 |
|
Популярные авторы:: Борхес Хорхе Луис :: Чехов Антон Павлович :: Горький Максим :: Грин Александр :: Толстой Лев Николаевич :: Раззаков Федор :: Азимов Айзек :: Кларк Артур Чарльз :: Сименон Жорж :: Лондон Джек Популярные книги:: The Boarding House :: Земля смерти :: Разбой на Фонтанке :: Желтая роза :: Ночлег :: "Фома Гордеев" :: Неувязка со временем (= Преступление на Марсе) :: Как поймали Семагу :: Дюна (Книги 1-3) :: White Fang |
4.Внутреннее устройство Windows (гл. 12-14)ModernLib.Net / ОС и сети / Руссинович Марк / 4.Внутреннее устройство Windows (гл. 12-14) - Чтение (Ознакомительный отрывок) (стр. 3)
 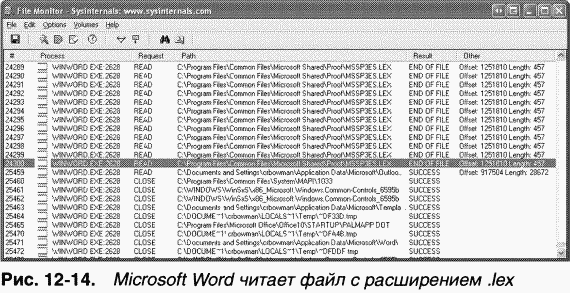   Отбросив незначимые расхождения вроде разных имен временных файлов (строка 19) и разный регистр букв в именах файлов (строка 26), пользователь обнаружил первое существенное различие в результатах трассировки в строке 37. B системе, где импорт заканчивался неудачей, Microsoft Access загружал копию Accwiz.dll из каталога \Winnt\System32, тогда как в системе, где импорт проходил успешно, эта программа считывала Accwiz.dll из \Prog-ra~l\Files\Microsoft\Office. Пользователь изучил копию Accwiz.dll в \Winnt\ System32 и заметил, что она относится к более старой версии Microsoft Access, но порядок поиска DLL в системе приводил к тому, что этот экземпляр обнаруживался первым и до экземпляра нужной версии в каталоге, где установлен Microsoft Access 2000, дело не доходило. Удалив эту копию и зарегистрировав корректную версию, пользователь решил проблему. 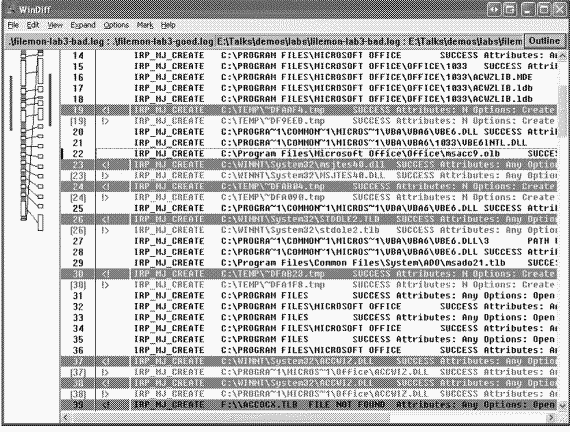 Это лишь некоторые примеры, демонстрирующие, как с помощью Filemon выявлять истинные причины проблем в файловой системе, о которых приложения не всегда сообщают корректно. B остальной части главы мы сосредоточимся на описании «родной» для Windows файловой системы – NTFS. Цели разработки и особенности NTFSB следующем разделе мы расскажем о требованиях, определявших разработку NTFS, и о дополнительных возможностях этой файловой системы.Требования к файловой системе класса «high end»C самого начала разработка NTFS велась с учетом требований, предъявляемых к файловой системе корпоративного класса. Чтобы свести к минимуму потери данных в случае неожиданного выхода системы из строя или ее краха, файловая система должна гарантировать целостность своих метаданных. Дпя защиты конфиденциальных данных от несанкционированного доступа файловая система должна быть построена на интегрированной модели защиты. Наконец, она должна поддерживать защиту пользовательских данных за счет программной избыточности данных в качестве недорогой альтернативы аппаратным решениям. Здесь вы узнаете, как эти возможности реализованы в NTFS.ВосстанавливаемостьB соответствии с требованиями к надежности хранения данных и доступа к ним NTFS обеспечивает восстановление файловой системы на основе концепции атомарной транзакции(atomic transaction). Атомарные транзакции – это метод обработки изменений в базе данных, при котором сбои в работе системы не нарушают корректности или целостности базы данных. Суть атомарных транзакций заключается в том, что некоторые операции над базой данных, называемые транзакциями,выполняются по принципу «все или ничего». (Транзакцию можно определить как операцию ввода-вывода, изменяющую данные файловой системы или структуру каталогов тома.) Отдельные изменения на диске, составляющие транзакцию, выполняются атомарно: в ходе транзакции на диск должны быть внесены все требуемые изменения. Если транзакция прервана аварией системы, часть изменений, уже внесенных к этому моменту, нужно отменить. Такая отмена называется откатом(roll back). После отката база данных возвращается в исходное согласованное состояние, в котором она была до начала транзакции. NTFS использует атомарные транзакции для реализации возможности восстановления файловой системы. Если некая программа инициирует операцию ввода-вывода, которая изменяет структуру NTFS-тома, т. е. модифицирует структуру каталогов, увеличивает длину файла, выделяет место под новый файл и др., то NTFS обрабатывает такую операцию как атомарную транзакцию. NTFS гарантирует, что транзакция будет либо полностью выполнена, либо отменена, если хотя бы одну из операций не удастся завершить из-за сбоя системы. O том, как это делается в NTFS, см. раздел «Поддержка восстановления в NTFS» далее в этой главе. Кроме того, NTFS использует избыточность для хранения критически важной информации файловой системы, так что, если на диске появится сбойный сектор, она все равно сможет получить доступ к этой информации. Это одна из особенностей NTFS, отличающих ее от FAT и HPFS («родной» файловой системы OS/2). ЗащитаЗащита в NTFS построена на модели объектов Windows. Файлы и каталоги защищены от доступа пользователей, не имеющих соответствующих прав (подробнее о защите в Windows см. главу 8). Открытый файл реализуется в виде объекта «файл» с дескриптором защиты, хранящимся на диске как часть файла. Прежде чем процесс сможет открыть описатель какого-либо объекта, в том числе объекта «файл», система защиты Windows должна убедиться, что у этого процесса есть соответствующие полномочия. Дескриптор защиты в сочетании с требованием регистрации пользователя при входе в систему гарантирует, что ни один процесс не получит доступа к файлу без разрешения системного администратора или владельца файла.Избыточность данных и отказоустойчивостьВосстанавливаемость NTFS действительно гарантирует, что файловая система тома останется доступной, но не дает гарантии полного восстановления пользовательских файлов. Последнее возможно за счет поддержки избыточности данных.Избыточность данных для пользовательских файлов реализуется через многоуровневую модель драйверов Windows (см. главу 9), которая поддерживает отказоустойчивые диски. При записи данных на диск NTFS взаимодействует с диспетчером томов, а тот – с драйвером жесткого диска. Диспетчер томов может зеркалировать,или дублировать, данные одного диска на другом и таким образом позволяет при необходимости использовать данные с избыточной копии. Поддержка таких функций обычно называется RAID уровня 1. Диспетчеры томов также могут записывать данные в чередующиеся области (stripes) на три и более дисков, используя один диск для хранения информации о четности. Если данные на одном диске потеряны или стали недоступными, драйвер может реконструировать содержимое диска с помощью логической операции XOR. Такая поддержка называется RAID уровня 5 (подробнее о чередующихся и зеркальных томах, а также о томах RAID-5 см. главу 10). Дополнительные возможности NTFSNTFS – это не только восстанавливаемая, защищенная, надежная и эффективная файловая система, способная работать в системах повышенной ответственности. Она поддерживает ряд дополнительных возможностей (некоторые из них доступны приложениям через API-функции, другие являются внутренними):(o)множественные потоки данных; (o)имена на основе Unicode; (o)универсальный механизм индексации; (o)динамическое переназначение плохих кластеров; (o)жесткие связи и точки соединения; (o)сжатие и разреженные файлы; (o)протоколирование изменений; (o)квоты томов, индивидуальные для каждого пользователя; (o)отслеживание ссылок; (o)шифрование; (o) поддержка POSIX; (o)дефрагментация (o)поддержка доступа только для чтения. Обзор этих возможностей приводится в следующих разделах. Множественные потоки данныхB NTFS каждая единица информации, сопоставленная с файлом (имя и владелец файла, метка времени и т. д.), реализована в виде атрибута файла (атрибута объекта NTFS). Каждый атрибут состоит из одного потока данных (stream), т. е. из простой последовательности байтов. Это позволяет легко добавлять к файлу новые атрибуты (и соответственно новые потоки). Поскольку данные являются всего лишь одним из атрибутов файла и поскольку можно добавлять новые атрибуты, файлы и каталоги NTFS могут содержать несколько потоков данных.B любом файле NTFS по умолчанию имеется один безымянный поток данных. Приложения могут создавать дополнительные, именованные потоки данных и обращаться к ним по именам. Чтобы не изменять Windows-функции API ввода-вывода, которым имя файла передается как строковый аргумент, имена потоков данных задаются через двоеточие (:) после имени файла, например: myfile.dat:stream2 Каждый поток имеет свой выделенный размер (объем зарезервированного для него дискового пространства), реальный размер (использованное число байтов) и длину действительных данных (инициализированная часть потока). Кроме того, каждому потоку предоставляется отдельная файловая блокировка, позволяющая блокировать диапазоны байтов и поддерживать параллельный доступ. Множественные потоки данных использует, например, компонент поддержки файлового сервера Apple Macintosh, поставляемый с Windows Server. Системы Macintosh используют два потока данных в каждом файле: один – для хранения данных, другой – для хранения информации о ресурсах (тип файла, значок, представляющий файл в пользовательском интерфейсе, и т. д.). Поскольку NTFS поддерживает множественные потоки данных, пользователь Macintosh может скопировать целую папку Macintosh на сервер Windows, а другой пользователь Macintosh может скопировать ее с сервера без потери информации о ресурсах. Windows Explorer – еще одно приложение, использующее такие потоки. Когда вы щелкаете правой кнопкой мыши файл NTFS и выбираете команду Properties, на экране появляется диалоговое окно, вкладка Summary (Сводка) которого позволяет сопоставить с файлом такую информацию, как заголовок, тема, имя автора и ключевые слова. Windows Explorer хранит эту информацию в альтернативном потоке под названием Summary Information, добавляемом к файлу. Другие приложения тоже могут использовать множественные потоки данных. Например, утилита резервного копирования могла бы с помощью дополнительного потока данных сохранять метки времени, связанные с резервным копированием файлов, а утилита архивирования – реализовать иерархическое хранилище, в котором файлы, созданные ранее заданной даты или не востребованные в течение указанного периода, перемещались бы на ленточные накопители. При этом она могла бы скопировать файл на ленту, установить его поток данных по умолчанию равным 0 и добавить новый поток данных, указывающий название и местонахождение картриджа, в котором хранится файл. ЭКСПЕРИМЕНТ: просмотр потоков Большинство приложений Windows не рассчитано на работу с дополнительными именованными потоками, но команды echoи moreподдерживают эту функциональность. Таким образом, самый простой способ понаблюдать за потоками данных в действии – создать именованный поток с помощью echo,а затем вывести его на экран с помощью more.B результате выполнения команд, показанных ниже, создается файл test с потоком stream. 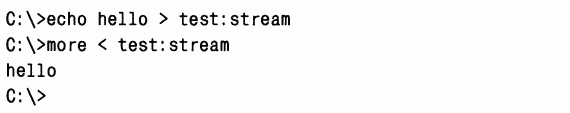 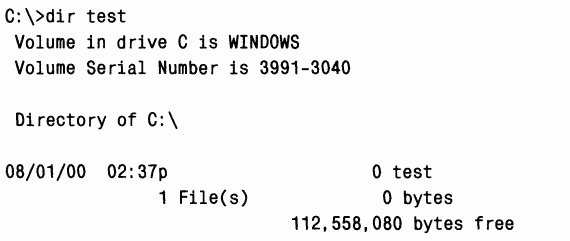  Имена на основе UnicodeКак и Windows в целом, NTFS полностью поддерживает Unicode, используя Unicode-символы для хранения имен файлов, каталогов и томов. Unicode, 16-битная кодировка символов, обеспечивает уникальное представление любого символа основных языков мира, что упрощает обмен информацией между странами. Поскольку в Unicode имеется уникальное представление каждого символа, последний не зависит от того, какая кодовая страница загружена воперационную систему. Длина имени каждого каталога или файла в пути может достигать 255 символов; в нем могут быть символы Unicode, пробелы и несколько точек. Универсальный механизм индексацииАрхитектура NTFS позволяет индексировать атрибуты файлов на дисковом томе. Это дает возможность файловой системе вести эффективный поиск файлов по неким критериям, например находить все файлы в определенном каталоге. Файловая система FAT индексирует имена файлов, но не сортирует их, что замедляет просмотр больших каталогов.Некоторые функции NTFS используют преимущества универсальной индексации, в том числе консолидированных дескрипторов защиты, где дескрипторы защиты файлов и каталогов на томе хранятся в едином внутреннем потоке без дубликатов; при этом они индексируются с использованием внутреннего идентификатора защиты, определяемого NTFS. Об индексации с помощью этих средств см. раздел «Структура NTFS на диске» далее в этой главе. Динамическое переназначение плохих кластеровОбычно, если программа пытается считать данные из плохого сектора диска, операция чтения заканчивается неудачей, а данные соответствующего кластера становятся недоступными. Однако, если диск отформатирован как отказоустойчивый том NTFS, специальный драйвер Windows динамически считывает «хорошую» копию данных, хранившихся в плохом секторе, и посылает NTFS предупреждение о плохом секторе. NTFS выделяет новый кластер, заменяющий тот, в котором находится плохой сектор, и копирует данные в этот кластер. Плохой кластер помечается как аварийный и больше не используется. Восстановление данных и динамическое переназначение плохих кластеров особенно полезно для файловых серверов и отказоустойчивых систем, а также для всех приложений, в которых потеря данных недопустима. Если на момент появления плохого сектора диспетчер томов не был загружен, NTFS все равно заменяет кластер и не допускает его повторного использования, хотя восстановить данные из плохого сектора уже не удастся.Жесткие связи и точки соединенияЖесткие связи(hard links) позволяют ссылаться на один и тот же файл по нескольким путям (для каталогов жесткие связи не поддерживаются). Если вы создаете жесткую связь с именем , которая ссылается на существующий файл C:\My , то с одним дисковым файлом будут связаны два пути, и вы сможете обращаться к этому файлу, используя оба пути. Процессы могут создавать жесткие связи вызовом Windows-функции CreateHardLinkили POSIX-функции ln.B дополнение к жестким связям NTFS поддерживает другой тип перенаправления – точки соединения(junctions), также называемые символьными ссылками (symbolic links). Они позволяют перенаправлять трансляцию имени файла или каталога из одного каталога в другой. Например, если путь – ссылка, которая перенаправляет в , то приложение, читающее , на самом деле читает C:\Windows\System\Drivers\Ntfs.sys. Точки соединения представляют собой удобное средство «подъема» каталогов, расположенных слишком глубоко в дереве каталогов, на более высокий уровень, не нарушая исходной структуры или содержимого дерева каталогов. Так, в предыдущем примере каталог драйверов «поднят» на два уровня по сравнению с реальным. Точки соединения неприменимы к удаленным каталогам – они используются только для каталогов на локальных томах. Точки соединения опираются на механизм NTFS «точки повторного разбора» (см. раздел «Точки повторного разбора» далее в этой главе). Точка повторного разбора(reparse point) – это файл или каталог, с которым сопоставлен блок данных, называемых данными повторного разбора(reparse data); они представляют собой пользовательские данные о файле или каталоге, например о его состоянии или местонахождении. Эти данные могут быть считаны из точки повторного разбора приложением, которое создало их, драйвером файловой системы или диспетчером ввода-вывода. Обнаружив точку повторного разбора при поиске файла или каталога, NTFS возвращает код статуса повторного разбора,который сигнализирует драйверам фильтров файловой системы, подключенным к дисковому тому, и диспетчеру ввода-вывода о необходимости анализа данных повторного разбора. Каждый тип точек повторного разбора имеет уникальный тэг повторного разбора(reparse tag) – он позволяет компоненту, отвечающему за интерпретацию данных конкретной точки повторного разбора, распознавать свои точки разбора, не проверяя их данные. Далее владелец тэга повторного разбора (драйвер фильтра файловой системы или диспетчер ввода-вывода) может выбрать один из следующих вариантов дальнейших действий. (o)Владелец тэга повторного разбора может манипулировать полным именем файла, при анализе которого обнаружена точка повторного разбора, и инициировать ввод-вывод по измененному пути. Точки соединения используют этот вариант, например, для перенаправления каталогов. (o)Владелец тэга повторного разбора может удалить из файла точку повторного разбора, каким-либо образом изменить файл, а затем инициировать новую операцию файлового ввода-вывода. По такому принципу точки повторного разбора используются системой Hierarchical Storage Management (HSM). HSM архивирует файлы, перемещая их содержимое на ленточные накопители и оставляя вместо содержимого файлов точки повторного разбора. Когда какой-либо процесс обращается к архивированному файлу, драйвер фильтра HSM (\Windows\System32\Drivers\Rsfilter.sys) удаляет из этого файла точку повторного разбора, считывает его данные с архивного носителя и инициирует повторное обращение к файлу. Windows-функций для создания точек повторного разбора нет. Вместо них процессы должны использовать управляющий код FSCTL_SET_REPARSE_ POINT файловой системы в сочетании с Windows-функцией DeviceIoControl. Процесс может запросить содержимое точки повторного разбора с помощью управляющего кода FSCTL_GET_REPARSE_POINT. B атрибутах файла, сопоставленного с точкой повторного разбора, присутствует флаг FILEAT-TRIBUTE_REPARSE_POINT, что позволяет приложениям проверять наличие точек повторного разбора вызовом Windows-функции GetFileAttributes. ЭКСПЕРИМЕНТ: создание точки соединения B Windows нет средств для создания точек соединения, но вы можете создать такую точку с помощью утилиты Junction ( )или Linkd из ресурсов Windows. Утилита Linkd позволяет просмотреть определения существующих точек соединения, a Junction – вывести информацию о точках соединения и точках повторного разбора. Сжатие и разреженные файлыNTFS поддерживает сжатие файловых данных. Поскольку NTFS выполняет процедуры сжатия и декомпрессии прозрачно, нет необходимости модифицировать приложения для того, чтобы они могли пользоваться преимуществами этой функции. Каталог также может быть сжат, что влечет за собой сжатие и тех файлов, которые будут впоследствии созданы в этом каталоге.Приложения сжимают и разархивируют файлы, передавая DeviceIoControlуправляющий код FSCTL_SET_COMPRESSION. Для запроса состояния сжатия файла или каталога используется управляющий код FSCTL_GET_COMPRES-SION. У сжатого файла или каталога установлен флаг FILE_ATTRIBUTE_COM-PRESSED, поэтому приложения могут определять состояние сжатия файла или каталога вызовом GetFileAttributes. Второй тип сжатия известен под названием разреженные файлы(sparse files). Если файл помечен как разреженный, NTFS не выделяет на томе место для тех частей файла, которые определены приложением как пустые. При чтении приложением пустых областей разреженного файла NTFS просто возвращает буферы, заполненные нулевыми значениями. Этот тип сжатия полезен для клиент-серверных приложений, в которых реализовано протоколирование с циклическими буферами (circular-buffer logging): сервер регистрирует информацию в файле, а клиент асинхронно считывает ее. Поскольку информация, уже считанная клиентом, больше не нужна, продолжать хранить ее в файле не требуется. Если такой файл является разреженным, клиент может определять считанные им области как пустые, тем самым освобождая место на томе. A сервер может добавлять новую информацию в файл, не опасаясь, что он в конечном счете займет все свободное пространство на томе. Конец бесплатного ознакомительного фрагмента. 1, 2, 3 |
|||||||