 |
|
Популярные авторы:: Горький Максим :: Борхес Хорхе Луис :: Толстой Лев Николаевич :: Азимов Айзек :: Чехов Антон Павлович :: Раззаков Федор :: Грин Александр :: Константинов Андрей Дмитриевич :: Андреев Леонид Николаевич :: Желязны Роджер Популярные книги:: Дюна (Книги 1-3) :: Донкихоты Вселенной :: Боярин :: А вода все течет... :: История одного города :: Пожиратель мух :: Прекрасна жизнь для воскресших :: Алые когти :: Легенда Дремучего леса :: Inri |
Секреты сканирования на ПКModernLib.Net / Программы / Леонтьев Б. К. / Секреты сканирования на ПК - Чтение (стр. 2)
Следует заметить, что пользоваться этими возможностями вам, скорее всего, не придется, так как даже обычная фотокарточка формата 9x12 см в разрешении 4800x4800 dpi превратится в такую массу данных, что ваш компьютер наверняка будет не в состоянии ее обработать. С другой стороны, высокое разрешение необходимо при сканировании оригиналов небольшого размера с дальнейшим их увеличением. Сошли со сцены сканеры, работавшие с 24-битовым цветом, уступив место 30— и 36-битовым моделям. Правда, большинство из числа последних использует такой цветовой режим только для внутренней обработки изображений, тогда как в компьютер передаются лишь 24 двоичных разряда на каждую точку. Кроме этого помните, что даже в этом случае цветопередача существенно улучшается. Глава 15. Как осуществляется сканирование в программе Adobe Photoshop TWAIN Под TWAIN-интерфейсом понимается международный стандарт, который в свое время был принят для единого взаимодействия устройств ввода изображений с той или иной программой, которая «обслуживает» подобные устройство ввода. Понятно, что драйверы сканеров поставляются и поддерживаются их производителями. Иного и быть не может. Но, в случае, если у вас возникли проблемы в процессе процесса сканирования, убедитесь в том, что вы располагаете хотя бы последней версией драйвера TWAIN для вашего сканера. Adobe Photoshop поддерживает стандартный интерфейс TWAIN, что дает возможность использовать для процесса сканирования любые устройства, также поддерживающие этот интерфейс. Для того чтобы подключить сканер, поддерживающий интерфейс TWAIN, ознакомьтесь с прилагающейся к нему инструкцией по установке и настройке модуля TWAIN. Программа Adobe Photoshop поддерживает так называемые стандарты процесса сканирования TWAIN16 и TWAIN32. Но все равно помните, что даже «навороченная» операционная система Windows Me требует исключительно 32-битных модулей TWAIN. Как начать сканирование В процессе использования определенных моделей сканеров программа Adobe Photoshop, как и OCR-приложение ABBYY FineReader, дает возможность полностью контролировать процесс преобразования фотографии или слайда в оцифрованное изображение. К примеру, для процесса сканирования изображений используется команда Импорт из меню Файл. Программа Adobe Photoshop может работать с любым сканером при условии, что для него будет установлен совместимый дополнительный TWAIN модуль. Для того чтобы установить такой модуль, необходимо скопировать в подкаталог PLUGINS соответствующий файл фирмы-производителя сканера. Все модули для сканеров, установленные в подкаталоге PLUGINS, отображаются в подменю Файл к Импорт.  В случае, если вы не смогли приобрести для своего сканера драйвер, совместимый с программой Adobe Photoshop, то вы имеете возможность отсканировать изображение с помощью программного обеспечения фирмы-производителя сканера, сохранив его в формате TIFF или BMP. Для того, чтобы затем открыть этот файл в программе Photoshop, воспользуйтесь командой Открыть… из меню Файл. В процессе процесса сканирования изображений вы имеете возможность управлять несколькими параметрами, которые влияют на качество итогового файла. Прежде чем приступить к сканированию, выполните изложенные в этой главе инструкции по определению разрешения процесса сканирования и оптимального динамического диапазона, а также по разработке процедур, минимизирующих нежелательные цветовые искажения. Определение разрешения процесса сканирования Выбор разрешения при сканировании изображения определяется возможностями выводного устройства. К примеру, если изображение будет отображаться только на экране монитора вашего компьютера, то для него вполне достаточно задать разрешение, равное разрешающей способности экрана. Как правило, для IBM PC-совместимых мониторов оно составляет 96 ppi (пикселов на дюйм), а для мониторов Macintosh — 72 или 120 ppi. В случае, если отсканированное изображение будет иметь слишком низкое разрешение, то при его печати интерпретатор языка PostScript может использовать цветовые значения отдельных пикселов для создания сразу нескольких растровых точек. Это неизбежно приведет к потере качества изображения. В случае, если графическое разрешение изображения окажется слишком велико, то файл будет содержать избыточную информацию, которая не сможет быть использована при печати. От объема файла напрямую зависит время обработки изображения принтером. Объем файла, в свою очередь, прямо пропорционален графическому разрешению изображения. К примеру, объем файла для изображения с разрешением 200 ppi будет в четыре раза превышать объем файла для того же изображения с разрешением 100 ppi. В процессе процесса сканирования изображения для последующего вывода на принтер необходимо помнить относительно того, что разрешение процесса сканирования определяется требуемым качеством печати, а также разрешающей способностью принтера и соотношением размера оригинала и размера сканированного изображения. Разрешение и линиатура растра Линиатура растра это разрешение того растра, который используется при выводе итоговой версии изображения. Как правило, высокое качество при печати полутонового изображения может быть обеспечено в том случае, если его графическое разрешение вдвое превосходит значение линиатуры полутонового растра, которое будет использовано для вывода. Например с тем, чтобы получить высококачественный оттиск при линиатуре 133 lpi, необходимо отсканировать изображение с разрешением примерно 266 ppi. В отдельных случаях (в зависимости от конкретного изображения и от устройства вывода) превосходные результаты могут быть получены и при более низких соотношениях, вплоть до 1.25. В случае, если при печати изображения его разрешение превысит линиатуру более чем в 2.5 раза, то вы получите соответствующее предупреждение. Это означает, что слишком высокое разрешение не может быть корректно воспринято данным принтером и приведет к неоправданному увеличению объема файла и времени печати. С помощью команды Размер изображения задайте более низкое разрешение, при необходимости сохранив копию файла с высоким разрешением. Глава 16. OCR — системы Так называемые системы оптического распознавания символов (Optical Character Recognition — OCR) предназначены для автоматического ввода печатных материалов в компьютер, при этом сам процесс подобного ввода проходит в три этапа: • Сканирование. • Обработка. • Целостное целенаправленное адаптивное распознавание. Глава 17. Сканирование Сканирующее устройство «просматривает» печатный материал и передает его в OCR-систему. Далее печатный материал преобразуется в изображение, которое на данном этапе нельзя отредактировать ни в одном текстовом редакторе. Глава 18. Обработка Затем OCR-система анализирует (определяет блоки распознавания, выделяет в тексте строки и отдельные символы) изображение и начинает распознавать каждый его символ. Целостное целенаправленное адаптивное распознавание Распознавание печатного материала осуществляется на основе так называемой технологии «целостного целенаправленного адаптивного распознавания», которая базируется на трех принципах: • Целостность. • Адаптивность. • Целенаправленность. В соответствии с этими принципами OCR-система сначала выдвигает гипотезу относительно объекта распознавания (символе, части символа или нескольких склеенных символах), а затем подтверждает или опровергает ее, пытаясь последовательно обнаружить все структурные элементы и связывающие их отношения, при этом в каждом структурном элементе можно выделить определенные части, имеющие значение для человеческого восприятия: • отрезки дуги кольца точки. Целостность Распознаваемый объект воспринимается OCR-системой в качестве целого посредством «значимых» элементов и отношений между ними. Целенаправленность Процесс распознавания проходит через выдвижение гипотез и целенаправленной их проверке. Это означает, что OCR-система проводит поиск, учитывает предыдущий контекст и на основе этого распознает даже разорванные и искаженные печатные символы. Адаптивность Под адаптивностью подразумевается способность OCR-системы к самообучению. Следуя этому принципу, OCR-система подстраивается к распознаваемому материалу на базе полученного «положительного» опыта. В итоге в рабочей среде OCR-системы появляется распознанный текст, который можно корректировать и сохранять в том или ином формате. Глава 19. Системы распознавания текстов в офисе Основное назначение пакетов оптического распознавания символов (Optical Character Recognition, OCR) состоит в анализе растровой информации (отсканированного символа) и присвоении точечному изображению символа фиксированного электронного значения. Грубо говоря, OCR-система определяет, какой букве соответствует та или иная картинка. Отечественные разработчики программного обеспечения действительно преуспели в сфере систем распознавания. Между тем проблемы, которые встают перед разработчиками подобных систем, весьма нетривиальны. В зависимости от качества отсканированного изображения приходится разделять склеившиеся символы, домысливать творения матричного принтера, разбивать (фрагментировать) текст на блоки, догадываться о значении не пропечатавшихся символов, настраиваться (через систему обучения) на «почерк» печатающего устройства или пишущей машинки, узнавать широкую гамму шрифтов, начертаний и других параметров символов. Кроме того, современные системы оптического распознавания должны уметь сохранять форматирование исходных документов, присваивать в нужном месте атрибут абзаца, сохранять таблицы, оставлять в покое графику (нераспознаваемые картинки)… И это лишь малая толика всех задач OCR— пакетов. Из не решенных на сегодняшний день проблем остается уверенное распознавание «вольных» рукописных текстов или декоративных шрифтов. По сложности эта задача приближается к речевому распознаванию. Тем не менее Cognitive Forms (Cognitive Technologies) и FineReader 4.0 Forms (ABBYY) уже уверенно распознают машинописные записи в формулярах (анкетах, декларациях и т.д.). Не так давно появились примеры решений для автоматизации форм, вручную заполняемых пользователями в специально отведенных блоках для букв. Отчасти это напоминает строку для индекса на почтовых конвертах (только без пунктиров), однако распознавание при этом заметно сложнее из-за многообразия индивидуальных «граффити», далеких от принципов классической каллиграфии. Этот класс систем — тема для отдельного разговора, так как они достаточно специфичны и сложны. OCR-системы — редкий пример офисных программ, реализующих почти весь потенциал высокопроизводительных процессоров. Скорость распознавания имеет прямую зависимость от архитектуры процессора, тактовой частоты и наличия усиленного блока целочисленных вычислений (мультимедийных расширений). Не случайно на коробках большинства OCR-программ красуется надпись Designed for Intel ММХ. Считается, что расширения Intel для оптимизации целочисленных вычислений позволяют повысить скорость распознавания на треть. Глава 20. Программа ABBYY FineReader С появлением компьютеров человека увлекла идея научить машины мыслить так же, как это делает он сам. Такую гипотетическую возможность компьютеров предаваться размышлениям окрестили «искусственным интеллектом». С тех пор этот термин прочно укоренился в лексике околокомпьютерных кругов. Но теперь под «искусственным интеллектом» стали понимать, пожалуй, не способность машины мыслить аналогично человеку, а, скорее, технологии, которые позволяют решать неформализованные нетривиальные задачи, в которых не существует однозначно определяемого алгоритма решения. При создании программ, способных решать такие задачи, делается попытка смоделировать рассуждения человека в подобных ситуациях, поэтому термин «искусственный интеллект» пришелся здесь весьма кстати, хотя и потерял в некоторой степени свое первоначальное значение. В реальности, большинство «жизненных» задач не имеют четкого алгоритма решения, поэтому трудно поддаются формализации. Особенно хорошо это заметно в области лингвистики и работы с речью, как устной, так и письменной. Такова, например, проблема машинного перевода. Не раз, наверно, приходилось улыбаться, глядя на результаты работы программы-переводчика. Действительно, нелегко создать программу, которая могла бы сделать осмысленный перевод с учетом всех тонкостей и особенностей живого языка. Не менее сложна и задача распознавания изображений, в частности текстов. Заманчиво заставить машину понять, что за текст мы предлагаем ее вниманию. При всей сложности этой задачи, сегодня в этом направлении достигнуты хорошие результаты. Первые шаги в этой области были предприняты еще в конце 50-х годов. Принципы распознавания, заложенные тогда, и сегодня еще используются в большинстве систем OCR (Optical Character Recognition). Традиционный подход к проблеме распознавания заключается в сведении задачи распознавания к задаче классификации некоторого набора признаков. Идея проста: по изображению определяется некоторый набор признаков, который сравнивается с каждым из имеющихся образцов, так называемых эталонов. По результатам сравнения находится эталон, с которым этот набор признаков совпадает лучше всего, и изображение относится к соответствующему классу. То есть все решение заключается в сравнении предлагаемого изображения с образцами и выборе наиболее подходящего, иначе говоря, производится некий перебор возможных вариантов. Такой подход по сути своей не позволяет добиться по-настоящему высокого качества распознавания, как бы он не был усовершенствован. Главный его недостаток заключается в том, что в любом случае в наборе признаков содержится не вся информация об изображении, иными словами, эталонов заложить в программу можно много, но не бесконечное число, а вот вариантов изображения того или иного символа может быть бесчисленное количество. Поэтому, как только система сталкивается с нестандартным написанием буквы или цифры, она дает сбой: либо не может распознать вообще, либо распознает неправильно. Альтернативой традиционному шаблонному методу распознавания стало распознавание на основе принципов Целостности, Целенаправленности и Адаптивности. Согласно принципу целостности, распознаваемый объект рассматривается как целое, состоящее из частей, связанных между собой пространственными отношениями. Изображение интерпретируется как определенный объект, только если на нем присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Сами части получают интерпретацию только в составе гипотезы о предполагаемом объекте. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез о целом объекте. Источниками гипотез являются признаковые классификаторы и контекстная информация. Части картинки анализируются не априорно, а только в рамках выдвинутой гипотезы о целом. Традиционный подход, состоящий в интерпретации того, что наблюдается на изображении, заменяется подходом, состоящим в целенаправленном поиске того, что ожидается на изображении. Принцип адаптивности подразумевает способность системы к самообучению. Впервые эти принципы были применены на практике в системе распознавания «Графит», которая была разработана под руководством Александра Шамиса в конце 80-х годов. Это была система распознавания рукопечатных знаков. На этих же принципах в 1993 году фирмой Bit Software (ныне компания ABBYY) была создана система распознавания печатного текста FineReader. В своей работе эта система использовала признаковый классификатор в сочетании с целенаправленной проверкой гипотез о распознаваемых словах по словарю. Признаковый классификатор использует некоторое количество признаков, которые вычисляются по изображению. Типичная процедура классификации состоит в вычислении степени близости между входным изображением и известными системе классами изображений. В качестве ответа выдается список классов, упорядоченный по степени близости, то есть фактически выдвигался ряд гипотез о принадлежности объекта тому или иному классу. Как строится процесс распознавания символов в FineReader? Для быстрого порождения предварительного списка гипотез используются, как и ранее, признаковые классификаторы. Эти же классификаторы используются для повышения точности распознавания на изображениях с дефектами. Путем их комбинации выдвигаем гипотезу о том, что может быть на изображении. Каждый классификатор дает не один результат, а несколько лучших, которые объединяются в общий список. Получаем некий набор гипотез о том, что может быть на изображении. Далее гипотезы последовательно проверяются структурным классификатором, который целенаправленно анализирует имеющийся символ, исходя из знаний о его структуре. То есть, когда мы предполагаем, что на изображении может быть буква "а", мы можем целенаправленно проверить те свойства, которые должны быть именно у буквы "а", а не у какой-то другой буквы, сравнивая имеющийся у нас символ со структурным эталоном. Структурный эталон описывает знак как набор структурных элементов, находящихся в определенных отношениях между собой. Используется четыре типа структурных элементов: отрезок, дуга, кольцо, точка. Отношения задаются как нечеткие логические высказывания. В качестве переменных используются различные атрибуты элементов — длины, описывающие рамки, углы, координаты характерных точек элементов. Большинство отношений сводится к проверке того, что некоторая величина принадлежит диапазону с нечеткими границами. В результате проверки отношения получается оценка в диапазоне [0..1]. Оценки всех отношений перемножаются, что соответствует нечеткой логической операции AND. Отношения проверяются сразу же после выделения всех использованных в этом отношении элементов. Если какое-то отношение не выполняется, проверка текущей ветви перебора останавливается. Это ограничивает перебор на ранних стадиях и позволяет избежать комбинаторного взрыва. Итак, структурный эталон представляет символ в виде набора некоторых структурных элементов. Очевидно, что процесс распознавания должен включать в себя этапы выделения структурных элементов на изображении и сопоставления найденных элементов с эталонами. Видимое решение состоит в том, чтобы делать эти этапы последовательно: сначала выделить элементы, а потом сопоставить их с эталонами. Однако такой порядок действий имеет очень серьезный недостаток. Проблема заключается в том, что априорное выделение элементов неоднозначно. Даже человеку для того, чтобы правильно выделить элементы, недостаточно видеть только часть картинки. Он должен увидеть всю картинку целиком и выдвинуть гипотезу о том, что изображено на всей картинке. Эта гипотеза позволяет снять все неоднозначности — правильно соединить разорванные элементы и мысленно исправить все искажения. Решение проблемы неоднозначности заключается в том, чтобы не выделять структурные элементы априорно. Вместо этого они должны выделяться прямо в процессе сопоставления эталона с изображением. Наличие гипотезы о предполагаемом содержимом всей картинки позволяет использовать априорные знания об устройстве знака: типах элементов, их относительном положении, допустимых значениях атрибутов. Это позволяет уверенно выделять структурные элементы даже на разорванных и искаженных изображениях. Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью структурных дифференциальных классификаторов. Так, например, если при распознавании символа возникла ситуация, когда структурный классификатор не может однозначно выбрать из двух букв с похожим написанием, то между этими конкурирующими гипотезами делают дифференциальный выбор. В целом этот процесс похож на процесс постановки больному диагноза. В медицине существует понятие дифференциального диагноза. Когда по внешним симптомам поставить диагноз невозможно, приходится проводить более тщательные исследования, вплоть до диагностической операции, чтобы выявить дополнительные симптомы, четко определяющие болезнь. Так и в процессе распознавания. Например, программа не может уверенно распознать символ. Есть две гипотезы: "l" (латинская "л") и "1" (единица). Чтобы выбрать между этими двумя гипотезами, мы должны целенаправленно проанализировать левый верхний угол изображения, где помещается та единственная деталь, по которой мы можем отличить один символ от другого. Только так возможно будет сделать окончательный вывод о том, какая гипотеза правильна. Причем тщательно исследовать эту единственную деталь мы будем только после того, как у нас останется всего две гипотезы. В этом и заключается целенаправленность предлагаемого подхода. Ибо, если мы решим с самого начала проверять все имеющиеся изображения на наличие огромного количества мелких деталей (ведь пар похожих символов достаточно много, и в каждом конкретном случае деталь, по которой их можно различить, будет меняться), то, во-первых, резко снизится скорость распознавания, а во-вторых, информация об этих мелких деталях будет «засорять» процесс распознавания и помешает опознать буквы, для которых те или иные детали не имеют значения. То есть система станет более восприимчива к помехам. После того, как работа дифференциального классификатора завершена, мы можем сказать, что непосредственно само распознавание закончено. У нас остается окончательный список гипотез, подлежащий проверке. Окончательная верификация результата распознавания осуществляется системой контекста. Система контекстной проверки позволяет резко улучшить качество распознавания текстов плохого качества за счет того, что при наличии некоторого количества распознанных букв из слова компьютер может «догадаться», что это за слово, используя словарь. В FineReader удалось без больших потерь в скорости увеличить число рассматриваемых гипотез при анализе контекста, что, в свою очередь, также в лучшую сторону сказывается на точности распознавания текстов очень низкого качества. В FineReader анализ документа проводится как до, так и после непосредственно распознавания, что позволяет гораздо лучше сохранять внешний вид документа при его экспорте в другие приложения из FineReader. В результате использования совмещенной процедуры значительно улучшилось выделение таблиц и отделение текста от графики. Фактически, основная задача разработчиков FineReader — сделать так, чтобы пользователь получил на выходе документ, полностью совпадающий как по содержанию, так и по внешнему оформлению с документом, который он недавно положил в сканер. На сегодняшний день система FineReader демонстрирует непревзойденную точность распознавания и высокое качество анализа документа и сохранения его оформления. От версии к версии она совершенствуется, используются новые алгоритмы, появляются новые возможности. Но принципы Целостности, Целенаправленности и Адаптивности остаются неизменными, так как именно эти принципы позволяют машине приблизится к логике мышления, свойственной человеку, и в дальнейшем решать, возможно, гораздо более сложные задачи, чем задача распознавания. Глава 21. Омнифонтовая OCR-система Программа FineReader является так называемой омнифонтовой системой оптического распознавания текстов. Подобные системы дают возможность распознавать печатные тексты, набранные шрифтами с различными гарнитурами. Основные возможности Программа FineReader: • Дает возможность ввести документ в компьютер посредством нажатия всего на одну кнопку. • Имеется возможность экспортировать распознанный текст в текстовый редактор или электронную таблицу, а также сохранить его в формате PDF или HTML. • Имеется возможность сохранять цвета распознанного текста в форматах RTF, PDF и HTML. • Встроенная технология «адаптивного распознавания»: Необычайно высокая точность распознанных текстов и малая чувствительность к дефектам печати. • Распознанные страницы представляются миниатюрными изображениями. • Имеется возможность сканировать разворот книги и распознавать ее каждую страницу по отдельности, при этом, изображение, содержащее сдвоенные страницы, сохраняется в две различные страницы пакета. • Встроенный алгоритм автоматического поиска блоков (участков изображения, выделенных в рамку) распознаваемого текста: Анализ отсканированного материала и его распознавание происходит одновременно. • Программа «видит» изображения в распознаваемом макете. • 176 языков распознавания. • Распознавание языков программирования (Basic, Cobol, Fortran, Java, C++, Pascal). • Распознавание подстрочных символов и вертикального текста. • Поддержка кодировки Unicode при сохранении распознанного текста в форматах RTF, DOC, XLS, HTML, TXT и CSV. Форматы текстовых файлов, которые поддерживает программа FineReader может экспортировать распознанный материал в одном из следующих форматов: • Microsoft Word Document (*.DOC). • Rich Text Format (*.RTF). • Adobe Acrobat Format (*.PDF) • HTML. • Comma Separated Values File (*.CSV). • Простой текст (*.TXT). • Microsoft Excel Speadsheet (*.XLS). • DBF. Форматы графических файлов, которые поддерживает программа FineReader позволяет импортировать в свою систему файлы следующих форматов: • TIFF. • BMP. • JPEG. • PCX • DCX. • PNG. Для работы с русскоязычной версией программы операционная система Microsoft Windows должна поддерживать русскоязычную раскладку клавиатуры (доступ в Microsoft Windows Me Millennium Edition: Панель управления к Язык и стандарты к Региональные стандарты к Язык к Русский к Страна/Регион к Россия). Глава 22. Установка программы Перед установкой программы выйдите из работающих приложений вашей операционной системы. В случае, если ваша операционная система настроена на автоматический запуск приложений из устройств чтения компакт-дисков (доступ в Microsoft Windows: Пуск к Настройка к Панель управления Система к Устройства к Устройство для чтения компакт-дисков к Пастройка к Автоматическое распознавание дисков), то после того, как фирменный компакт-диск с программой будет вставлен в соответствующее устройство, вы практически сразу же увидите на экране вашего монитора диалоговое окно ABBYY Software House Setup. 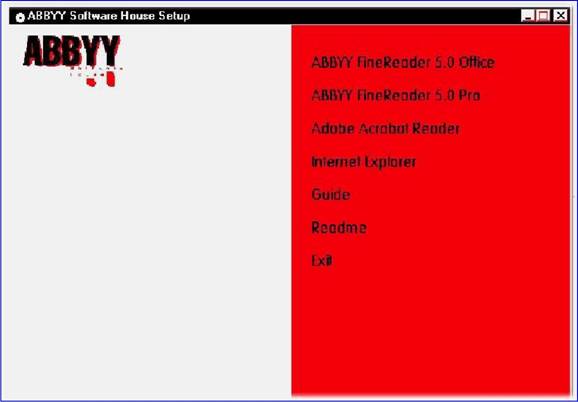 Закройте диалоговое окно ABBYY Software House Setup, вставьте в соответствующее устройство фирменную флоппи-дискету, посредством двойного щелчка левой кнопкой мыши запустите файл Install. exe (он находится в главной директории диска) и через некоторое время обратитесь к Мастеру установки программы FineReader. 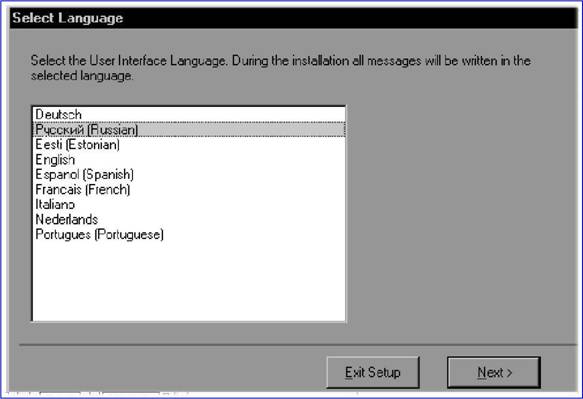 В первом диалоговом окне Мастера установки выберите язык пользовательского интерфейса (набор команд меню и инструментов программы finereader). Для продолжения установки нажмите на кнопку Next (Далее), согласитесь с условиями лицензионного соглашения (нажмите на кнопку Согласен) и обратитесь к диалогу Введите информацию о себе, в котором определитесь с именем пользователя и названием вашей организации, а в поле данных Серийный номер впишите серийный номер, который должен присутствовать на последней обложке «Руководства пользователя FineReader». 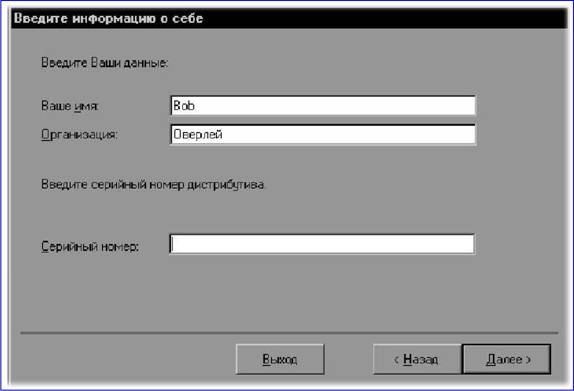 Программа FineReader предоставляется вам в защищенном от копирования виде. Это связано с тем, чтобы предотвратить возможность ее незаконного тиражирования. Для продолжения установки снова нажмите на кнопку Далее. На экране вашего монитора отобразится запрос относительно подтверждения введенной информации. Теперь просто нажмите на кнопку Далее для продолжения установки или на кнопку Назад — для корректировки «регистрационной» информации. 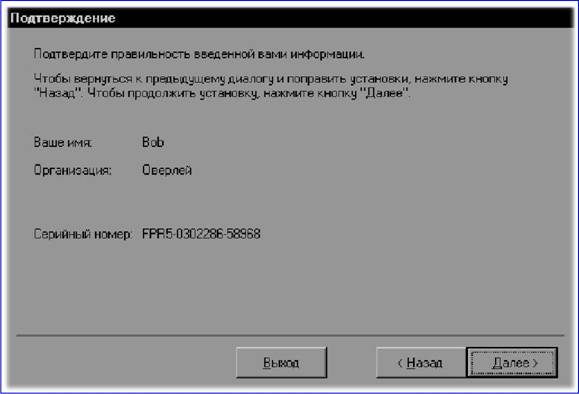 После нажатия на кнопку Далее отобразится диалоговое окно Выберите способ установки. 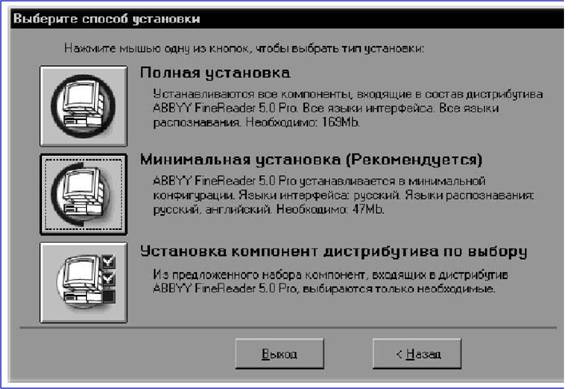 Полная Устанавливаются все компоненты программы, в том числе все языки распознавания. Нажав на кнопку Полная, установщик предложит вам выбрать папку на жестком диске, в которой будут находиться файлы программы. Вы имеете возможность использовать имя папки по умолчанию или через на кнопку Обзор выбрать ее другое имя. Если папка для установки вообще отсутствует, то на экране отобразится запрос относительно необходимости формирования новой папки. Нажав на кнопку Далее, вы подтверждаете ее создание. Выборочная Из предложенного набора компонент, входящих в ваш дистрибутив, имеется возможность выбрать только те, которые необходимы пользователю. 0Щемонстрационные файлы 0Руководство 0Изображения для обучения 0Программная оболочка 0Установка дополнительным возможностей 0Языки распознавания 0Языки интерфейса ABBYY FineReader Минимальная Программа устанавливается в минимальной конфигурации: • Язык интерфейса (один) — выбранный при установке. • Языки распознавания — английский плюс выбранный язык при установке. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
|||||||