 |
|
Популярные авторы:: Борхес Хорхе Луис :: Азимов Айзек :: Грин Александр :: Чехов Антон Павлович :: Раззаков Федор :: Горький Максим :: Толстой Лев Николаевич :: Ламур Луис :: Херберт Фрэнк :: Бережной Василий Популярные книги:: Дюна (Книги 1-3) :: The Boarding House :: Ползущая тень :: After The Race :: Правила русской орфографии и пунктуации :: Плодотворное разрушение сознания :: За Волгой земли для нас не было :: Основы православной веры :: Секрет государственной важности :: Цветок Колриджа |
Сущность технологии СОМ. Библиотека программистаModernLib.Net / Программирование / Бокс Дональд / Сущность технологии СОМ. Библиотека программиста - Чтение (стр. 4)
class IPersistentObject : public IFastString { public: virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; }; требует, чтобы все постоянные объекты поддерживали также операции Length и Find. Для некоторого, весьма малого подмножества объектов это могло бы иметь смысл. Однако для того, чтобы сделать интерфейс IPersistentObject возможно более общим, он должен быть своим собственным интерфейсом, а не порождаться от IFastString: class IPersistentObject { public: virtual void Delete(void) = 0; virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; }; Это не мешает реализации FastString стать постоянной; это просто означает, что постоянная версия FastString должна поддерживать оба интерфейса: и IFastString, и IPersistentObject: class FastString : public IFastString, public IPersistentObject { int m_cch; // count of characters // счетчик символов char *m_psz; public: FastString(const char *psz); ~FastString(void); // Common methods // Общие методы void Delete(void); // deletes this instance // уничтожает этот экземпляр // IFastString methods // методы IFastString int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение // IPersistentObject methods // методы IPersistentObject bool Load(const char *pszFileName); bool Save(const char *pszFileName); }; Чтобы записать FastString на диск, пользователю достаточно с помощью RTTI связать указатель с интерфейсом IPerststentObject, который выставляется объектом: bool SaveString(IFastString *pfs, const char *pszFN) { bool bResult = false; IPersistentObject *ppo = dynamic_cast if (ppo) bResult = ppo->Save(pszFN); return bResult; } Эта методика работает, поскольку транслятор имеет достаточно информации о представлении и иерархии типов класса реализации, чтобы динамически проверить объект для выяснения того, действительно ли он порожден от IPersistentObject. Но здесь есть одна проблема. RTTI – особенность, сильно зависящая от транслятора. В свою очередь, DWP передает синтаксис и семантику RTTI, но каждая реализация RTTI разработчиком транслятора уникальна и запатентована. Это обстоятельство серьезно подрывает независимость от транслятора, которая была достигнута путем использования абстрактных базовых классов как интерфейсов. Это является неприемлемым для архитектуры компонентов, не зависимой от разработчиков. Удачным решением было бы упорядочение семантики dynamic_cast без использования свойств языка, зависящих от транслятора. Явное выставление хорошо известного метода из каждого интерфейса, представляющего семантический эквивалент dynamic_cast, позволяет достичь желаемого эффекта, не требуя, чтобы все объекты использовали тот же самый транслятор C++: class IPersistentObject { public: virtual void *Dynamic_Cast(const char *pszType) = 0; virtual void Delete(void) = 0; virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; }; class IFastString { public: virtual void *Dynamic_Cast(const char *pszType) = 0; virtual void Delete(void) = 0; virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; }; Так как всем интерфейсам необходимо выставить этот метод вдобавок к уже имеющемуся методу Delete, имеет большой смысл включить общее подмножество методов в базовый интерфейс, из которого могли бы порождаться все последующие интерфейсы: class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void Delete(void) = 0; }; class IPersistentObject : public IExtensibleObject { public: virtual bool Load(const char *pszFileName) = 0; virtual bool Save(const char *pszFileName) = 0; }; class IFastString : public IExtensibleObject { public: virtual int Length(void) = 0; virtual int Find(const char *psz) = 0; }; Имея такую иерархию типов, пользователь может динамически запросить объект о данном интерфейсе с помощью следующей не зависящей от транслятора конструкции: bool SaveString(IFastString *pfs, const char *pszFN) { boot bResult = false; IPersistentObject *ppo = (IPersistentObject) pfs->Dynamic_Cast(«IPers1stentObject»); if (ppo) bResult = ppo->Save(pszFN); return bResult; } В только что приведенном примере клиентского использования присутствуют требуемая семантика и механизм для определения типа, но каждый класс реализации должен выполнять это функциональное назначение самолично: class FastString : public IFastString, public IPersistentObject { int m_cсh; // count of characters // счетчик символов char *m_psz; public: FastString(const char *psz); ~FastString(void); // IExtensibleObject methods // методы IExtensibleObject void *Dynamic_Cast(const char *pszType); void Delete(void); // deletes this instance // удаляет этот экземпляр // IFastString methods // методы IFastString int Length(void) const; // returns # of characters // возвращает число символов int Find(const char *psz) const; // returns offset // возвращает смещение // IPersistentObject methods // методы IPersistentObject bool Load(const char *pszFileName); bool Save(const char *pszFileName); }; Реализации Dynamic_Cast необходимо имитировать действия RTTI путем управления иерархией типов объекта. Рисунок 1.8 иллюстрирует иерархию типов для только что показанного класса FastString. Поскольку класс реализации порождается из каждого интерфейса, который он выставляет, реализация Dynamic_Cast в FastString может просто использовать явные статические приведения типа (explicit static casts), чтобы ограничить область действия указателя this, основанного на подтипе, который запрашивается клиентом: void *FastString::Dynam1c_Cast(const char *pszType) { if (strcmp(pszType, «IFastString») == 0) return static_cast else if (strcmp(pszType, «IPersistentObject») == 0) return static_cast else if (strcmp(pszType, «IExtensibleObject») == 0) return static_cast else return 0; // request for unsupported interface // запрос на неподдерживаемый интерфейс } 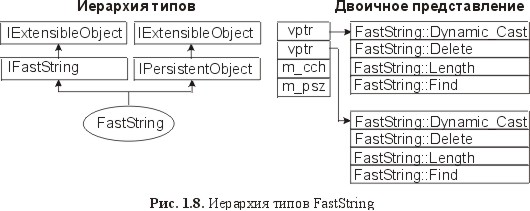 Так как объект порождается от типа, используемого в этом преобразовании, оттранслированные версии операторов преобразования просто добавляют определенное смещение к указателю объекта this, чтобы найти начало представления базового класса. Отметим, что после запроса на общий базовый интерфейс IExtensibleObject реализация статически преобразуется в IFastString. Это происходит потому, что интуитивная версия (intuitive version) оператора return static_cast неоднозначна, так как и IFastString, и IPersistentObject порождены от IExtensibleObject. Если бы IExtensibleObject был виртуальным базовым классом как для IFastString, так и для IPersistentObject, то данное преобразование не было бы неоднозначным и оператор бы оттранслировался. Тем не менее, применение виртуальных базовых классов добавляет на этапе выполнения ненужную сложность в результирующий объект и к тому же вносит зависимость от транслятора. Дело в том, что виртуальные базовые классы являются всего лишь особенностями языка C++, которые имеют несколько специфических реализации. Управление ресурсами Еще одна проблема поддержки нескольких интерфейсов из одного объекта становится яснее, если исследовать схему использования клиентом метода DynamicCast. Рассмотрим следующую клиентскую программу: void f(void) { IFastString *pfs = 0; IPersistentObject *ppo = 0; pfs = CreateFastString(«Feed BOB»); if (pfs) { ppo = (IPersistentObject *) pfs->DynamicCast(«IPersistentObject»); if (!ppo) pfs->Delete(); else { ppo->Save(«C:\\autoexec.bat»); ppo->Delete(); } } } Хотя вначале объект был связан через свой интерфейс IFastString , клиентский код вызывает метод Delete через интерфейс IPersistentObject. С использованием свойства C++ о множественном наследовании это вполне допустимо, так как все таблицы vtbl , порожденные классом IExtensibleObject, укажут на единственную реализацию метода Delete . Теперь, однако, пользователь должен хранить информацию о том, какие указатели связаны с какими объектами, и вызывать Delete только один раз на объект. В случае простого кода, приведенного выше, это не слишком тяжелое бремя. Для более сложных клиентских кодов управление этими связями становится делом весьма сложным и чреватым ошибками. Одним из способов упрощения задачи пользователя является возложение ответственности за управление жизненным циклом объекта на реализацию. Кроме того, разрешение клиенту явно удалять объект вскрывает еще одну деталь реализации: тот факт, что объект находится в динамически распределяемой памяти (в «куче», on the heap). Простейшее решение этой проблемы – ввести в каждый объект счетчик ссылок, который увеличивается, когда указатель интерфейса дублируется, и уменьшается, когда указатель интерфейса уничтожается. Это предполагает изменение определения IExtensibleObject с class IExtensibleObject { public: virtual void *DynamicCast (const char* pszType) =0; virtual void Delete(void) = 0; }; на class IExtensibleObject { public: virtual void *DynamicCast(const char* pszType) = 0; virtual void DuplicatePointer(void) = 0; virtual void DestroyPointer(void) = 0; }; Разместив эти методы, все пользователи IExtensibleObject должны теперь придерживаться следующих двух соображений: 1) Когда указатель интерфейса дублируется, требуется вызов DuplicatePointer. 2) Когда указатель интерфейса более не используется, следует вызвать DestroyPointer. Эти методы могут быть реализованы в каждом объекте: нужно просто фиксировать количество действующих указателей и уничтожать объект, когда невыполненных указателей не осталось: class FastString : public IFastString, public IPersistentObject { int mcPtrs; // count of outstanding ptrs // счетчик невыполненных указателей public: // initialize pointer count to zero // сбросить счетчик указателя в нуль FastString(const char *psz) : mcPtrs(0) { } void DuplicatePointer(void) { // note duplication of pointer // отметить дублирование указателя ++mcPtrs; } void DestroyPointer(void) { // destroy object when last pointer destroyed // уничтожить объект, когда уничтожен последний указатель if (-mcPtrs == 0) delete this; } : : : }; Этот совершенно стандартный код мог бы просто быть включен в базовый класс или в макрос С-препроцессора, чтобы его могли использовать все реализации. Чтобы поддерживать эти методы, все программы, которые манипулируют или управляют указателями интерфейса, должны придерживаться двух простых правил DuplicatePointer/DestroyPointer. Для реализации FastString это означает модификацию двух функций. Функция CreateFastString берет начальный указатель, возвращаемый новым оператором C++, и копирует его в стек для возврата клиенту. Следовательно, необходим вызов DuplicatePointer: IFastString* CreateFastString(const char *psz) { IFastString *pfsResult = new FastString(psz); if (pfsResult) pfsResult->DuplicatePointer(); return pfsResult; } Реализация копирует указатель и в другом месте – в методе Dynamic_Cast: void *FastString::Dynamic_Cast(const char *pszType) { void *pvResult = 0; if (strcmp(pszType, «IFastString») == 0) pvResult = static_cast else if (strcmp(pszType, «IPersistentObject») == 0) pvResult = static_cast else if (strcmp(pszType, «IExtensibleObject») == 0) pvResult = static_cast else return 0; // request for unsupported interface // запрос на неподдерживаемый интерфейс // pvResult now contains a duplicated pointer, so // we must call DuplicatePointer prior to returning // теперь pvResult содержит скопированный указатель, // поэтому нужно перед возвратом вызвать DuplicatePointer ((IExtensibleObject*)pvResult)->DuplicatePo1nter(); return pvResult; } С этими двумя усовершенствованиями соответствующий код пользователя становится значительно более однородным и прозрачным: void f(void) { IFastString *pfs = 0; IPersistentObject *ppo = 0; pfs = CreateFastString(«Feed BOB»); if (pts) { рро = (IPersistentObject *) pfs->DynamicCast(«IPersistentObject»); if (ppo) { ppo->Save(«C:\\autoexec.bat»); ppo->DestroyPointer(); } pfs->DestroyPointer(); } } Поскольку каждый указатель теперь трактуется как автономный объект с точки зрения времени жизни, клиенту можно не интересоваться тем, какой указатель соответствует какому объекту. Вместо этого клиент просто придерживается двух простых правил и предоставляет объектам самим управлять своим временем жизни. При желании способ вызова DuplicatePointer и DestroyPointer можно легко скрыть за интеллектуальным указателем (smart pointer) C++. Использование этой схемы вычисления ссылок позволяет объекту весьма единообразно выставлять множественные интерфейсы. Возможность выставления нескольких интерфейсов из одного класса реализации позволяет типу данных участвовать в различных контекстах. Например, новая постоянная подсистема могла бы определить собственный интерфейс для управления автозагрузкой и автозаписью объектов на некоторый специализированный носитель. Класс FastString мог бы добавить поддержку этих возможностей простым наследованием от постоянного интерфейса этой подсистемы. Добавление этой поддержки никак не повлияет на уже установленные базы клиентов, которые, может быть, используют прежний постоянный интерфейс для записи и загрузки строки на диск. Механизм согласования интерфейсов на этапе выполнения может служить краеугольным камнем для построения динамической системы из компонентов, которые могут изменяться со временем. Где мы находимся? Мы начали эту главу с простого класса C++ и рассмотрели проблемы, связанные с объявлением этого класса как двоичного компонента повторного использования. Первым шагом было употребление этого класса в качестве библиотеки Dynamic Link Library (DLL) для отделения физической упаковки этого класса от упаковок его клиентов. Затем мы использовали понятие интерфейсов и реализации для инкапсуляции элементов реализации типов данных за двоичной защитой, что позволило изменять двоичные представления объектов без необходимости перетрансляции клиентами. Затем, используя для определения интерфейсов подход абстрактного базового класса, эта защита приобрела форму указателя vptr и таблицы vtbl. Далее мы исследовали приемы для динамического выбора различных полиморфных реализаций данного интерфейса на этапе выполнения с использованием LoadLibrary и GetProcAddress. Наконец, мы использовали RTTI-подобную структуру для динамического опроса объекта с целью определить, действительно ли он использует нужный интерфейс. Эта структура предоставила нам методику расширения существующих версий интерфейса, а также возможность выставления нескольких несвязанных интерфейсов из одного объекта. Короче, мы только что создали модель компонентных объектов (Component Object Model – СОМ). Глава 2. Интерфейсы void *pv = malloc(sizeof(int)); int *pi = (int*)pv; (*pi)++; free(pv); В предыдущей главе было показано несколько приемов программирования на C++, позволяющих разрабатывать двоичные компоненты повторного использования, которые со временем могут быть модернизированы. По своему смыслу эти приемы идентичны тем, которые используются моделью СОМ. Незначительные различия между методиками предыдущей главы и теми, которые используются СОМ, в большинстве случаев заключаются в деталях и почти всегда достаточно обоснованы. Вообще-то предыдущая глава прослеживала историю модели СОМ, которая прежде всего и в основном есть отделение интерфейса от реализации. Снова об интерфейсах и реализациях Снова об интерфейсах и реализациях Цель отделения интерфейса от реализации заключалась в сокрытии от клиента всех деталей внутренней работы объекта. Этот фундаментальный принцип предусматривал уровень косвенности, или изоляции (level of indirection), который позволял изменяться количеству или порядку элементов данных в реализации класса без перекомпиляции клиента. Кроме того, этот принцип позволял клиентам обнаруживать расширенную функциональность путем опроса объекта на этапе выполнения. И, наконец, этот принцип позволяет сделать библиотеку DLL независимой от транслятора C++, который используется клиентом. Хотя этот последний аспект и полезен, он далеко не достаточен для обеспечения универсальной основы для двоичных компонентов. Важно отметить, что хотя клиенты могут использовать любой выбранный ими транслятор C++, в конечном счете это будет всего лишь транслятор C++. Приемы, описанные в предыдущей главе, обеспечивают независимость от транслятора. В конце концов, главное, что необходимо для создания действительно универсальной основы для двоичных компонентов, – это независимость от языка. А чтобы достичь независимости от языка, принцип отделения интерфейса от реализации должен быть применен еще раз. Рассмотрим определения интерфейса, использованные в предыдущей главе. Каждое определение интерфейса принимало форму определения абстрактного базового класса C++ в заголовочном файле C++. Тот факт, что определение интерфейса постоянно находится в файле, читаемом только на одном языке, вскрывает один остаточный признак реализации этого объекта – язык, на котором он был написан. Но, в конечном счете, объект должен быть доступен для любого языка, а не только для того, который выбрал разработчик объекта. Предусматривая только совместимое с C++ определение интерфейса, разработчик объекта тем самым вынуждает всех использующих этот объект также работать на C++. Хотя C++ – чрезвычайно полезный язык программирования, существует множество областей программирования, где больше подходят другие языки. Но точно так же, как проблемы совместимости при компоновке можно решить путем обеспечения всех существующих компиляторов файлами определения модуля, возможно и перевести определение интерфейса с C++ на любые другие языки программирования. А так как двоичная сигнатура интерфейса есть просто сочетание vptr/vtbl, этот перевод может быть сделан для большой группы языков. Проделывание этих языковых преобразований данных для всех известных интерфейсов потребовало бы огромного количества работы, а главное – невозможно успевать делать это для бурного потока языков программирования, которые индустрия программного обеспечения не устает изобретать чуть ли не каждую декаду. Идеально было бы написать сервисную программу, которая переводила бы определения класса C++ в некую абстрактную промежуточную форму. Из этой промежуточной формы такая программа могла бы преобразовывать данные для любого языка программирования, имеющего соответствующий выходной генератор (back-end generator). По мере того как новые языки приобретают значимость, могли бы добавляться новые выходные генераторы, и все ранее определенные интерфейсы смогли бы тотчас использоваться в совершенно новом контексте. К сожалению, язык программирования C++ полон неоднозначностей, что делает его малопригодным для преобразования данных на все мыслимые языки. Многие из этих неоднозначностей приводят к неопределенным соотношениям между указателями, памятью и массивами. Это не является проблемой, когда оба объекта: вызывающий (caller) и вызываемый (callee) – скомпилированы на С или на C++, но они не могут быть точно переведены на другие языки без дополнительной квалификации. Поэтому, чтобы устранить зависимость определения интерфейса от языка, используемого в какой-либо конкретной реализации, необходимо для определений интерфейсов использовать один язык, а для определений реализации – другой. Если все участники договорятся о едином языке для определений интерфейсов, то станет возможным определить интерфейс однажды и получать по мере необходимости новые представления реализации на специфических языках. СОМ предусматривает язык, который основан на хорошо известном синтаксисе С, но добавляет возможность при переводе на другие языки корректно устранить неоднозначность любых особенностей языка С. Этот язык называется языком описаний интерфейса (Interface Definition Language – IDL). IDL СОМ IDL базируется на языке определения интерфейсов основного открытого математического обеспечения удаленного вызова процедур в распределенной вычислительной среде – Open Software Foundation Distributed Computing Environment Remote Procedure Call (OSF DCE RPC). DCE IDL позволяет описывать удаленные вызовы процедур не зависящим от языка способом. Это дает возможность компилятору IDL генерировать код для работы в сети, который прозрачным образом (transparently), то есть незаметно для пользователя, переносит описанные операции на всевозможные сетевые средства сообщения. СОМ IDL просто добавляет некоторые расширения, специфические для СОМ, в DCE IDL для поддержки объектно-ориентированных понятий СОМ (например, наследование, полиморфизм). Не случайно, что когда обращение к объектам СОМ осуществляется через границу контекста выполнения[1] или через границы между машинами, все связи клиент-объект используют MS-RPC (реализация DCE RPC, являющаяся частью Windows NT и Windows 95) как основное средство сообщения. Win32 SDK включает в себя компилятор МIDL.ЕХЕ , который анализирует файлы СОМ IDL и генерирует несколько искусственных объектов – артефактов (artifacts). Как показано на рис. 2.1, MIDL генерирует совместимые с C/C++ заголовочные файлы, которые содержат определения абстрактного базового класса, соответствующие интерфейсам, описанным в исходном IDL-файле. 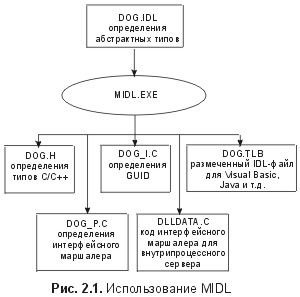 Эти заголовочные файлы также содержат совместимые с С, основанные на структурах определения (structure-based definitions), которые позволяют С-программам обращаться к интерфейсам, описанным на IDL, или обеспечивать их выполнение. То, что MIDL автоматически генерирует С/С++-заголовочный файл, означает, что ни один из СОМ-интерфейсов не нужно определять на C++ вручную. Исход определений из одной точки исключает возникновение множества несовместимых версий определений интерфейсов, которые со временем могут вызвать асинхронность. MIDL также генерирует исходный код, который позволяет использовать интерфейсы в различных потоках, процессах и машинах. Этот код будет обсуждаться в главе 5. И наконец, MIDL может генерировать двоичный файл, который позволяет другим средам, принимающим СОМ, отображать интерфейсы, определенные в исходном IDL-файле, на другие языки. Этот двоичный файл называется библиотекой типа (type library) и содержит разобранный файл IDL в наиболее эффективной для анализа форме. Библиотеки типа обычно распространяются как часть исполняемого файла реализации и позволяют таким языкам, как Visual Basic, Java, Object Pascal использовать интерфейсы, которые выставляются этой реализацией. Чтобы понять IDL, необходимо рассмотреть логический и физический аспекты интерфейса. Обсуждение методов интерфейса и выполняемых ими операций относятся к логическому аспекту интерфейса. Обсуждение памяти, стекового фрейма, сетевых пакетов и других динамических явлений обычно относятся к физическому аспекту интерфейса. Некоторые физические аспекты интерфейса могут непосредственно наследовать логическому описанию (например, расположение таблицы vtbl , порядок параметров в стеке). Другие физические аспекты (например, границы массивов, сетевые представления сложных типов данных) требуют дополнительной квалификации. IDL позволяет разработчикам интерфейса работать непосредственно в сфере логики, используя синтаксис С. Но в то же время IDL требует от разработчиков точно определять все те аспекты интерфейса, которые не могут быть воспроизведены непосредственно по их логическому описанию на С, с помощью использования аннотаций, формально называемых атрибутами. Атрибуты IDL легко распознать в основном тексте IDL: разделенные запятыми, они заключены в скобки. Атрибуты всегда предшествуют описанию объекта, к которому они относятся. Например, в следующем IDL– фрагменте [ v1enum, helpstring(«This is a color!») ] enum COLOR { RED, GREEN, BLUE }; атрибут v1_enum относится к описанию перечисления (enumeration) COLOR. Этот атрибут информирует компилятор IDL о том, что представление COLOR при передаче значения через сеть должно иметь 32 бита, а не 16, как принято по умолчанию. Атрибут helpstring также относится к СОLОR и добавляет строку «This is a color!» («Это – цвет!») в создаваемую библиотеку типа как описание этого перечисления. Если игнорировать атрибуты в IDL-файле, то его синтаксис такой же, как в С. IDL поддерживает структуры, объединения, массивы, перечисления, а также определения типа (typedef) – с синтаксисом, идентичным их аналогам в С. Определяя методы СОМ в IDL, необходимо четко указать, кто – вызывающий или вызываемый объект – будет записывать или читать каждый параметр метода. Это выполняется с помощью атрибутов параметра [in] и [out]: void Method1([in] long arg1, [out] long *parg2, [in, out] long *parg3); Для этого фрагмента IDL предполагается, что вызывающий объект передаст значение в объект arg1 и по адресу, содержащемуся в указателе parg3. По завершении возвращаемые значения будут получены вызывающим объектом по адресам, указанным в parg2 и parg3. Это означает, что для последовательности вызовов: long arg2 = 20, arg3 = 30; p->Method1(10, &arg2, &arg3); объект не может полагаться на получение передаваемого значения 20 через parg2. Если объект запускается в том же контексте выполнения, что и вызывающий объект, и оба участника вызова реализованы на C++, то *parg2 действительно будет иметь на входе метода значение 20. Однако если объект вызывается из другого контекста выполнения или один из участников вызова реализован на языке, который сводит на нет оптимизацию начальных значений чисто выходных (out-only) параметров, то инициализация параметра вызывающим объектом будет утеряна. Методы и их результаты Результаты методов – это одна из сторон СОМ, где логический и физический миры расходятся. В сущности, все методы СОМ физически возвращают номер ошибки с типом НRESULT. Использование одного типа возвращаемого результата позволяет удаленной COM-архитектуре перегружать результат выполнения метода, а также сообщать об ошибках соединения, просто зарезервировав ряд величин для RPC-ошибок. Величины НRESULT представляют собой 32-битные целые числа, которые передают в вызывающий контекст выполнения информацию о типе ошибок, которые могут произойти (например, ошибки сети, сбои сервера). Во многих языках, поддерживающих СОМ (например, Visual Basic, Java), HRESULT–значения перехватываются контекстом выполнения или виртуальной машиной и преобразуются в программные исключения (programmatic exceptions). 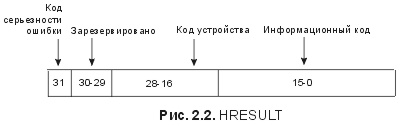
Как показано на рис. 2.2, HRESULT-значения состоят из трех битовых полей: бита серьезности ошибки (severity bit), кода устройства и информационного кода. Бит серьезности ошибки показывает, успешно выполнена операция или нет, код устройства индицирует, к какой технологии относится HRESULT , а информационный код представляет собой точный результат в рамках заданной технологии и серьезности. Заголовки SDK (software development kit – набор инструментальных средств разработки программного обеспечения) определяют два макроса, облегчающие работу с HRESULT: #define SUCCEEDED(hr) (long(hr) >= 0) #def1ne FAILED(hr) (long(hr) < 0) 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33 |
|||||||