаписью ненулевой локальной переменной или элемента данных. R2. Перед тем как покинуть область действия ненулевой локальной переменной. R3. Когда вызываемый объект перезаписывает параметр [in,out] метода или функции, начальное значение которых отлично от нуля. Заметим, что параметры [out] предполагаются нулевыми при вводе и никогда не могут освобождаться вызываемым объектом. R4. Перед перезаписью ненулевого элемента данных объекта. R5. Перед завершением работы деструктора объекта, имеющего в качестве элемента данных ненулевой интерфейсный указатель. Типичная ситуация, к которой применимо правило о дополнительной информации, возникает при передаче указателей интерфейсов функциям как параметрам [in]: S1. Когда при вызове функции или метода ненулевой интерфейсный указатель передается через [in] -параметр, вызов AddRef и Release, не требуются, так как время жизни временной переменной в стеке является строгим подмножеством времени жизни выражения, использованного для инициализации формального аргумента. Эти десять руководящих принципов охватывают ситуации, снова и снова возникающие при программировании в СОМ, и было бы неплохо их запомнить. Чтобы конкретизировать правила подсчета ссылок в СОМ, предположим, что имеется глобальная функция, которая возвращает объекту интерфейсный указатель: void GetObject([out] IUnknown **ppUnk); и что имеется другая глобальная функция, которая выполняет некую полезную работу над объектом: void UseObject([in] IUnknown *pUnk); Написанный ниже код использует эти процедуры, чтобы управлять некоторыми объектами и возвращать интерфейсный указатель вызывающему объекту. Руководящие принципы, применимые к каждому оператору, указаны в комментариях к нему: void GetAndUse(/* [out] */ IUnknown ** ppUnkOut) { IUnknown *pUnk1 = 0, *pUnk2 = 0; *ppUnkOut =0; // R3 // get pointers to one (or two) objects // получаем указатели на один (или два) объекта GetObject(&pUnk1); //A2 GetObject(&pUnk2); //A1 // set pUnk2 to point to first object // устанавливаем pUnk2, чтобы указать на первый объект if (pUnk2) pUnk2->Release(): //R1 if (pUnk2 = pUnk1) pUnk2->AddRef(): //A1 // pass pUnk2 to some other function // передаем pUnk2 какой-нибудь другой функции UseObject(pUnk2); //S1 // return pUnk2 to caller using ppUnkOut parameter // возвращаем pUnk2 вызывающему объекту, используя // параметр ppUnkOut if (*ppUnkOut = pUnk2) (*ppUnkOut)->AddRef(); // A2 // falling out of scope so clean up // выходит за область действия и поэтому освобождаем if (pUnk1) pUnkl->Release(); //R2 if (pUnk2) pUnk2->Release(); //R2 } Важно отметить, что в вышеприведенном коде правило A2 применяется дважды, но по двум разным причинам. При вызове GetObject код выступает как вызывающий объект, а реализация GetObject является вызываемым объектом. Это означает, что реализация GetObject является ответственной за вызов AddRef через параметр [out]. При перезаписи памяти, на которую ссылается ppUnkOut, код выступает как вызываемый объект и корректно вызывает AddRef через интерфейсный указатель перед возвратом управления вызывающему объекту. Существуют некоторые тонкости относительно AddRef и Release, подлежащие обсуждению. Как AddRef, так и Release предназначались для возврата 32-битного целого числа без знака. Это целое число отражает общее количество оставшихся ссылок после применения операций AddRef или Release. Однако по целому ряду причин, связанных с многопоточным режимом, удаленным доступом и мультипроцессорной архитектурой, нельзя быть уверенным в том, что эта величина будет точно отражать общее число неосвобожденных интерфейсных указателей, и клиенту следует игнорировать ее, если только она не используется в целях диагностики при отладке. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 |
|||||||