 |
|
Популярные авторы:: БСЭ :: Азимов Айзек :: Борхес Хорхе Луис :: Лем Станислав :: Чехов Антон Павлович :: Грин Александр :: Кларк Артур Чарльз :: Толстой Лев Николаевич :: Андреев Леонид Николаевич :: Сименон Жорж Популярные книги:: Справочник по реестру Windows XP :: The Boarding House :: Летная погода :: Шепчи мне о любви (Том 1) :: Созвездие Ворона :: Небесные творцы :: Один год :: Преступление в Голландии :: Уроки любви :: Основание |
Компьютерра (№255) - Журнал «Компьютерра» № 34 от 18 сентября 2006 годаModernLib.Net / Компьютеры / Компьютерра / Журнал «Компьютерра» № 34 от 18 сентября 2006 года - Чтение (стр. 5)
Естественно, первое, что приходит в голову с таким подходом, — это перевод. — Нетрудно понять, что человек-переводчик в процессе перевода сначала понимает смысл исходного предложения, а затем синтезирует этот смысл на другом языке. Только так можно получить адекватный перевод. Если же Google будет применять какие угодно эвристики, переводить по частям, используя пословный или пофразовый перевод, то неизбежно будет теряться смысл. Конечно, кое-что можно понять уже на уровне синтаксического анализа. Например, синтаксический анализ зачастую позволяет разобраться с омонимией, когда одно и то же слово может означать разные вещи. Возьмем, допустим, слово «copy» — оно может быть как существительным («копия»), так и глаголом («копировать»). Но синтаксический анализ предложения I will copy this book показывает, что в данном случае «copy» — это глагол. Проблема в том, что синтаксис даже в таких, относительно простых случаях работает не всегда. Омонимию «за,мок»-"замо,к" синтаксически разрешить невозможно. «Я буду жить в этом замке» или «я повесил этот замок». Здесь уже нужен семантический анализ. Кошка в чулане Выглядит все очень здорово, но, кажется, похожую функциональность обещали и экспертные системы, дайте-ка вспомнить, двадцать, тридцать, сорок лет назад? — Если говорить о других подходах, то можно вспомнить не только экспертные системы, но и нейрокомпьютеры, которые, вообще говоря, к системам ИИ можно отнести с большой натяжкой, формально они к ним не относятся, это в большей степени статистические модели. Что касается экспертных систем, то в этой области масса различных реализаций. Если говорить о «черном ящике», то наша технология может имитировать поведение экспертной системы, если конечному пользователю так проще. Он сможет задавать вопросы и получать ответы. Но ключевым отличием NLC является то, что у нас целостный подход, мы строим целостное представление о мире. Экспертные системы никогда не ставили себе целью построение всеобъемлющей модели, да и не могли поставить такую цель. Что это означает? Мы применяем так называемый IPA-подход — Integrity, Purposefulness and Adaptability, целостное, целенаправленное адаптивное восприятие. Этот принцип лежит в основе FineReader, NLC и ряда других систем ИИ, которыми мы занимаемся. Отдельные его принципы существовали и до нас, но наиболее цельно сформулировал этот подход наш главный идеолог по этому направлению Александр Львович Шамис, так что мы считаем, что принцип IPA изобретен нами. И этот принцип работает — сегодня FineReader умеет, например, распознавать рукописные шрифты без настройки на почерк. В двух словах о том, что это такое. Во-первых, принцип целостности постулирует, что мы храним знания о мире целостным образом. Любые знания являются частью целого. Если говорить о распознавании текстов, то любая буква может быть представлена как система элементов, связанных друг с другом определенным образом. Если говорить о структуре языка, то здесь мы видим систему понятий, которые логически связаны друг с другом. Принцип целенаправленности говорит о том, что мы не пытаемся исходить из того, что видим или анализируем. Мы поступаем ровно наоборот — априори высказываем гипотезу и пытаемся ее проверить. Наша система изначально является активным субъектом данного акта взаимодействия. Она не просто воспринимает данные на входе, но, получив объект для восприятия, пытается угадать, что это такое, или опровергнуть выдвинутую гипотезу. Причем это система с обратной связью — позитивные или негативные результаты запоминаются, система адаптируется и самообучается. Представьте, что вы вошли в чулан. Темнота. Света практически нет, только какой-то слабый лучик пробивается. Вы почти ничего не видите, но чувствуете, что слева от вас что-то прошмыгнуло, проскочил движущийся объект. Через доли секунды вы уже знаете точно, что это была кошка. Как это произошло? Как вы догадались, ведь вы ее не видели? Традиционная система распознавания взяла бы ту явно недостаточную графическую информацию, попыталась бы сделать на ее основании какие-то выводы — и у нее, конечно, ничего не получилось бы, потому что кошки не было, вы не видели ее. Но человек действует иначе. Сам не осознавая этого, он выдвигает гипотезы (как ограничивается круг возможных гипотез, это отдельный большой вопрос). Возможно, это собака, думает человек. Но если это собака, то тень должна была быть крупнее. Кроме того, собака должна издавать соответствующие звуки. Значит, эта гипотеза неверна. Переходим к следующей. Возможно, это мышь? Тоже нет, не подходит по размерам. А если это кошка? Кошка подходит. Это кошка! Но для выдвижения последней гипотезы у человека должны быть определенные знания о кошке. Он должен знать, что у кошки четыре ноги, хвост. Он должен знать, что кошка мяукает. И он начинает спрашивать себя, был ли у этой предположительной кошки хвост? Ног человек не видел, но хвост видел. Звук она издавала такой, какой издает кошка? Да, такой. Значит, из всех гипотез наибольший вес имела гипотеза, связанная с кошкой, и теперь мы убеждены, что эта гипотеза верна. И когда мы в следующий раз столкнемся с подобной ситуацией, первой нашей догадкой будет «кошка». Именно этот подход используют живые системы в процессе восприятия: дети, животные, люди и так далее. Мы его достаточно успешно применили в FineReader, но он имеет настолько общий характер, что мы применяем его для анализа естественных языковых предложений, в процессе извлечения смысла. Мы проводим (начинает загибать пальцы) лексический, морфологический, синтаксический, семантический, то есть полную цепочку анализа естественного языкового массива. А каким образом достраивается внутренняя модель знаний о мире? Все эти знания вводятся… — …экспертами. Да, у нас большой объем ручной работы. Правда, часть нам удалось автоматизировать; к счастью, есть методы, позволяющие снизить нагрузку на экспертов. Но рассказывать об этом я пока не могу. Конечные пользователи и сами смогут дообучать систему. Продукты такого рода должны быть модифицируемы и самообучаемы — иначе они теряют смысл. Как конкретно это реализовано — тоже говорить еще рано. Не может ли случиться так, что в результате ошибочно заложенных знаний стандартом станет какое-нибудь неверное представление? — Ну, это общая проблема человечества. Это и сейчас происходит. Возьмите Википедию, один человек ошибся, тысяча человек поставила ссылку. Это жизнь. В словаре Ожегова упоминается, что правильно говорить «фо,льга». А все говорят «фольга,». Это, конечно, проблема, но она общего характера и к нашей системе прямого отношения не имеет. А для написания программ вашу систему можно применять? Это ведь во многом более простая задача, чем обработка естественного языка. — В каком-то смысле, да. Есть определенная грамматика, есть смысл и нужно синтезировать этот смысл в правилах заданной грамматики. Сходство имеется, но до конкретной реализации, думаю, еще далеко. Это все равно что сравнить распознавание букв и распознавание отпечатков пальцев. Базовые принципы и там и там одни и те же, но конкретика совершенно разная, разные модели знаний о предмете и т. д. Наш подход может быть применен для построения подобных систем, но это будет совершенно независимый продукт. Слушаю и понимаю Отчаявшись получить хоть какой-то намек, на что будет похож первый продукт на базе NLC, мы пробуем подойти к вопросу с другой стороны. Какие задачи подтолкнули к созданию этой системы? — Падение Вавилонской башни. То есть все же лингвистические? — Дело не только в языках. Дело в знаниях. Количество информации, порождающейся ежедневно, ежесекундно, растет в геометрической прогрессии, и очень скоро нас ожидает если не комбинаторный взрыв, то, по меньшей мере, значительные проблемы с доступом к этой информации. Но это только иллюстрация. То, что человечеству необходимы системы, позволяющие накапливать знания и обеспечивать к ним формальный доступ, совершенно очевидно. Возьмем, например, проблему распознавания слитной речи без настройки на голос диктора. В ее практической необходимости никто не сомневается. Можно ли сделать это с помощью компьютера? Ответ очень простой. Если проанализировать звуковой сигнал, записанный на этом диктофоне, то обнаружится, что семьдесят процентов изначальной информации было утеряно в процессе записи. А при этом уровне шума — все восемьдесят, а то и девяносто, местами. Тем не менее расшифровать наш разговор можно будет на 99 процентов, если не больше. Почему? Как вы можете достичь такого результата, если этих данных физически нет в сигнале? Потому что вы не распознаете, а домысливаете. Точно так же во время нашего разговора ухо, как любой микрофон, теряет часть информации на входе. Собственно, мозг распознает только тридцать процентов информации, все остальное ему приходится додумывать на основе априорных знаний о языке, смысле и знании предмета (прагматических знаний). Проверить это довольно просто. Если бы я сейчас продиктовал вам предложение по-армянски, вы бы смогли правильно записать только тридцать процентов букв, хотя армянские буквы в целом похожи на русские (здесь имеется в виду не схожесть алфавитов, а фонетическая схожесть. — Прим. ред.). И мы понимаем, что задача распознавания слитной речи — в меньшей степени задача распознавания, а в большей — задача понимания. И сколько времени пройдет между выпуском NLC и выходом первой системы распознавания слитной речи? — Много. К сожалению, устная речь сильно неформализована, в ней зачастую не соблюдаются законы семантики, так что один этап анализа практически выпадает. Также сложно применять синтаксический анализ: неполные, оборванные предложения, где заканчивается одно предложение и начинается другое — непонятно. Плюс интонационные нюансы. Тонкостей здесь масса. Так что о работающей системе распознавания слитной речи говорить пока рано. Но довольно быстро появятся системы, которые распознают речь не так хорошо, как люди, но во много раз точнее, чем сейчас. Они будут успешно работать в ситуации, когда озвучивается письменная речь — например, при чтении доклада. Наш с вами разговор или, скажем, телефонный разговор или непринужденная беседа на бытовые темы людей, которые хорошо друг друга знают и понимают, что называется, с полуслова — здесь уже сложнее, конечно. А эксперименты «Яндекса» и Google в области семантического анализа близки к тому, что делает ABBYY в проекте NLC? — Google и «Яндекс», конечно, понимают важность таких технологий, и я абсолютно убежден, что к моменту появления NLC на рынке появится некоторое количество технологий, заявляющих примерно то же направление. Но у меня внутреннее ощущение, что подход ABBYY, которая потратила на разработки десять лет, существенно глубже. Я вполне могу допустить даже то, что в первые годы технологии Google, «Яндекс» и других фирм могут оказаться даже эффективнее наших, потому что они настраиваются на решение конкретной задачи, четко поставленной, с понятным результатом. Они не пытаются решить проблему в принципе. Но в дальней перспективе нам неизвестны чужие разработки, которые настолько глубоко и последовательно пытаются решить задачу понимания в общей постановке. Я могу сказать, что еще пару лет назад весь этот проект для нас оставался очень рискованным вложением. У нас не было уверенности, что это вообще будет работать. Но сейчас есть основания надеяться на лучшее. На самом деле, Давид рассказал нам немного больше, однако он сам был не уверен, чем стоит делиться, а чем — нет. В результате довольно значительная (и самая, пожалуй, интересная) часть разговора в этот материал не вошла. Задачки и задачи — Я не являюсь менеджером компании, я не контролирую ни одного человека напрямую. У этого проекта есть научные консультанты, руководитель разработки, огромная команда, целый этаж сидит. Как и когда мы будем объявлять об этом — во многом зависит от их готовности. Я же в компании появляюсь раз в неделю. Да и то хожу на занятия китайского, которые проводит мой отец, поэтому не всегда обладаю всей необходимой информацией для принятия такого решения. Раз уж речь зашла о компании, то имеет смысл поинтересоваться, как ABBYY в условиях кадрового кризиса в ИТ может позволить себе столь жесткий отбор при приеме на работу. Претендент не только проходит несколько собеседований, но и сдает экзамен на логику. И только после этого его берут на работу. Стажером. На полгода. А там уж решают, расставаться с ним или нет. — Конечно, мы тоже столкнулись с кризисом, но планку снижать не можем, иначе процесс снижения станет необратимым. Дело в том, что если определенный процент сотрудников компании обладает некой компетенцией, духом, волей к победе, то остальные, даже если они не до конца отвечают этим идеалам, понемногу подтягиваются. У системы есть некоторый иммунитет. Она либо отторгает людей совсем далеких, либо ассимилирует в себе тех, кто может встроиться. Но если людей, не способных к ассимиляции, будет слишком много, то процесс становится неуправляемым, и на исправление ситуации могут уйти годы. Поэтому, несмотря на дефицит кадров, мы сторонники жесткого отбора. Первый раунд — это изучение резюме. Если резюме нам нравится, то мы приглашаем человека на экзамен, где ему предлагается решить шесть логических задач. Если он с этим справился, его ожидает интервью с работником отдела кадров и непосредственным руководителем, с которым новичку предстоит работать. Если и здесь все проходит хорошо, мы берем его на полгода — срок, на самом деле, не очень жесткий, но обычно все же на полгода, — после чего он сдает квалификационный экзамен. По крайней мере, в R&D это так, у менеджеров, кажется, последнего экзамена нет. Очень много задач из тех, которые давали на собеседование на Физтехе. Вообще, вся эта система оттуда. У нас практически все руководство заканчивало Физтех, сотрудников много оттуда, базовую кафедру мы сейчас там открыли. Первый выпуск ждем через два года, а дальше уже пойдет гарантированный приток сотрудников — хотя и недостаточный. К Физтеху в ABBYY особое отношение, хотя Давид утверждает, что к выпускникам других вузов никакой предвзятости нет. Там тоже иногда можно найти хороших специалистов. — Мы не страдаем шовинизмом. Надо признать, что, к сожалению, несколько лет назад уровень подготовки на Физтехе резко упал по сравнению с тем же Мехматом, например. Вы, кстати, как-то упоминали, что занялись софтом только для того, чтобы заработать некоторое количество денег и вернуться в науку. Но вот уже семнадцать лет не можете покинуть ИТ-бизнеса… — Да, было такое. (Ян смеется.) Но выяснилось, что я никуда не уходил. На самом деле, было время, когда я думал, что предаю свое собственное стремление заниматься наукой, но недавно я защитил кандидатскую в области физико-математических наук ровно по тому, чем мы занимаемся в области оптического распознавания. Формально это, конечно, относится к области математики, а не физики, но методы исследования очень похожи. Разумеется, мы занимаемся инженерной наукой, но в очень интересной области. Это острие, этого еще никто не делал, мы участвуем в научных конференциях, пишем статьи. Мне очень интересно этим заниматься. Физиком я хотел быть с третьего класса, но сейчас мне кажется, что то, чем мы занимаемся, очень нужно, интересно, востребовано, и это наука. ГОЛУБЯТНЯ: Огород для форрестгампов. Часть четвертая Автор: Сергей Голубицкий Сегодня, с божьей помощью, завершим описание алгоритма для быстрого и бескровного создания любительского видеофильма. Вкратце повторю уже проделанные шаги и соответствующие им софтверные решения — итак мы: 1. Слили содержимое miniDV-кассеты на компьютер с помощью программы ScenalyzerLive. 2. Портировали видеоклипы в редактор нелинейного монтажа Ulead MediaStudio Pro 8. 3. Выставили генеральные настройки проект. 4. Обрезали мусор утилитой Multi-trim Video. 5. Создали видеопереходы на монтажном столе. 6. Наложили музыкальную дорожку на видеоряд, предварительно снизив уровень громкости в окне аудиомикшера (Audio Mixing Panel). 7. Приступили к кодированию полученного материала с помощью встроенного в Ulead MediaStudio Pro 8 кодировщика. Справедливо чураясь лишних формул, мы доверили расчет максимально высокого значения видео и аудио потоков фриварной утилитке DVD-Video Bitrate Calculator. Продолжаем. В нашем примере при продолжительности фильма в 1 час 39 минут и выставленном аудиопотоке в 320 kbps, мы получили максимальный поток видео в 5800 kbps. Подставляем эти значения в окно свойств создаваемого видеофайла (меню File-Create-Video File — кнопка Options — закладка Compression, рис. 1). 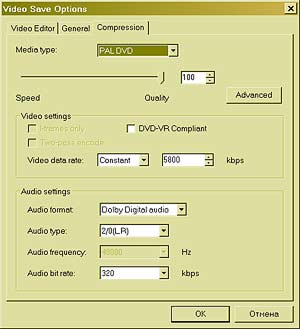 Настройки такие: тип видео — PAL DVD, способ кодирования — постоянный битрейт (Constant), настройки аудио — двухканальный (2.0 LR) Dolby Digital. Комментировать нечего, разве что — выбор способа кодирования. Наверняка найдутся поклонники двухпроходного способа с переменным битрейтом (Variable bitrate two-pass encode), который теоретически ужимает видеофайл лучше, чем битрейт постоянный. С учетом, однако, специфики создаваемого нами шедевра (любительский домашний видеофильм!) и обстоятельств («друзья семьи», приставившие нож к горлу: «Не уйдем, пока не дашь фильму!»), дополнительный ужим не так важен, как время кодирования, которое, как вы понимаете, при двухпроходном переменном битрейте занимает почти в два раза больше времени. Единственная ситуация, при которой переменный битрейт кажется предпочтительным — в вашем фильме высоко динамичные сюжеты (все скачут козлами либо бегают наперегонки с Карлом Льюисом) перемежаются со статичными (застольная дегустация в четыре часа ночи). Придумываем имя нашему видеофайлу и жмем ОК — кодирование начнется автоматически. По описанному алгоритму обрабатываем все видеокассеты, которые планируем разместить на DVD-диске. Все. Заключительный аккорд — авторинг или непосредственное строительство диска. Гамачно-аквалангистский вариант с профессиональной Sonic Scenarist отбрасываем с порога, если только вы не планируете записаться на ускоренные полуторагодовые курсы обучения работе на этом монстре. Вариант встроенного в ОС мелкомягкого Windows Movie Maker не рассматриваем по гигиеническим соображениям: не суть важно, что его кастрированной функциональности хватает для наших задач — само отношение к пользователю как к имбецилу просто оскорбительно). Вариант с Adobe Encore DVD и Ulead Movie Factory также отправляем в корзину: первую — по причине жестокой учебной курвы, вторую — за тяготение к мелкомягкой дурашливости. Помимо этого обе программы переполнены тоннами полуфабрикатных менюшек, заставочек, роликов, картинок, рюшечек и виньеточек, выдержанных в тошнотворно-безвкусном пиндосском стиле [Все эти расплывшиеся в фальшивых ухмылках псевдооптимистические хари разных полов и рас, демонстрирующие кукольно-силиконовое и зубопротезное благополучие]. А эта гадость, как известно, противоречит отказу от комплекса Пазолини, взятому нами за эстетическую основу всего проекта. В силу всего сказанного для авторинга мы задействуем Sony DVD Architect 3, являющей собой головокружительный баланс между суровым профессионализмом и бесхитростной интуитивностью, позволяющей запустить программу и мгновенно приступить к работе на нулевой учебной курве. Сейчас я вам это продемонстрирую. В центре окна «Архитектора» — основное меню нашего DVD диска, от которого мы и будем плясать (рис. 2). 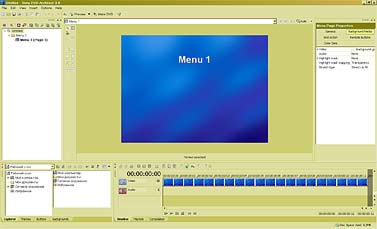 Почему от меню? Потому что в глазах нормального обывателя DVD диск — это не элементы реальной структуры (все эти VMG, VTS, PGC, VOB и IFO, лежащие в основе концепции работы Sonic Scenarist) и уж тем более не пошаговый мастер подсказок (концепция Ulead Movie Factory), а — обыкновенное меню, которое мы видим на экране телевизора и с которым взаимодействуем. Соответственно строительство диска интуитивно правильнее начинать с той же «печки». Правило первое: если не хотите, чтобы над вами смеялись, не создавайте многоуровневых меню со сложной структурой и иерархией — негоже вручную штопать носки и носить при этом на запястье Vacheron Constantin. Видите на экране «Архитектора» картинку с надписью Menu 1? Замечательно: постарайтесь этой страничкой и ограничиться, то есть разместить все элементы вашего меню в одном месте без иерархий и уровней.  Начнем с фона. Можно выбрать из списка шаблонов, но сильно не советую. Только на первый взгляд кажется, что с шаблонами работать быстрее — потом замучаетесь подгонять чужую заготовку под собственные нужды. Поехали — выбираем для фона свою картинку: контекстное меню мыши в окне Menu 1 — опция Set Background Media. Далее меняем заголовок фильма (Menu 1): контекстное меню мыши — Edit Text (или F2) — шрифт и размер подбираем из выкидного списка прямо под окном меню. Пока не забыл: включите отображение границ так называемых безопасных зон экрана — Title Safe и Action Safe Areas. Все элементы вашего меню должны непременно располагаться внутри этих зон для гарантированно правильного отображения на любом телевизоре. Включаем: меню View — опция Workspace Overlay — Show Title Safe Area, Show Action Safe Area. Вот, что у нас вышло (рис. 3). Следующий телодвиг — размещаем на странице меню все видеоклипы фильма: контекстное меню мыши — Insert Media (либо Ctrl+F) — выбираем из списка только что кодированные в Ulead ролики — жмем ОК (рис. 4). 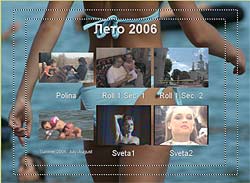 Каждую иконку с клипом задвигаем мышью на положенное (на усмотрение собственного вкуса) место, затем меняем технические названия файлов в надписях на что-нибудь более содержательное: контекстное меню мыши каждой иконки — Edit Text (или F2) — штифт и размер меняем из меню, расположенного прямо под центральным окном программы. Важный нюанс: нужно определить, в каком виде мы хотим видеть иконки с клипами в главном меню — статичном или динамически проигрываемом. Соответственно, из клипа нужно выбрать либо самый эффектный кадр для картинки (при статичном отображении), либо начальная точка проигрывания (при динамическом отображении). Оба действия выполняются в окне Button Properties (Свойства кнопки), расположенном справа от окна меню. Сначала занимаемся статикой-динамикой: выбираем закладку Media, далее — в разделе Thumbnail Properties (Свойства иконки) опция Style — выкидное меню Animated (для динамической проигрывания клипа в иконке меню) либо Still (для статичной картинки) (рис. 5). 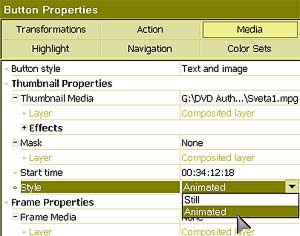 Здесь же — пунктом выше (опция Start Time) — выбираем стартовую точку либо кадр для картинки с помощью бегунка (отображение фильма происходит в соответствующей иконке окна меню) (рис. 6). 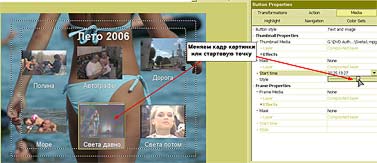 Остался заключительный мазок: определяем т.н. «действие после завершения проигрывания» (End Action) для каждого клипа в нашем меню. В левой части окна выбираем первый клип (в моем примере это «Полина») — в правой части окна (Media Properties) выбираем закладку End Action — опция Destination — из выкидного меню выбираем название следующего клипа («Автографы») (рис. 7).  Повторяем аналогичное действие для всех остальных клипов. В самом последнем («Света потом») указываем в качестве End Action переход в главное меню (в нашем примере «Лето 2006»). Все! Смотрим что получилось: кнопка Preview основного меню программы (либо F9) (рис. 8).  Теперь прожигаем болванку: основное меню «Архитектора» — кнопка Make DVD — опция Burn. Первый этап — подготовка диска (Prepare). Выбираем папку для подготовки (она должна быть пустой!) — жмем «Далее» (рис. 9). 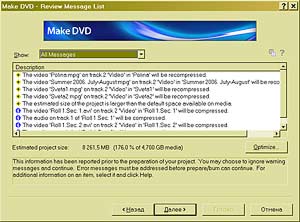 Программа автоматически анализирует созданный нами диск и выдает сообщения о необходимой доработке, как то: ошибки в структуре меню, дополнительная рекомпрессия отдельных клипов, достаточность места на диске и т.д. В нашем примере размер диска — 8,2 гигабайта — превысил размер стандартной (однослойной) болванки, поэтому жмем на кнопку Optimize (Оптимизировать). В открывшемся окне выбираем волшебную опцию — Fit To Disc (Поместить на один диск) (рис. 10). Заодно проследите, чтобы формат видео и аудио соответствовал тому, что вы задали при кодировании в видеоредакторе. Жмем ОК, указываем метку (имя) DVD диска — все остальное выполнит «Архитектор». 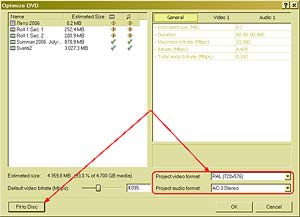 Через полчаса извлеките из дисковода готовую «фильму», вручите ее «друзьям семьи», вежливо выпроводите их из дома, а затем забудьте на ближайшие полгода про видеокамеру и монтаж! SMS: SMSНОСЕЦ Автор: Константин Курбатов Привет!Фильм хорош!Увидев 2 неких кадра на последней секунде,подумал: а не было ли такого ранее? Или это тот самый 25-й кадр и меня зомбируют? :) Тогда зачем показали последние? :) Так держать! =Zemen Террочка, скучаю! Твой Александр Ч. М. Мобыльные ПК, ужос... Аж скрепки повылетали! Всецело ваш, amc. 649-й номер получился просто замечательный. Столько интересного. Отдых хорошо на вас влияет! Мы тоже постоянно твердим об этом издателю, но он почему-то глух к нашим просьбам и что-то говорит о еженедельном графике... Fеаr plаy и fаir plаy (с.4 #29) немного разные вещи,хотя Мicrosoft может их легко спутать:-) привет от Puzzle,т.е. меня:-) Spasibo A.Sornkinu ne tolko za interesnuju staju ob IT v artillerii (KT 645-646), no i za dobroe slovo o voennih. And Доброго времени суток, КТ! У меня тут вопрос возник:#649, стр.27: куда сноску#2 подевали? Неужели ее закрывает баннер от СофтКея? :) Сноска там есть, но для конспирации мы ее припрятали на скриншоте. Свободный софт требует внимательного к себе отношения... #29(649) str.36 статья «Save to disk», автор Е.Рябков. Блеск. Без него мы не знали что царапины — причина смерти дисков. Если на самого Рябкова наступить и повернуться — что ему будет? Графики «после стирки-после кофе» меня совсем добили. Хоре ерундой страдать! Больше голых теток! //Д.А. Боюсь, что если вы наступите на голых теток, они тоже вас добьют. Так что будьте осторожны не только с дисками, но и с тетками. Серж Скаут=С.Кащавцев&С.Вильянов Нет. Это шесть разных человек. А чё это у вас за слово такое — блютус? Вы имеете в виду блуетоотх? Ёнглисх — очень коварный язык, помните об этом! Да. Мы помнить об этом в редакция. Привет! Возник вопрос: почему ваш журнал называется «Компьютерра»? Название хорошее, но откуда оно произошло? P.S. Алкоголь-зло! ZiV Да уж, в двух словах без пол-литры не разберешься. Игрушечный танк в номере о прогрессе... (#650, стр.2) Вспоминаются размышления Торвальдса о сексе, войне и Linux’е. // Юрикс #649 стр 61(с рекламой). Сказано, что можно использовать одновременно 2 людям, а про то, что нужно еще подключать и мышь с клавиатурой ни слова. Все же наша реклама — сама причудливая в мире. Ну как же, там написано, что для этого требуется дополнительное устройство. Не исключено, что речь идет о втором компьютере... Я всё понял,опечатками вы тестируете интерес читателей к некоторым темам или способам отображения инфо. Номер#29(649) стр.43 протестировано отношение к графикам «мобыльные пк» Господа, какой кошмар! Читаю новости и понимаю, что живу в отсталой стране, которая по глупости (а наверное по злому умыслу «нефтяников» ), имея колосальный потенциал пребывает в забвении. Пожалуйста пишите больше о наших достижениях. А то шибко за державу обидно!!! Журавлев Алексей Сделайте что-ли систему учета ссылок для журнальных материалов. Самые частые ошибки в кт — неверные ссылки. То на несуществующую картинку в тексте ссылка, то ,как например в прошлом номере, ссылка на другой материал номера содержит неправильный номер страницы. С уважением к лучшему компьютерному изданию Илья. Мы просто надеялись, что так вы заодно прочитаете и ту статью, на которую указывала неправильная ссылка. ШАБАНОВ THE BEST #29,стр.60. В ответе Гуриева опять встречаются двойные буквы Мы протестировали эстонскую клавиатуру и теперь рекомендуем вам купить ее. #30, стр. 20. Наконец-то, обзор! Огромное удовольствие от прочтения. Рo3gpaBЛRlO c rogoBwuHoщ Bblnycka #603! Ha4aЛ 4umamb KT uMeHHo c Hero u B nЛaHe meMbl HoMepa Hu4ero Лy4we y Bac noka He 6blЛo. Pa3Be 4mo apxumekmypa CPU... /7pI/I837 Xak3p, /73///I\I 3///,3… Номер 651, страница 22, средняя колонка, ответ на третий вопрос, второе предложение. «Разработчики имеют выхода на те иностранные организации ...» внимательнее надо быть. ru.kleptos@gmail.com Они иногда имеют выход, а иногда и не имеют выхода. Раз на раз не приходится. Третий номер подряд нету СМС-рубрики. Это не есть хорошо... Делайте почаще журналы с дисками, и суйте туда мультфильмы с Пятачком в главной роли!) Bobr_VMK Сижу в пробке...В электричке Москва-Ожерелье.Полпервого ночи. Читаю терру — если быне вы, я бы давно уснул :) Так прикрылись бы «террой» и поспали спокойно... #652, Деяния и недеяния. Полностью согласна, но (ох!) пока недостигла такого состояния из-за неистребимых душевных порывов и моральных принципов! Впредь буду ровняться на г-на Гуриева! :o) НИНО Что-то я не увидел в этом прогнозе телепортации. Когда телепортироватся будем? Нет уж, не надо — представьте, что к вам вдруг телепортируются друзья посмотреть футбол как раз в тот момент, когда вы собрались в одиночестве полистать «Компьютерру»? 1, 2, 3, 4, 5, 6, 7, 8 |
|||||||||