|
|
Популярные авторы:: БСЭ :: Желязны Роджер :: Joyce James :: Андерсон Пол Уильям :: Раззаков Федор :: Толстой Лев Николаевич :: Станюкович Константин Михайлович :: Чехов Антон Павлович :: Сименон Жорж :: Лондон Джек Популярные книги:: The Boarding House :: Бурый волк :: Пошехонская старина :: Мальтийский сокол :: Вторая книга Паралипоменон :: Сорок бочек арестантов :: Основание :: Как мы изобрели фотосинтезатор :: 64 килобайта о Фидо :: Подземная Москва |
ИТ СЕРВИС–МЕНЕДЖМЕНТ. Вводный курс на основе ITILModernLib.Net / Van Jan / ИТ СЕРВИС–МЕНЕДЖМЕНТ. Вводный курс на основе ITIL - Чтение (стр. 4)
Управление Релизами Релизом называется набор Конфигурационных Единиц , которые совместно тестируются и вводятся в активную рабочую среду. Главной задачей Управления Релизами является обеспечение успешного развертывания релизов, включая интеграцию, проведение тестирования и хранение. Управление Релизами обеспечивает гарантию того, что в использовании находятся только тестированные и корректные версии авторизованного программного и аппаратного обеспечения. Управление Релизами тесно связано с деятельностью по Управлению Конфигурациями и Управлению Изменениями. Реальное внесение изменений часто осуществляется через действия в рамках Процесса Управления Релизами. 3.3.3. Другие рассматриваемые процессы Существуют два процесса, которые хотя и не являются модулями ITIL в сериях Предоставление услуг и Поддержка услуг, но связаны ссылками с другими модулями или с ключевыми пунктами других процессов. Управление Отношениями с Заказчиком ИТ1 является процессом, привлекающим все больше внимания, но пока не вошедшим в какой-либо модуль ITIL. Управление Информационной Безопасностью было описано в публикации ITIL 1999 г., но формально не является частью серии Предоставление услуг. Вопросам безопасности в этой книге посвящена отдельная глава. Управление Взаимоотношениями с Заказчиком ИТ Передовой опыт многих организаций показывает, что рекомендуется использовать стройный целенаправленный подход к организации взаимоотношений с заказчиками, структурированный на нескольких уровнях. Деятельность по Управлению Взаимоотношениями с Заказчиком ИТ включается в несколько процессов (см. также раздел 2.2.5). Служба Service Desk является первой точкой контакта для пользователей. Однако, заказавший услугу клиент первоначально вступает во взаимодействие с Процессом Управления Взаимоотношениями с Заказчиком ИТ. Он помогает выстроить мост между ИТ-организацией, традиционно использующей технические подходы к работе, и заказчиками, работающими над решением бизнес-задач своего предприятия. Управление Взаимоотношениями с Заказчиком ИТ не является частью серии книг по Предоставлению услуг и не рассматривается в этой ознакомительной книге. Управление Информационной Безопасностью Целью Процесса Управления Информационной Безопасностью является защита ИТ-инфраструктуры от несанкционированного использования (например, от несанкционированного доступа к данным). Такая защита основана на требованиях безопасности, заложенных в соглашениях об Уровне Услуг, контрактных требованиях, законодательстве, правилах работы компании и базовом Уровне Безопасности. При подготовке новой редакции раздела ITIL по предоставлению услуг было решено, что недавно выпущенную книгу по Управлению Информационной Безопасностью не стоит заменять. Книга ITIL по предоставлению услуг не рассматривает данного предмета, но ссылается на книгу ITIL по Управлению Информационной Безопасностью.
Рис. 3.4. Книга "Поддержка Услуг" (Service Support) – публикация 2000 г. (OGC)
Рис. 3.5. Книга "Предоставление Услуг" (Service Delivery) – публикация 2001 г. (OGC)
Рис. 3.6. Книга "Управление Инфраструктурой информационных и коммуникационных технологий" (ICT Infrastructure Management) – публикация 2002 г. (OGC)
Рис. 3.7. Книга "Управление Приложениями" (Application Management) – публикация 2002 г. (OGC)
Рис. 3.8. Книга "Управление Безопасностью" (Security Management) – публикация 2002 г. (OGC)
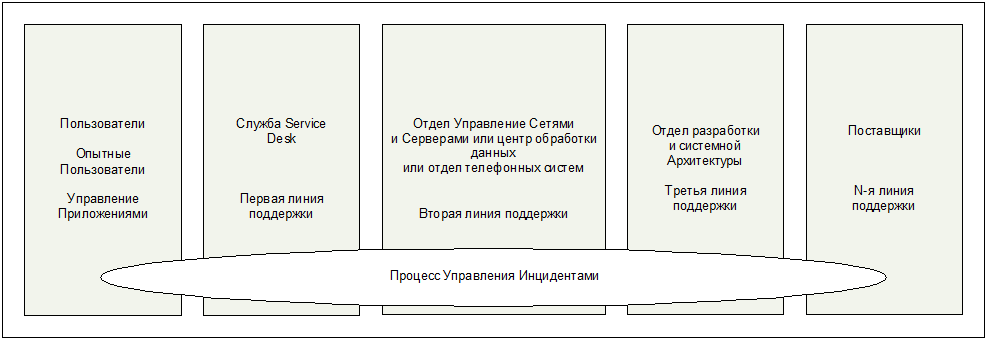
Рис. 3.9. Книга "Планирование внедрения Сервис-менеджмента" (Planning to Implement Service Management) – книга 2002 г. (OGC) Глава 4 Управление Инцидентами 4.1. Введение Задача Процесса Управления Инцидентами является реактивной – уменьшение или исключение отрицательного воздействия (потенциальных) нарушений в предоставлении ИТ-услуг, таким образом обеспечивая наиболее быстрое восстановление работы пользователей. Для выполнения этой задачи производится регистрация, классификация и назначение инцидентов соответствующим группам специалистов, мониторинг хода работ по разрешению инцидентов, решение инцидентов и их закрытие. Так как это требует тесного взаимодействия с пользователями, фокусной точной Процесса управления Инцидентами обычно является функция Service Desk , которая играет роль центра контактов пользователей с "внутренними" коллективами технических служб. Управление Инцидентами является важнейшей основой для работы других процессов ITIL, предоставляя ценную информацию об ошибках в работе ИТ-инфраструктуры. На рис. 4.1 показан схематичный пример Управления Инцидентами как горизонтальный процесс, охватывающий разные ИТ-отделы и осуществляющий эффективное управление и контроль обработки инцидентов.
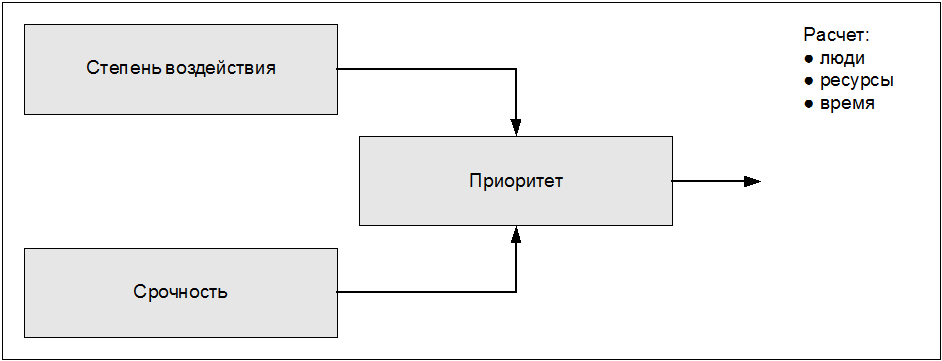
Рис. 4.1. Позиционирование Процесса Управления Инцидентами относительно других функций (подразделений) ИТ-организации 4.1.1. Терминология Инцидент Библиотека ITIL использует широкое определение термина "инцидент", поэтому почти все обращения пользователей могут регистрироваться и отслеживаться как инциденты. В книге "Поддержка услуг" библиотеки ITIL дается следующее определение: Инцидент - это любое событие, не являющееся частью стандартных операций по предоставлению услуги, которое привело или может привести к нарушению или снижению качества этой услуги. В контексте библиотеки ITIL инцидентами считаются не только ошибки аппаратного или программного обеспечения, но также и Запросы на Обслуживание. Запрос на обслуживание - это Запрос от Пользователя на поддержку, предоставление информации, консультации или документации, не являющийся сбоем ИТ-инфраструктуры. Примеры Запросов на Обслуживание: ? вопрос о функционировании ИТ-систем или запрос о предоставлении какой-либо информации; ? запрос о состоянии (статусе) чего-либо в ИТ-инфраструктуре; ? запрос о замене пароля; ? запросы на выполнение пакетных заданий, восстановление или авторизацию пароля; ? получение информации из базы данных. Для того чтобы можно было отличить "настоящие инциденты" от "инцидентов-Запросов на Обслуживание", рекомендуется присваивать Запросам на Обслуживание специальную категорию. Важно также отметить, что Запрос на Обслуживание это не то же самое, что Запрос на Изменение: Запрос на Изменение (RFC) – это экранная или бумажная форма, используемая для записи детальной информации о предлагаемом Запросе на Изменение какой-либо Конфигурационной Единицы (CI) в ИТ-инфраструктуре или процедуры или какого-либо иного объекта ИТ-инфраструктуры. Запрос на Изменение RFC считается завершенным после проведения изменения в инфраструктуре, например, замены зарегистрированных компонентов, инсталляции ПК и т. д. Это не инциденты, а изменения. Степень воздействия , срочность и приоритет При одновременной обработке нескольких инцидентов необходимо расставлять приоритеты. Обоснованием для назначения приоритета служит уровень важности ошибки для бизнеса и для пользователя. На основе диалога с пользователем и в соответствии с положениями Соглашений об Уровнях Услуг (Service Level Agreements – SLAs) Служба Service Desk назначает приоритеты, определяющие порядок обработки инцидентов. При эскалации инцидентов на вторую, третью или более линии поддержки, тот же приоритет должен быть соблюден, но иногда он может быть скорректирован по согласованию со Службой Service Desk. Конечно, каждый пользователь будет считать, что его инцидент имеет наивысший приоритет, но мнения пользователей часто бывают субъективными. Для объективной оценки приоритета в диалоге с пользователем употребляются следующие критерии: ? степень воздействия инцидента: степень отклонения от нормального уровня предоставления услуги, выражающаяся в количестве пользователей или бизнес-процессов, подвергшихся воздействию инцидента; ? срочность инцидента: приемлемая задержка разрешения инцидента для пользователя или бизнес-процесса. Приоритет определяется на основе срочности и степени воздействия. Для каждого приоритета определяется количество специалистов и объем ресурсов, которые могут быть направлены на разрешение инцидента. Порядок обработки инцидентов одинакового приоритета может быть определен в соответствии с усилиями, необходимыми для разрешения инцидента. Например, легко разрешаемый инцидент может быть обработан перед инцидентом, требующим больших усилий. При Управлении Инцидентами существуют способы снижения степени воздействия и срочности, такие, как переключение системы на резервную конфигурацию, перенаправление очереди печати и др.
Рис. 4.2. Определение степени воздействия, срочности и приоритета Степень воздействия и срочность также могут сами меняться во времени, например, при росте количества пользователей, подвергшихся воздействию инцидента или в критические моменты времени. Степень воздействия и срочность могут быть объединены в матрицу, как показано в табл. 4.1.
Таблица 4.1. Пример системы кодирования приоритетов Эскалация Если инцидент не может быть разрешен первой линией поддержки за согласованное время, необходимо привлечение дополнительных знаний или полномочий. Это называется эскалацией, которая происходит в соответствии с рассмотренными выше приоритетами и, соответственно, временем разрешения инцидента. Различают функциональную и иерархическую эскалацию: ? Функциональная эскалация (горизонтальная) – означает привлечение большего количества специалистов или предоставление дополнительных прав доступа для разрешения инцидента; при этом, возможно, происходит выход за пределы одного структурного ИТ-подразделения. ? Иерархическая эскалация (вертикальная) – означает вертикальный переход (на более высокий уровень) в рамках организации, так как для разрешения инцидента недостаточно организационных полномочий (уровня власти) или ресурсов. Задачей Руководителя Процесса Управления Инцидентами является заблаговременное резервирование возможностей для функциональной эскалации в рамках линейных подразделений организации так, чтобы разрешение инцидентов не требовало регулярной иерархической эскалации. В любом случае, линейные подразделения должны предоставить для этого процесса достаточное количество ресурсов. Первая, вторая и n-линия поддержки Выше была изложена маршрутизация инцидента, или функциональная эскалация. Маршрутизация определяется требуемым уровнем знаний, полномочий и срочностью. Первой линией поддержки (называемой также поддержкой 1-го уровня) обычно является Служба Service Desk, второй линией – подразделений, осуществляющие Управление ИТ-инфраструктурой, третья – отделы разработки и архитектуры программного обеспечения, и четвертая – поставщики. Чем меньше организация, тем меньше в ней уровней эскалации. В больших организациях Руководитель Процесса Управления Инцидентами может назначить Координаторов инцидентов в соответствующих подразделениях для поддержки своей деятельности. Например, координаторы могут играть роль интерфейса между процессной деятельностью и линейными организационными подразделениями. Каждый из них координирует деятельность собственных групп поддержки. Процедура эскалации графически представлена на рис. 4.3.
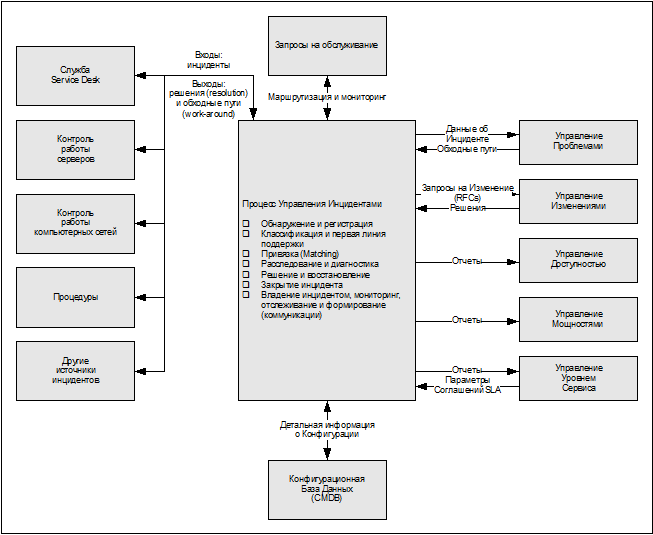
Рис. 4.3. Эскалация инцидента (источник: OGC) 4.2. Цель Целью Процесса Управления Инцидентами является скорейшее восстановление нормального Уровня Услуг, определенного в Соглашении об Уровне Услуг (Service Level Agreement – SLA), с минимальными возможными потерями для бизнес-деятельности организации и пользователей. Кроме того, Процесс Управления Инцидентами должен вести точную регистрацию инцидентов для оценки и совершенствования процесса и предоставления необходимой информации для других процессов. 4.2.1. Преимущества использования процесса ? Для бизнеса в целом: ? своевременное разрешение инцидентов, ведущее к уменьшению потерь для бизнеса; ? повышение производительности работы пользователей; ? независимый, ориентированный на потребности заказчика мониторинг инцидентов; ? доступность объективной информации о соответствии предоставляемых услуг согласованным договоренностям (SLA). ? Для ИТ-организации: ? улучшенный мониторинг, позволяющий проводить точное сопоставление уровня производительности ИТ-систем с соглашениями (SLA); ? эффективное руководство и мониторинг выполнения соглашений (SLA) на основе достоверной информации; ? эффективное использование персонала; ? предотвращение потерь инцидентов и Запросов на Обслуживание или их неправильной регистрации; ? повышение точности информации в Конфигурационной Базе Данных (Configuration Management Database – CMDB) за счет ее проверки при регистрации инцидентов в привязке к Конфигурационным Единицам (Configuration Item – CI); ? повышение удовлетворенности пользователей и заказчиков. Отказ от использования Процесса Управления Инцидентами может привести к следующим отрицательным последствиям: ? инциденты могут быть потеряны или, наоборот, необоснованно восприняты как чрезвычайно серьезные из-за отсутствия ответственных за мониторинг и эскалацию, что может привести к снижению общего уровня обслуживания; ? пользователи могут перенаправляться к одним и тем же специалистам "по кругу" без успешного разрешения инцидента; ? специалисты могут постоянно отрываться от работы телефонными звонками пользователей, из-за чего им становится трудно эффективно выполнять свою работу; ? могут возникать ситуации, когда несколько человек будут работать над одним и тем же инцидентом, непродуктивно теряя время, и примут противоречивые решения; ? может ощущаться недостаток информации о пользователях и предоставляемых услугах, необходимой для принятия руководящих решений; ? из-за указанных выше возможных проблем затраты компании и ИТ-организации на поддержку услуг будут выше, чем реально требуется. 4.3. Процесс На рис. 4.4 показаны входы и выходы процесса, а также виды деятельности, которые охватывает этот процесс.
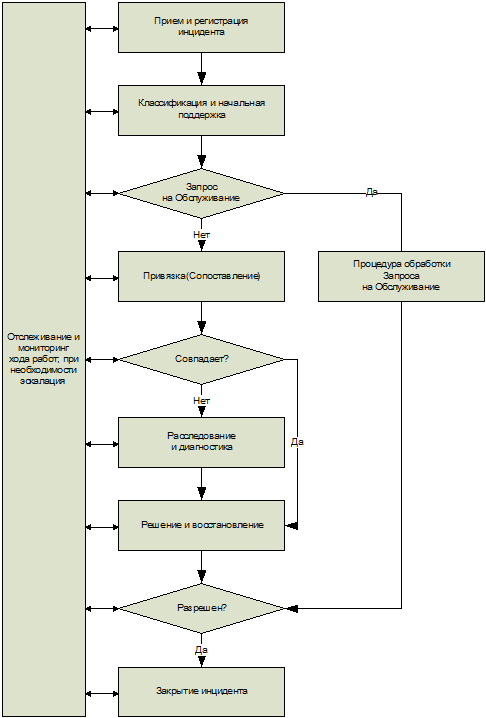
Рис. 4.4. Положение Процесса Управления Инцидентами 4.3.1. Входы процесса Инциденты могут возникнуть в любой части инфраструктуры. Часто о них сообщают пользователи, но возможно их обнаружение и сотрудниками других отделов, а также автоматическими системами управления, настроенными на регистрацию событий в приложениях и технической инфраструктуре. 4.3.2. Управление конфигурациями Конфигурационная База Данных (Configuration Management Database - CMDB) играет важную роль в Управлении Инцидентами, так как она определяет связь между ресурсами, услугами, пользователями и Уровнями Услуг (сервисов). Например, Управление Конфигурациями показывает, кто является ответственным за компонент инфраструктуры, что делает возможным более эффективное распределение инцидентов по группам специалистов. Кроме того, эта база данных помогает решать оперативные вопросы, например, перенаправление очереди печати или переключение пользователя на другой сервер. При регистрации инцидента в регистрационные данные добавляется связь (link) с соответствующей Конфигурационной Единицей (Configuration Item – CI), позволяющая предоставить более подробную информацию об источнике ошибки. В случае необходимости может быть обновлен статус соответствующей компоненты в CMDB. 4.3.3. Управление Проблемами Эффективное Управление Проблемами требует качественной регистрации инцидентов, что значительно облегчит поиск корневых причин. С другой стороны, Управление Проблемами помогает Процессу Управления Инцидентами, предоставляя информацию о проблемах, известных ошибках, обходных решениях и быстрых исправлениях . 4.3.4. Управление Изменениями Инциденты могут быть решены путем внесения изменений, например, заменой монитора. Управление Изменениями предоставляет Процессу Управления Инцидентами информацию о запланированных изменениях и их статусах. Кроме того, изменения могут вызвать инциденты, если изменения произведены неправильно или содержат ошибки. Процесс Управления Изменениями получает информацию о них из Процесса Управления Инцидентами. 4.3.5. Управление Уровнем Услуг Управление Уровнем Услуг контролирует выполнение договоренностей (соглашений – SLA) с заказчиком о предоставляемой ему поддержке. Сотрудники, участвующие в Управлении Инцидентами должны хорошо знать эти соглашения, чтобы использовать необходимую информацию при контактах с пользователями. Кроме того, регистрационные данные об инцидентах требуются при составлении отчетов для проверки выполнения согласованного Уровня Услуг. 4.3.6. Управление Доступностью Для определения показателей доступности услуг Процесс Управления Доступностью использует регистрационные данные об инцидентах и данные мониторинга статуса, предоставляемые Процессом Управления Конфигурациями. Аналогично Конфигурационной Единице (CI) в Конфигурационной Базе Данных (CMDB), сервису (услуге) может быть также назначен статус "не работает" . Это может быть использовано для проверки действительных показателей доступности услуги и времени реагирования поставщика. При осуществлении такой проверки необходима фиксация времени действий, произошедших в процессе обработки инцидента, от момента обнаружения и до закрытия. 4.3.7. Управление мощностями Процесс Управления Мощностями получает информацию об инцидентах, связанных с функционированием самих ИТ-систем, например, инцидентах, произошедших в связи с недостатком дискового пространства или медленной скоростью реакции и т.д. В свою очередь, информация об этих инцидентах может поступать в Процесс Управления Инцидентами от системного администратора или от самой системы на основе мониторинга своего состояния. Ни рис. 4.5. показаны этапы процесса:
Рис. 4.5. Процесс Управления Инцидентами ? Прием и регистрация инцидента (Acceptance and Recording) – принимается сообщение и создается запись об инциденте. ? Классификация и начальная поддержка (Classification and Initial Support) – присваиваются тип, статус, степень воздействия, срочность, приоритет инцидента, SLA и т.п. Пользователю может быть предложено возможное решение, даже если оно только временное. ? Если вызов касается Запроса на Обслуживание (Service Request), то инициируется соответствующая процедура. ? Привязка (или сопоставление – Matching) – проверяется, не является ли инцидент уже известным инцидентом или известной ошибкой, нет ли для него уже открытой проблемы, и нет ли для него известного решения или обходного пути. ? Расследование и диагностика (Investigation and Diagnosis) – при отсутствии известного решения производится исследование инцидента с целью как можно быстрее восстановить нормальную работу. ? Решение и восстановление (Resolution and Recovery) – если решение найдено, то работа может быть восстановлена. ? Закрытие (Closure) – с пользователем связываются, чтобы он подтвердил согласие с предложенным решением, после чего инцидент может быть закрыт. ? Мониторинг хода работ и отслеживание (Progress monitoring and Tracking) – весь цикл обработки инцидента контролируется, и если инцидент не может быть разрешен вовремя, производится эскалация. 4.4. Виды деятельности 4.4.1. Прием и регистрация В большинстве случаев инциденты регистрируются Службой Service Desk, куда поступают сообщения о них. Регистрация всех инцидентов должна производиться немедленно после поступления сообщения по следующим причинам: ? трудно произвести точную регистрацию информации об инциденте, если это не сделано сразу; ? мониторинг хода работ по решению инцидента возможен, только если инцидент зарегистрирован; ? зарегистрированные инциденты помогают при диагностике новых инцидентов; ? Управление Проблемами может использовать зарегистрированные инциденты при работе над поиском корневых причин; ? легче определить степень воздействия, если все сообщения (звонки) зарегистрированы; ? без регистрации инцидентов невозможно контролировать исполнение договоренностей (SLA); ? немедленная регистрация инцидентов предотвращает ситуации, когда или несколько человек работают над одним звонком, или никто ничего не делает для разрешения инцидента. Место обнаружения инцидента определяется по признаку, откуда пришло сообщение о нем. Инциденты могут быть обнаружены следующим образом: ? Обнаружен пользователем: он докладывает об инциденте в Службу Service Desk. ? Обнаружен системой: при обнаружении события в приложении или технической инфраструктуре, например, при превышении критического порога, событие регистрируется как инцидент в системе регистрации инцидентов и, при необходимости, направляется в группу поддержки. ? Обнаружен сотрудником Службы Service Desk: сотрудник производит регистрацию инцидента. ? Обнаружен кем-либо в другом подразделении ИТ: этот специалист регистрирует инцидент в системе регистрации инцидентов или докладывает о нем в Службу Service Desk. Необходимо избегать двойной регистрации одного инцидента. Поэтому при регистрации инцидента следует проверить, нет ли аналогичных открытых инцидентов: ? Если есть (и они касаются того же инцидента), информация об инциденте обновляется или же инцидент регистрируется отдельно и устанавливается связь (привязка) к главному инциденту; при необходимости изменяется степень воздействия и приоритет, и добавляется информация о новом пользователе. ? Если нет (отличается от открытого инцидента), производится регистрация нового инцидента. В обоих случаях продолжение процесса одинаково, хотя в первом случае последующие действия гораздо проще. При регистрации инцидента производятся следующие действия: ? Назначение номера инцидента: в большинстве случаев система автоматически назначает новый (уникальный) номер инцидента. Часто этот номер сообщается пользователю, чтобы он мог ссылаться на него при дальнейших контактах. ? Запись базовой диагностической информации: время, признаки (симптомы), пользователь, сотрудник, принявший вопрос в обработку, место произошедшего инцидента и информация о затронутой услуге и/или технических средствах. ? Запись дополнительной информации об инциденте: добавляется информация, например, из скрипта (script) или процедуры опроса или из Конфигурационной Базы Данных – CMDB (обычно на основе взаимоотношений Конфигурационных Единиц, определенных в CMDB). ? Объявление сигнала тревоги: если происходит инцидент, имеющий высокую степень воздействия, например, сбой важного сервера, производится предупреждение других пользователей и руководства. 4.4.2. Классификация Классификация инцидентов направлена на определение его категории для облегчения мониторинга и составления отчетов. Желательно, чтобы опции классификации были как можно шире, но при этом требуется более высокий уровень ответственности персонала. Иногда пытаются объединить в одном перечне несколько аспектов классификации, таких, как тип, группа поддержки и источник. Это часто вносит путаницу. Лучше использовать несколько коротких перечней. В данном разделе рассматриваются вопросы, относящиеся к классификации. Категория Прежде всего, инцидентам присваивается категория и подкатегория, например, исходя из предполагаемого источника инцидента или соответствующей группы поддержки: ? Центральная процессинговая система – подсистема доступа, центральный сервер, приложение. ? Сеть – маршрутизаторы, сегменты, концентратор (hub), IP-адреса. ? Рабочая станция – монитор, сетевая карта, дисковод, клавиатура. ? Использование и функциональность – услуга (сервис), возможности системы, доступность, резервное копирование (back-up), документация. ? Организация и процедуры – заказ, запрос, поддержка, оповещение (коммуникации). ? Запрос на Обслуживание – запрос пользователя в Службу Service Desk на поддержку, предоставление информации, документации или оказание консультации. Это может быть выделено в отдельную процедуру или обработано таким же образом, как реальный инцидент. Приоритет После этого назначается приоритет, чтобы быть уверенными, что группа поддержки уделит инциденту необходимое внимание. Приоритет - это номер, определяющийся срочностью (насколько быстро это должно быть исправлено) и степенью воздействия (какой ущерб будет нанесен, если не исправить быстро). Приоритет = Срочность х Степень воздействия. Услуги (сервисы) Для определения услуг, подвергшихся воздействию инцидента, может быть использован перечень существующих договоренностей (соглашений) об Уровне Услуг – SLA. Этот перечень позволит также установить время эскалации для каждой из услуг, определенных в SLA. Группа поддержки Если Служба Service Desk не может разрешить инцидент незамедлительно, то определяется группа поддержки, которая будет заниматься разрешением инцидента. Основой для распределения (маршрутизации) инцидентов часто является информация о категориях. При определении категорий может потребоваться рассмотрение структуры групп поддержки. Правильное распределение инцидентов имеет существенное значение для эффективности Процесса Управления Инцидентами. Поэтому одним из ключевых показателей эффективности (KPI) Процесса Управления Инцидентами может быть число неправильно распределенных обращений. Сроки решения С учетом приоритета и соглашения SLA пользователь информируется о максимальном расчетном времени разрешения инцидента. Эти сроки также фиксируются в системе. Идентификационный номер инцидента Абонент информируется о номере инцидента для его точной идентификации при последующих обращениях. Статус Статус инцидента указывает на его положение в процессе обработки инцидента. Примерами статусов могут быть: ? новый; ? принят; ? запланирован; ? назначен; ? активный; ? отложен; ? разрешен; ? закрыт. 4.4.3. Привязка (сопоставление) После классификации проводится проверка, не возникал ли аналогичный инцидент ранее и нет ли готового решения или обходного пути. Если инцидент имеет те же признаки, что и открытая проблема или известная ошибка, то может быть установлена связь с ними. 4.4.4. Расследование и диагностика Служба Service Desk или группа поддержки направляет инциденты, не имеющие готового решения или выходящие за пределы компетенции работающего с ним сотрудника, группе поддержки следующего уровня с большим опытом и знаниями. Эта группа исследует и разрешает инцидент или направляет его группе поддержки очередного уровня. В процессе разрешения инцидента различные специалисты могут обновлять регистрационную запись о нем, изменяя текущий статус, информацию о выполненных действиях, пересматривая классификацию и обновляя время и код работавшего сотрудника. 4.4.5. Решение и восстановление После успешного завершения анализа и разрешения инцидента сотрудник записывает решение в систему. В некоторых случаях необходимо направить Запрос на Изменение (RFC) в Процесс Управления Изменениями. В наихудшем случае, если не найдено никакого решения, инцидент остается открытым. 4.4.6. Закрытие После реализации решения, удовлетворяющего пользователя, группа поддержки направляет инцидент обратно в Службу Service Desk. Эта служба связывается с сотрудником, сообщившим об инциденте, с целью получения подтверждения об успешном решении вопроса. Если он это подтверждает, то инцидент может быть закрыт; в противном случае процесс возобновляется на соответствующем уровне. При закрытии инцидента необходимо обновить данные об окончательной категории, приоритете, сервисах (услугах), подвергшихся воздействию инцидента и Конфигурационной Единице (CI), вызвавшей сбой. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 |
|||||||||||||||||||||||||||||||||||||||