 |
|
Популярные авторы:: Картленд Барбара :: Чехов Антон Павлович :: Громов Дмитрий :: Горький Максим :: Андреев Леонид Николаевич :: Толстой Лев Николаевич :: Твен Марк :: Лесков Николай Семёнович :: Коллектив Рубоард :: СССР Внутренний Предиктор Популярные книги:: Справочник по реестру Windows XP :: Бурый волк :: Пичугин мост :: Мясоеды :: Марсианский прибой :: Течет река Волга… :: Информационный листок украинской фантастики N 17-2003 (157) :: Игры оборотней :: Пять рассказов о знаменитых актерах (Дуэты, сотворчество, содружество) :: Похититель талантов |
Компьютерра (№255) - Журнал «Компьютерра» № 20 от 30 мая 2006 годаModernLib.Net / Компьютеры / Компьютерра / Журнал «Компьютерра» № 20 от 30 мая 2006 года - Чтение (стр. 8)
Про последний же пункт стоит рассказать чуть подробнее. Благодаря тому, что практически все составляющие фильма (включая исходники для Blender) выпущены по лицензии Creative Commons и доступны, каждый желающий может использовать эти ресурсы для своих собственных проектов (включая коммерческие). Можно посмотреть, как делаются те или иные вещи (Blender — как почти любой свободно распространяемый софт — не может похвастать хорошей документацией) и использовать это знание при создании своих фильмов. А можно взять уже готовых персонажей, нарисовать другие бэкграунды и сделать совершенно новый фильм. Или еще проще — перемонтировать и переозвучить то, что уже есть, еще сильнее сократив время на подготовку «своей» картины. Если пример Orange Movie Project окажется заразительным, то уже через несколько лет из искры может разгореться пламя, и на смену музыкальным ремиксам придут полноценные видеоремиксы, собранные из общедоступных кирпичиков (сцен, персонажей, бэкграундов и т. д.). Сдерживающих факторов всего два. Во-первых, не очень понятно, кто будет создавать эти кирпичики, — заинтересованность Orange Movie Project очевидна, но только их усилий для этого явно не хватит. Во-вторых — неподъемные для обычного пользователя требования к вычислительным ресурсам. Впрочем, высокие требования к ресурсам — фактор временный. Десять лет назад многое из того, что сегодня считается обыденным, — например, редактирование видео на домашнем компьютере, — казалось фантастикой. Так что не исключено, что «Elephants Dream» — это первая ласточка, знаменующая наступление новой эпохи в 3D-анимации, когда создание мультфильма будет доступно даже любителям (пусть не совсем самостоятельного, а по следам чужих разработок). Что же до художественной ценности — так знаменитое «Прибытие поезда» с кинематографической точки зрения тоже, если честно, не шедевр. Ну какой там сюжет? Поезд из Воркуты прибывает на второй путь. Вот, собственно, и все. А люди помнят. ОПЫТЫ: Видео ремонт Автор: Филипп Казаков Когда домашние кинотеатры маячили где-то на горизонте, а бытовые DVD-плейеры только-только появились и стоили по 500—700 долларов, я очень удивлялся, зачем люди их покупают. Ведь за те же деньги можно собрать компьютер, который воспроизводит музыку, DVD, кривые пиратские «дивиксы» да еще и делает в тысячу раз больше, чем умели и сейчас умеют бытовые проигрыватели. Ответ на этот вопрос печален в своей банальности: бытовыми плейерами гораздо проще пользоваться. Единственное, что требуется от счастливого покупателя ширпотреба, — подключить его к телевизору двумя-тремя проводками, вставить диск и нажать кнопку на пульте. А вот чтобы сделать видеоплейер из своего домашнего компьютера, придется потрудиться: снизить шум системного блока, поставить операционную систему, плейеры, кодеки, купить специальные кабели и соединить выходы звуковой и видеокарты с телевизором, докупить пульт ДУ и наконец настроить все это хозяйство. Дело, прямо скажем, гораздо более мозгоемкое. Кроме того, компьютер, в отличие от узкоспециализированного устройства, штука капризная, и настроение его может меняться. Хоть беспричинных глюков не бывает, порой трудно понять, с чего вдруг перестали играться видеофайлы. Давайте попробуем проанализировать главные причины возникновения проблем при воспроизведении видео на компьютере под управлением Windows. Даже если эта статья не поможет вам локализовать неисправность, вы, по крайней мере, будете знать, в каком направлении «рыть землю». Разумеется, прежде чем начинать диагностику, следует выбрать заведомо «не битый» видеофайл, то есть полученный из надежных источников либо нормально воспроизводящийся на других компьютерах. Также следует заранее удостовериться, что проблемы не связаны с нехваткой системных ресурсов. С этой задачей, уверен, читатели «Компьютерры» справятся самостоятельно. Первая по распространенности причина неполадок с воспроизведением видео кроется в неправильном режиме работы CD/DVD-ROM-драйва. Вместо DMA, то есть режима прямого обращения к памяти, оптический привод почему-то переключается в режим PIO, при котором вся считываемая информация прогоняется через процессор, что катастрофически сказывается на его загрузке. Диагностировать это очень просто: из Диспетчера устройств зайдите в свойства вашего IDE-контроллера, где в закладке «Дополнительные параметры» указан режим работы каждого из каналов устройства. Если на канале с приводом активен PIO-режим, поменяйте его на DMA. Не поможет — обновите драйвер или удалите контроллер из системы: после перезагрузки ОС все может встать на свои места. Если эти очевидные меры не помогают, придется лезть в Сеть с поисковым запросом «DMA PIO». Эта проблема имеет с десяток причин и методов решений. Если с режимом работы у вашей «читалки» все о’кей, для дальнейшей диагностики лучше все равно скопировать проблемный файл на винчестер. 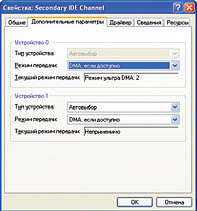 Выполнив предварительную диагностику, переходим к детальным исследованиям. Абсолютное большинство видеопроигрывателей для Windows используют разработанную Microsoft технологию DirectShow. Ее особенность заключается в том, что видеоплейер не заботится о декодировании входного файла: при воспроизведении медиафайлов поток данных последовательно проходит через цепочку специальных системных библиотек обработки — DirectShow-фильтров, — каждый из которых производит с ним одну узкоспециализированную операцию. Таким образом, теоретически процесс декодирования видеофайла не должен быть привязан к конкретному ПО, инициализировавшему его запуск. Однако это только в теории, а на практике популярных видеоплейеров очень много, и далеко не все они корректно общаются с DirectShow-интерфейсом, а многие и вовсе игнорируют его, используя свои собственные декодеры. Чтобы во время диагностики исключить возможность влияния плейера, воспользуемся бесплатной утилитой GraphEdit[Скачать ее можно с www.videohelp.com/download/graphedit041201.zip.] от Microsoft, предназначенной, в частности, для «низкоуровнего» доступа к DirectShow-фильтрам. Перетягиваем файл-пациент в рабочее поле GraphEdit. Далее возможны четыре варианта развития событий. 1. Файл открывается в GraphEdit, в результате чего на экране строится цепочка прямоугольников-фильтров, а после нажатия треугольной стрелочки в панели инструментов (старт рендеринга) видео проигрывается без всяких проблем. Не обязательно быть Шерлоком Холмсом, чтобы понять: виновник всех прошлых глюков — ваш программный плейер. Меняйте плейер или попытайте счастья на сайте его разработчика: возможно, уже вышла более стабильная версия. 2. GraphEdit выдает сообщение, начинающееся со слов «Could not construct a graph from this file». Несмотря на грозный вид сообщения и пугающий код ошибки, ничего страшного в нем нет. Оно всего лишь означает, что в системе установлены не все декодеры и сплиттеры, требующиеся для воспроизведения файла. Достаточно скачать из Сети нужные кодеки, и файл заиграет (по крайней мере, должен заиграть). Если вы не знаете, каким кодеком закодирован ваш файл, придется отправиться на разведку. Главное, удержаться от соблазна скачать и установить какой-нибудь многомегабайтный Megamax Codec Pack Plus (если, конечно, вы этого еще не сделали) — подобные «паки», неизвестно кем и как собранные, не столько решают проблемы, сколько создают новые. Чтобы определить формат медиапотоков вашего файла, сначала обратите внимание на его расширение (в большинстве случаев оно однозначно указывает на используемый контейнер). Если это .avi, в нем легко разберутся специальные утилиты: AVIcodec[avicodec.duby.info] или GSpot[www.headbands.com/gspot]. Если это .mkv, .ogm, или .mpg — поможет VirtualDubMod[sourceforge.net/projects/virtualdubmod]. Более редкие контейнеры (.mp4, .ts, .264, .rm, .vob и др.) обычно определяют и кодеки, которыми внутри сжато аудио и видео, так что софт, необходимый для воспроизведения файлов такого типа, легко находится через Яндекс с Гуглом.  3. Файл открылся, цепочка построена, но при попытке рендеринга происходит ошибка или падает GraphEdit. Эта малоприятная ситуация означает, что либо цепочка фильтров построена неверно, либо глючит одно из ее звеньев. Чтобы решить эту проблему, нужно построить правильную цепочку фильтров, запуск которой приведет к корректному воспроизведению файла. Добавлять фильтры можно из меню Graph > Insert Filters > DirectShow Filters, а связывать их в цепочки — курсором мыши. Ориентируйтесь по скриншотам: на них приведены иллюстрации правильных цепочек для основных типов контейнеров[Для редких видеокарт (например, Matrox G400) приведенные цепочки несправедливы]. Если нужных декодеров и сплиттеров в системе не обнаружится, их придется скачать и установить, но в любом случае, какой бы файл вы ни декодировали, принцип построения цепочек один и тот же. После того как вы найдете правильную цепочку, результат нужно будет как-то зафиксировать, чтобы любой открываемый файл подобного типа по умолчанию декодировался по правильной цепочке. К сожалению, в Windows нет встроенных средств для управления приоритетами DirectShow-фильтров, так что для этого нужна отдельная утилита, например DirectShow Filter Manager[www.softella.com/dsfm/index.ru.htm]. Будьте очень аккуратны при ее использовании — она затрагивает глубинные настройки операционной системы. Слишком резкое изменение приоритетов может привести к неприятным сюрпризам. 4. Файл в GraphEdit открылся, цепочка фильтров построена и работает, однако исходная проблема упорно не исчезает. Что ж, продолжим эксперименты. Следующий шаг — проверка видео других типов. Постарайтесь найти побольше самых разных видеофайлов и проверить их в GraphEdit. Если все остальные типы файлов играются нормально, а глючит только один кодек или контейнер, возвращайтесь к предыдущему пункту. Ежели выяснится, что глюки никак не связаны с форматом видео, — дела плохи, причина лежит на более низком, чем DirectShow, уровне. Вероятнее всего, она связана с воспроизведением декодированной информации видеокартой (или аудио в крайне редких случаях). Попробуйте обновить DirectX, переставьте драйверы видеокарты. Проверьте, работает ли overlay-режим воспроизведения видео, поиграйте с другими настройками драйвера или поищите его более древнюю версию. Как ни странно, в исключительных случаях последняя мера может помочь — как-то мне довелось ставить современную AGP4x-видеокарту на устаревшую материнскую плату на легендарном чипсете i440BX. Система стабильно работала в 3D, а при воспроизведении overlay-видео зависала. Проблема решилась установкой драйвера позапрошлого поколения. 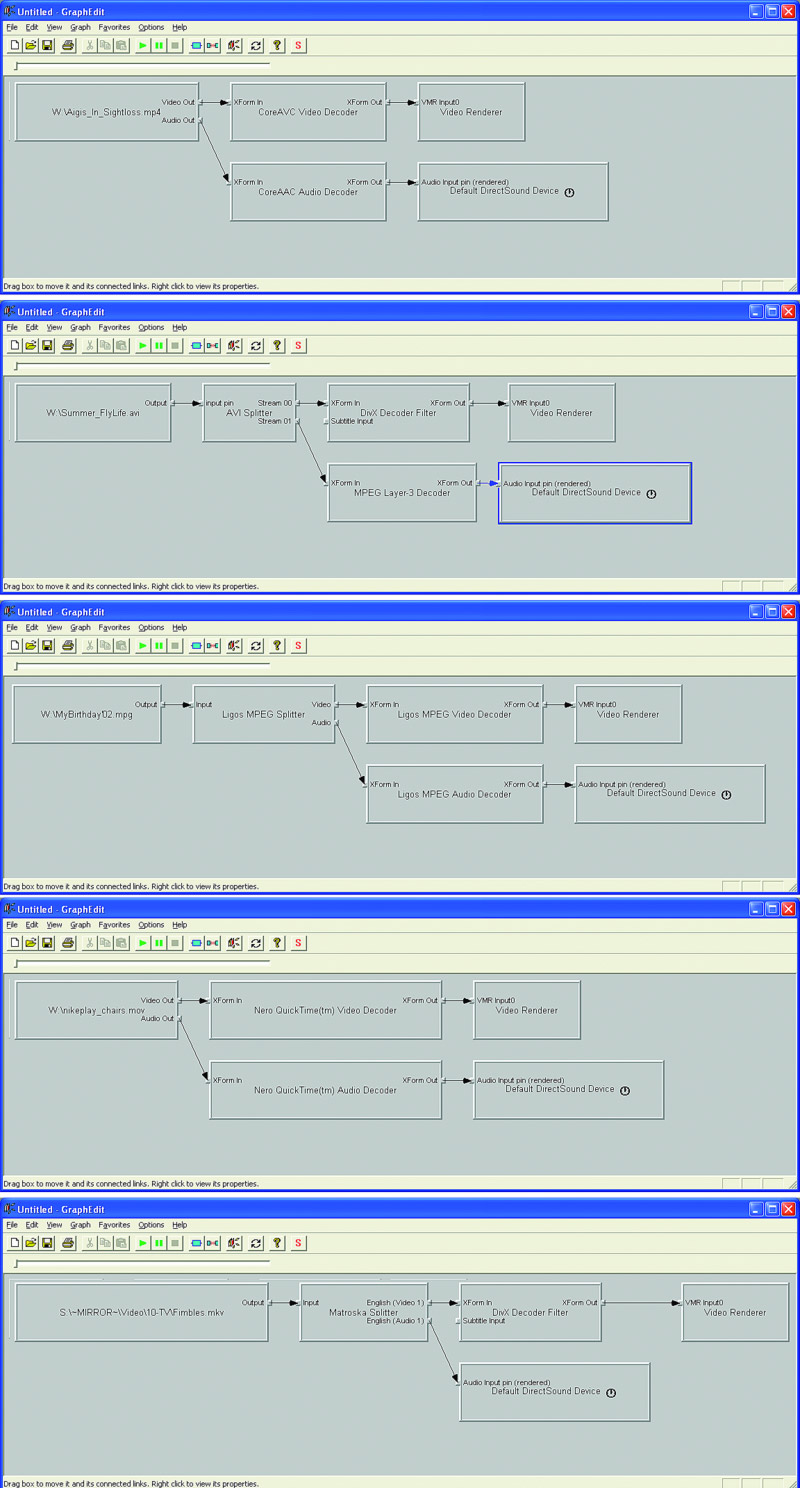 Как показывает практика, четвертый вариант развития событий встречается редко, обычно неприятности случаются из-за конфликтов DirectShow-фильтров. И это легко объяснимо: политика Windows позволяет любому приложению устанавливать в систему свои DirectShow-фильтры, никак не иллюстрируя этот процесс и не спрашивая согласия пользователя. К примеру, установив Nero Burning ROM — известную утилиту для записи CD/DVD-дисков, — можно обнаружить, что парк DirectShow-фильтров неожиданно пополнился декодерами от Nero, казалось бы, не имеющими никакого отношения к нарезке болванок. И этот случай далеко не единственный — многие известнейшие продукты, напрямую не относящиеся к воспроизведению видео и звука, ведут себя аналогично. Таким образом, на перегруженном программными продуктами компьютере скапливается немало фильтров от разных производителей, далеко не всегда корректно взаимодействующих друг с другом.  Окончательно запутывают ситуацию уже упоминавшиеся Codec Pack’и, якобы содержащие в одном инсталляционном файле декодеры для всех возможных форматов видео и аудио. Да, действительно, на момент сборки они, возможно, поддерживают большую часть актуальных форматов. Однако последствия одновременной установки большого количества фильтров совершенно непредсказуемы, ведь заранее узнать, «подружатся» ли они с текущим набором декодеров конкретной системы, невозможно. Хорошо еще, если на случай «не подружатся» сборщик Codec Pack’a позаботится о правильной процедуре деинсталляции своего детища, а если нет?.. Так что залог видеоздоровья компьютера — установка по отдельности минимума необходимых декодеров. Тогда, возможно, и эта статья вам не пригодится. Детали: Ускоряем JavaScript Автор: Хендерсон, Кэл Кажется, всего несколько дней назад мы рассказывали вам об истории Flickr, и вот — статья, написанная главным разработчиком этой компании Кэлом Хендерсоном. Статья довольно специфичная — это вполне конкретные советы по решению вполне конкретных проблем, с которыми может столкнуться практически любой веб-разработчик. Как правило, мы стараемся не публиковать материалы такого плана, однако и Веб 2.0 — штука довольно новая, и проблемы, которые поднимает Хендерсон, далеко не для всех очевидны (что уж говорить о способах их преодоления), и литературы, освещающей эти вопросы, тоже не очень много, — к сожалению, большинство авторов компьютерных книжек делает упор на подробное описание синтаксиса, избегая рассуждать о тонкостях применения тех или иных техник. Хендерсон на синтаксис не отвлекается. Не рассказывает он и о том, как делать приложения, активно использующие JavaScript и CSS. Его интересует другое — «как сделать эти приложения по-настоящему интерактивными и быстрыми». — В.Г.  Так называемые приложения Веб 2.0 предполагают более интенсивное использование CSS и JavaScript, чем раньше. Но для быстрой и качественной работы приложения мы должны оптимизировать размер и выдачу контента, который требуется для рендеринга страницы. На практике это означает, что мы должны сделать статический контент настолько маленьким и быстрым для загрузки, насколько это возможно, избегая немотивированной раздачи файлов, которые не претерпели изменений. Эта задача несколько усложняется самой природой файлов CSS и JavaScript. В отличие от изображений, исходный код CSS и JavaScript скорее всего с течением времени будет меняться неоднократно. И нам нужно, чтобы после каждого изменения клиенты могли загрузить обновленные версии файлов, не пытаясь использовать старые версии, сохраненные в их локальном кэше (а также во всех кэшах, которые встретятся по пути). В этой статье мы обсудим, как облегчить жизнь пользователю — при первой и последующих загрузках страницы, а также по мере того, как приложение развивается и обновляется. Кроме того, мы должны максимально упростить жизнь разработчиков, так что обсудим заодно и способы автоматизации процессов оптимизации. Немного предварительной возни позволит нам совместить легкость разработки с удобством использования — и все без изменения привычных практик. Монолит Раньше считалось, что максимальной производительности можно добиться, объединив многочисленные CSS— и JavaScript-файлы в более крупные блоки. Вместо десятка JavaScript-файлов по 5 Кбайт каждый мы делали один файл размером 50 Кбайт. Хотя общий размер кода при этом не менялся, мы сокращали накладные расходы на обработку HTTP-запросов. Также важен аспект распараллеливания. По умолчанию и IE и Mozilla/Firefox при использовании стабильного соединения загружают только два файла с одного домена (см. спецификацию HTTP 1.1, секция 8.1.4). Это означает, что пока не загрузятся все скрипты, мы не загружаем картинки. Все это время пользователи видят страницу без изображений. Однако у этого подхода есть и недостатки. Совмещая все наши ресурсы, мы заставляем пользователя загружать всё и сразу. Разделив содержимое между разными файлами, мы могли бы распределить тяжесть загрузки поверх нескольких страниц (или вообще избежать загрузки отдельных блоков — зависит от поведения пользователя). Если же мы замедлим загрузку первой страницы, чтобы ускорить загрузку всех остальных, то можем столкнуться с тем, что второй страницы многие пользователи просто не дождутся. Исторически этот крупный недостаток такого подхода нечасто брался в расчет. Но для системы, в которой постоянные изменения содержимого статических файлов — обычное дело, это важно, поскольку любое изменение в большом едином блоке требует, чтобы клиент перегрузил себе полный рабочий набор CSS или JavaScript. Если приложение представляет собой монолитный исходник на JavaScript размером 100 Кбайт, значит, каждая мелочь приводит к принудительной загрузке лишних 100 Кбайт. Один в поле не воин В качестве альтернативного подхода постараемся придерживаться золотой середины. Разобъем наши CSS— и JavaScript-ресурсы на множество подфайлов, сохраняя в то же время количество этих файлов функционально невысоким. С одной стороны, нам удобно разрабатывать приложения, разбивая код на логические блоки. С другой стороны, для работы приложения важно, чтобы этих блоков было не слишком много (так что нам приходится объединять эти файлы). Компромисса можно добиться, сделав определенные добавления к системе сборки билдов (набор инструментов, превращающий «грязный» код разработки в рабочий, готовый для развертывания код). Для прикладного окружения, в котором среда разработки и среда исполнения четко разделены, подойдут простые техники управления кодом. Пусть в среде разработки код для пущей ясности разбит на множество логических блоков. Создадим в Smarty (язык шаблонов для PHP) простую функцию загрузки JavaScript: {insert_js files="foo.js,bar.js,baz.js"} function smarty_insert_js($args){ foreach (explode(‘,’, $args[‘files’]) as $file){ echo «n"; Пока все просто. Но затем мы во время сборки билда объединяем нужные файлы. Представьте, что в нашем примере мы должны объединить foo.js и bar.js в foobar.js, раз уж они почти всегда подгружаются вместе. Учтем этот факт при настройке нашего приложения и модифицируем код с учетом этой информации: {insert_js files="foo.js,bar.js,baz.js"} # map of where we can find .js source files after the build process # has merged as necessary $GLOBALS[‘config’][‘js_source_map’] = array( ‘foo.js’ => ‘foobar.js’, ‘bar.js’ => ‘foobar.js’, ‘baz.js’ => ‘baz.js’, function smarty_insert_js($args){ if ($GLOBALS[‘config’][‘is_dev_site’]){ $files = explode(‘,’, $args[‘files’]); $files = array(); foreach (explode(‘,’, $args[‘files’]) as $file){ $files[$GLOBALS[‘config’][‘js_source_map’][$file]]++; $files = array_keys($files); foreach ($files as $file){ echo «n"; Исходный код шаблонов не меняется, что позволяет нам сохранять эти файлы разделенными во время разработки. Кроме того, мы можем написать собственный процесс объединения на PHP и использовать тот же самый конфигурационный блок при самом объединении (а использование одного и того же конфигурационного файла избавляет нас от необходимости синхронизации). А если брать по максимуму, то можно проанализировать использование скриптов и стилей на страницах сайта, чтобы определить, какие именно файлы лучше объединять (хорошие кандидаты для такого объединения — это файлы, которые почти всегда подгружаются вместе). В случае с CSS можно начать с полезной модели, состоящей из двух стилей: основного стиля и стиля подраздела. Единый основной стиль используется во всем приложении, а разные стили подразделов контролируют разные функциональные области. В этом случае подавляющее большинство страниц подгружают только два стиля (один из которых кэшируется при первой загрузке — это, конечно, основной). Для небольших наборов CSS и JavaScript такой подход может замедлить обработку первого запроса (в сравнении с «монолитным» подходом), но если сохранять количество компонентов на относительно низком уровне, то возможно и ускорение работы, поскольку в расчете на одну страницу приходится загружать меньше данных. Сжатие Когда речь заходит о сжатии, многие немедленно вспоминают mod_gzip. Однако с ним нужно соблюдать осторожность — mod_gzip, в общем-то, является злом или, по меньшей мере, причиной кошмарного расходования ресурсов. Основная идея сжатия проста. Браузеры, запрашивая ресурсы, указывают в заголовке, в каком виде они могут принять содержимое страницы. Это может выглядеть, например, так: Accept-Encoding: gzip,deflate Видя такой заголовок, сервер сжимает отсылаемое содержимое методами gzip или deflate с тем, чтобы клиент распаковал его на месте. Это загружает процессор как на клиенте, так и на сервере, однако уменьшает объем передаваемых данных. Это нормально. Однако вот как работает mod_gzip: он сжимает данные во временный файл на диске, а после отсылки данных удаляет этот файл. На больших системах вы очень быстро столкнетесь с ограничениями скорости ввода/вывода. Этого можно избежать, используя вместо mod_gzip mod_deflate (только в Apache 2), поскольку последний сжимает данные в оперативной памяти. Пользователи первой версии Apache могут создать RAM-диск и хранить временные файлы mod_gzip там — это не так быстро, как работа напрямую с оперативкой, но намного шустрее, чем писать все на жесткий диск. Но даже без этого мы можем полностью избежать вышеописанных проблем, используя предварительное сжатие нужных статических ресурсов и последующую отправку их клиенту с помощью mod_gzip. Если добавить предварительное сжатие в сборку билда, то сам процесс пройдет для нас совершенно незаметно. Файлов, требующих упаковки, обычно не так уж много — мы не сжимаем изображения (поскольку это вряд ли приведет хоть к какой-то экономии — изображения и так уже достаточно сжаты), так что нам остается упаковать JavaScript, CSS и прочий статический контент. Но мы должны указать mod_gzip, где искать файлы для предварительной компрессии: mod_gzip_can_negotiate Yes mod_gzip_static_suffix .gz AddEncoding gzip .gz В последних версиях mod_gzip (от 1.3.26.1a и выше) для автоматической предварительной упаковки файлов в конфигурационных опциях достаточно добавить одну строчку. Нужно лишь удостовериться, что в Apache установлены корректные разрешения на создание и перезапись упакованных файлов. mod_gzip_update_static Yes Но не все так просто. Текущие версии Netscape 4 (точнее, 4.06—4.08) в заголовке утверждают, что понимают содержимое, сжатое с помощью gzip, однако, на самом деле, не умеют распаковывать эти архивы. Прочие версии Netscape 4 тоже испытывают разнообразные трудности с загрузкой сжатых скриптов и стилей. А значит, мы должны отсекать этих агентов на стороне сервера и подставлять им неупакованный контент. Это довольно просто. Куда интереснее проблемы, возникающие у Internet Explorer (версии с 4 по 6). Загружая сжатый с помощью gzip JavaScript, Internet Explorer порой некорректно распаковывает его или прерывает распаковку в процессе, отдавая клиенту половину файла. Если для вас критична работоспособность JavaScript, вы должны избегать отсылки сжатых скриптов по запросу IE. Даже в тех случаях, когда IE способен загрузить сжатый JavaScript, он зачастую не кэширует его, независимо от указаний, записанных в тегах (актуально для некоторых версий IE 5.x). Поскольку сжатие с помощью gzip иногда выходит себе дороже, мы можем обратиться к другим способам упаковки контента, не предполагающих смену формата. Сейчас доступно множество скриптов, сжимающих JavaScript, большая часть которых использует для уменьшения исходного кода наборы правил на основе регулярных выражений. С их помощью мы действительно можем сделать код меньше, удалив комментарии, лишние пробелы, сократив имена переменных и убрав необязательные синтаксические конструкции. К сожалению, подавляющее большинство этих скриптов либо не слишком эффективны, либо в определенных случаях разрушают код (а иногда — и то и другое вместе). Без подробного грамматического разбора упаковщику трудно отличить комментарий от похожей конструкции, размещенной в закавыченной строке. Кроме того, с помощью регулярных выражений не так-то просто оценить, какая из переменных имеет ограниченный контекст, так что некоторые техники сокращения имен переменных могут разрушить сам код. Этих проблем можно избежать, сжимая код с помощью Dojo Compressor (alex.dojotoolkit.org/shrinksafe), использующий Rhino (мозилловский JavaScript-движок, написанный на Java) для построения дерева, которое оптимизируется перед работой с файлами. С работой Dojo Compressor справляется неплохо, ресурсов отнимает немного. Расширив наш процесс сборки билда с помощью этого инструмента, мы можем забыть об экономии, писать пространные комментарии, вставлять сколько угодно пробелов и т. д. На рабочем коде это нисколько не отразится. По сравнению с JavaScript CSS упаковывать легко. Поскольку в стилях практически не используются закавыченные строки (как правило, это пути или названия шрифтов), мы можем справиться с пробелами с помощью регулярных выражений. Если же у нас закавыченные строчки все же есть, мы почти всегда можем свести последовательности пробелов к одному пробелу (маловероятно, что последовательности, состоящие из нескольких пробелов, встретятся нам в указаниях путей или названиях шрифтов). Для этого нам вполне хватит простенького скрипта на Perl: #!/usr/bin/perl my $data = ‘’; open F, $ARGV[0] or die «Can’t open source file: $!»; $data .= $_ while $data =~ s!/*(.*?)*/!!g; # remove comments $data =~ s!s+! !g; # collapse space $data =~ s!} !}n!g; # add line breaks $data =~ s!n$!!; # remove last break $data =~ s! { ! {!g; # trim inside brackets $data =~ s!; }!}!g; # trim inside brackets print $data; «Скормим» этому скрипту все имеющиеся у нас CSS по очереди: perl compress.pl site.source.css > site.compress.css С помощью такой несложной оптимизации мы можем уменьшить объем передаваемых данных на 50 процентов (во многом это зависит от вашего стиля кодирования — выигрыш может быть и гораздо меньше), а значит, увеличить скорость работы конечного пользователя. Но в идеале нам хотелось бы, чтобы пользователи вообще не запрашивали файлы до тех пор, пока это не станет совершенно необходимо. И для этого нам придется заняться HTTP-кэшированием. Твой друг кэш Когда пользовательский агент запрашивает данные с сервера первый раз, он кэширует ответ, чтобы избегать повторных запросов в будущем. Как долго будет храниться этот кэш, зависит от двух факторов — настроек агента и соответствующих заголовков с сервера. Опции настройки агентов имеют незначительные различия, однако большинство из них сохраняет кэш по меньшей мере до окончания сессии, если им прямо не указано обратное. Вы посылаете заголовки, запрещающие кэширование динамических страниц, чтобы не позволить браузеру кэшировать страницы, которые постоянно изменяются. В PHP это делается с помощью одной строчки: header(«Cache-Control: private»); Слишком просто, чтобы быть правдой? Ну, в общем-то, да — некоторые агенты порой игнорируют этот заголовок. Чтобы по-настоящему запретить браузеру кэшировать документ, следует быть немного более убедительным: # ‘Expires’ in the past header(«Expires: Mon, 26 Jul 1997 05:00:00 GMT»); # Always modified header(«Last-Modified: „.gmdate(„D, d M Y H:i:s“).“ GMT»); # HTTP/1.1 header(«Cache-Control: no-store, no-cache, must-revalidate»); header(«Cache-Control: post-check=0, pre-check=0», false); # HTTP/1.0 header(«Pragma: no-cache»); Это годится для контента, который мы не хотим кэшировать, но если контент не меняется при каждом запросе, нам нужно добиться от браузера обратного поведения. Для этого в заголовке запроса используется конструкция If-Modified-Since. Получив такой запрос, Apache (или любой другой веб-сервер) может выдать код 304 (Not Modified), тем самым сообщая браузеру, что у того в кэше уже находится актуальная версия документа. Благодаря этому механизму, нам не приходится пересылать файл заново, однако лишний запрос обрабатывать все же пришлось. Гм. Использование entity tags похоже на работу с конструкцией if-modified-since. Apache на запрос к статическому ресурсу может отдавать заголовок Etag, содержащий контрольную сумму, сгенерированную из размера файла, времени последнего изменения и номера индексного дескриптора. Браузер может запросить заголовок файла, чтобы проверить e-tag документа перед загрузкой. Очевидно, что использование e-tag сопряжено с теми же накладными расходами, что и механизм if-modified-since, — клиент все еще вынужден делать лишний HTTP-запрос, чтобы определить валидность локальной копии. Кроме того, нужно соблюдать осторожность с if-modified-since и e-tags, если выдача контента идет с нескольких серверов. В системе из двух хорошо сбалансированных серверов любой документ может быть запрошен одним и тем же агентом с любого из двух серверов — или с каждого (не одновременно). Это нормально. Для этого мы и выравнивали нагрузку. Однако если серверы генерируют разные e-tags или разные даты изменения документов, браузер не сможет нормально поддерживать актуальный кэш. По умолчанию e-tag генерируются с использованием индексных дескрипторов, которые на разных серверах разные. Это можно запретить с помощью следующей опции в настройках Apache: FileETag MTime Size Теперь Apache для генерации e-tag будет использовать только время последнего изменения и размер файла. Это, к сожалению, приводит нас к другой проблеме использования e-tag, которая тоже актуальна для if-modified-since (хоть и в меньшей степени). Поскольку e-tag зависит от времени последнего изменения, нам необходимо следить за синхронизацией. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
|||||||||