Самоучитель - Самоучитель UML
ModernLib.Net / Программирование / Леоненков Александр / Самоучитель UML - Чтение
(Ознакомительный отрывок)
(Весь текст)
Александр Леоненков
Самоучитель UML
ГЛАВА 1 Введение
Если попытаться охарактеризовать современный уровень развития компьютерных и информационных технологий, то первое, на что следует обратить внимание – это возрастающая сложность не только отдельных физических и программных компонентов, но и лежащих в основе этих технологий концепций и идей. Кажется, еще совсем недавно профессиональному программисту было достаточно в совершенстве владеть одним-двумя языками программирования, чтобы разрабатывать серьезные программные приложения. Выбор платформы и операционной системы, как правило, не являлся серьезной проблемой. А сопровождение программы, хотя и было сопряжено с объективными трудностями, могло быть реализовано простым добавлением или изменением кода исходной программы.
1.1. Методология процедурно-ориентированного программирования
Появление первых электронных вычислительных машин или компьютеров ознаменовало новый этап в развитии техники вычислений. Казалось, достаточно разработать последовательность элементарных действий, каждое из которых преобразовать в понятные компьютеру инструкции, и любая вычислительная задача может быть решена. Эта идея оказалась настолько жизнеспособной, что долгое время доминировала над всем процессом разработки программ. Появились специальные языки программирования, которые позволили преобразовывать отдельные вычислительные операции в соответствующий программный код. Основой данной методологии разработки программ являлась процедурная или алгоритмическая организация структуры программного кода. Это было настолько естественно для решения вычислительных задач, что ни у кого не вызывала сомнений целесообразность такого подхода. Исходным понятием этой методологии являлось понятие алгоритма, под которым, в общем случае, понимается некоторое предписание выполнить точно определенную последовательность действий, направленных на достижение заданной цели или решение поставленной задачи. Примерами алгоритмов являются хорошо известные правила нахождения корней квадратного уравнения или корней линейной системы уравнений.
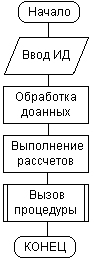
С этой точки зрения вся история математики тесно связана с разработкой тех или иных алгоритмов решения актуальных для своей эпохи задач. Более того, само понятие алгоритма стало предметом соответствующей теории – теории алгоритмов, которая занимается изучением общих свойств алгоритмов. Со временем содержание этой теории стало настолько абстрактным, что соответствующие результаты понимали только специалисты. Как дань этой традиции какой-то период времени языки программирования назывались алгоритмическими, а первое графическое средство документирования программ получило название блок-схемы алгоритма. Соответствующая система графических обозначений была зафиксирована в ГОСТ 19.701-90, который регламентировал использование условных обозначений в схемах алгоритмов, программ, данных и систем. Однако потребности практики не всегда требовали установления вычислимости конкретных функций или разрешимости отдельных задач. В языках программирования возникло и закрепилось новое понятие процедуры, которое конкретизировало общее понятие алгоритма применительно к решению задач на компьютерах. Так же, как и алгоритм, процедура представляет собой законченную последовательность действий или операций, направленных на решение отдельной задачи. В языках программирования появилась специальная синтаксическая конструкция, которая получила название процедуры. Со временем разработка больших программ превратилась в серьезную проблему и потребовала их разбиения на более мелкие фрагменты. Основой для такого разбиения как раз и стала процедурная декомпозиция, при которой отдельные части программы или модули представляли собой совокупность процедур для решения некоторой совокупности задач. Главная особенность процедурного программирования заключается в том, что программа' всегда имеет начало во времени или начальную процедуру (начальный блок) и окончание (конечный блок). При этом вся программа может быть представлена визуально в виде направленной последовательности графических примитивов или блоков (рис. 1.1). Важным свойством таких программ является необходимость завершения всех действий предшествующей процедуры для начала действий последующей процедуры. Изменение порядка выполнения этих действий даже в пределах одной процедуры потребовало включения в языки программирования специальных условных операторов типа if-then-eise и Goto для реализации ветвления вычислительного процесса в зависимости от промежуточных результатов решения задачи.
Рис. 1.1.Графическое представление программы в виде последовательности процедур
Рассмотренные идеи способствовали становлению некоторой системы взглядов на процесс разработки программ и написания программных кодов, которая Получила название методологии структурного программирования. Основой данной методологии является процедурная декомпозиция программной системы и организация отдельных модулей в виде совокупности выполняемых процедур. В рамках данной методологии получило развитие нисходящее проектирование программ или программирование «сверху-вниз». Период наибольшей популярности идей структурного программирования приходится на конец 70-х-начало 80-х годов. Как вспомогательное средство структуризации программного кода было рекомендовано использование отступов в начале каждой строки, которые должны выделять вложенные циклы и условные операторы. Все это призвано способствовать пониманию или читабельности самой программы. Данное правило со временем было реализовано в современных инструментариях разработки программ. Ниже приводится пример листинга программы на языке Pascal, который иллюстрирует эту особенность написания программ.
Листинг 1.1. Пример фрагмента программы на Pascal, разработанной с использованием правил структурного программирования
Procedure FirstOpt;
Begin
FuncRaz(Free, Rn);
for i:=l to N do
RvarRec[i]:= Rn[i];
FvarRec:= Freс;
Numlt:=0;
Repeat
NumIt:=NumIt+l;
V:= Freс;
for j:=1 to К do
for 1:=1 to M do
begin
S:=0.0;
T:=0.0;
for i:=l to N do
begin
T:=T+sqr(Wl[i,j])*Xpr[i,l];
S:=S+sqr(Wl[i,j])
end;
Zentr[j,l]:=T/S
end;
for j:=1 to К do
for i:=l to N do
begin
S:=0.0;
P:=0.0;
Q:=0.0;
for l:=1 to M do
S:=S+sqr(Xpr[i,l]-Zentr[j,l]);
P:=1.0/S;
end;
Q:=0.0;
D:=0;
for i:=1 to N do
for j:=1 to К do
if Abs(Wl[i,j]-W2[i,j]) >= Eps then D:=l;
for i:=l to N do
for j:=1 to К do
W1[i,j]:=W2[i,j]
Until (D=0)or(NumIt=NumMax)
End;
В этот период основным показателем сложности разработки программ считали ее размер. Вполне серьезно обсуждались такие оценки сложности программ, как количество строк программного кода. Правда, при этом делались некоторые предположения относительно синтаксиса самих строк, которые должны были удовлетворять определенным правилам. Общая трудоемкость разработки программ оценивалась специальной единицей измерения – «человеко-месяц» или «человеко-год». А профессионализм программиста напрямую связывался с количеством строк программного кода, который он мог написать и отладить в течение, скажем, месяца.
1.2. Методология объектно-ориентированного программирования
Со временем ситуация стала существенно изменяться. Оказалось, что трудоемкость разработки программных приложений на начальных этапах программирования оценивалась значительно ниже реально затрачиваемых усилий, что служило причиной дополнительных расходов и затягивания окончательных сроков готовности программ. В процессе разработки приложений изменялись функциональные требования заказчика, что еще более отдаляло момент окончания работы программистов. Увеличение размеров программ приводило к необходимости привлечения большего числа программистов, что, в свою очередь, потребовало дополнительных ресурсов для организации их согласованной работы. Но не менее важными оказались качественные изменения, связанные со смещением акцента использования компьютеров. Если в эпоху «больших машин» основными потребителями программного обеспечения были крупные предприятия, компании и учреждения, то позже появились персональные компьютеры и стали повсеместным атрибутом мелкого и среднего бизнеса. Вычислительные и расчетно-алгоритмические задачи в этой области традиционно занимали второстепенное место, а на первый план выступили задачи обработки и манипулирования данными. Стало очевидным, что традиционные методы процедурного программирования не способны справиться ни с растущей сложностью программ и их разработки, ни с необходимостью повышения их надежности. Во второй половине 80-х годов возникла настоятельная потребность в новой методологии программирования, которая была бы способна решить весь этот комплекс проблем. Такой методологией стало объектно-ориентированное программирование (ООП). Фундаментальными понятиями ООП являются понятия класса и объекта. При этом под классом понимают некоторую абстракцию совокупности объектов, которые имеют общий набор свойств и обладают одинаковым поведением. Каждый объект в этом случае рассматривается как экземпляр соответствующего класса. Объекты, которые не имеют полностью одинаковых свойств или не обладают одинаковым поведением, по определению, не могут быть отнесены к одному классу.
Важной особенностью классов является возможность их организации в виде некоторой иерархической структуры, которая по внешнему виду напоминает схему классификации понятий формальной логики. В этой связи следует заметить, что каждое понятие в логике имеет некоторый объем и содержание. При этом под объемом понятия понимают все другие мыслимые понятия, для которых исходное понятие может служить определяющей категорией или главной частью. Содержание понятия составляет совокупность всех его признаков или атрибутов, отличающих данное понятие от всех других. В формальной логике имеет место закон обратного отношения: если содержание понятия А содержится в содержании понятия В, то объем понятия В содержится в объеме понятия А. Иерархия понятий строится следующим образом. В качестве наиболее общего понятия или категории берется понятие, имеющее наибольший объем и, соответственно, наименьшее содержание. Это самый высокий уровень абстракции для данной иерархии. Затем данное общее понятие некоторым образом конкретизируется, тем самым уменьшается его объем и увеличивается содержание. Появляется менее общее понятие, которое на схеме иерархии будет расположено на уровень ниже исходного понятия. Этот процесс конкретизации понятий может быть продолжен до тех пор, пока на самом нижнем уровне не будет получено понятие, дальнейшая конкретизация которого в данном контексте либо невозможна, либо нецелесообразна. Примерами наиболее общих понятий могут служить такие абстрактные категории, как система, структура, интеллект, информация, сущность, связь, состояние, событие и многие другие. В процессе изучения этих категорий появляются новые особенности их содержания и объема. Именно по этим причинам всегда трудно дать им точное определение. В качестве примеров конкретных понятий можно привести понятие книги, которую читатель держит в руках, или понятие микропроцессора Intel Pentium П-300.
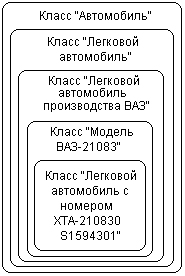
Основными принципами ООП являются наследование, инкапсуляция и полиморфизм. Принцип, в соответствии с которым знание о более общей категории разрешается применять для более узкой категории, называется наследованием. Наследование тесно связано с иерархией классов, которая определяет, какие классы следует считать наиболее абстрактными и общими по отношению к другим классам. При этом, если некоторый более общий или родительский класс (предок) обладает фиксированным набором свойств и поведением, то производный от него класс (потомок) должен содержать этот же набор свойств и поведение, а также дополнительные, которые будут характеризовать уникальность полученного таким образом класса. В этом случае говорят, что производный класс наследует свойства и поведение родительского класса. Для иллюстрации принципа наследования можно привести следующий пример. Рассмотрим в качестве общего класс «Автомобиль». Данный класс определяется как некоторая абстракция свойств и поведения всех реально существующих автомобилей. При этом свойствами класса «Автомобиль» могут быть такие общие свойства, как наличие двигателя, трансмиссии, колес, рулевого управления. Если в качестве производного класса рассмотреть класс «Легковой автомобиль», то все выделенные выше свойства будут присущи и этому классу. Можно сказать, что класс «Легковой автомобиль» наследует свойства родительского класса «Автомобиль». Однако, кроме перечисленных свойств, класс-потомок будет содержать дополнительные свойства, например такое, как наличие салона с количеством посадочных мест 2-5. В свою очередь, класс «Легковой автомобиль» способен порождать другие подклассы, которые вполне могут соответствовать, например, моделям конкретных фирм-производителей. Таким образом, можно рассматривать класс «Легковой автомобиль производства ВАЗ». Поскольку Волжский автомобильный завод выпускает несколько моделей автомобилей, одним из производных классов для предыдущего класса может быть конкретная модель автомобиля, например, ВАЗ-21083. Наконец, изготовленный автомобиль имеет уникальный заводской номер, отличающий один автомобиль от другого. Таким номером может быть, например, XTA-210830S1594301. В последнем случае класс будет состоять из единственного объекта или экземпляра, которым будет являться легковой автомобиль производства ВАЗ с указанным выше заводским номером. Описанная выше информация о соотношении классов в нашем примере обладает одним серьезным недостатком, а именно отсутствием наглядности. В этой связи возникает вопрос: а возможно ли представить иерархию наследования классов в визуальной форме? Традиционно для изображения понятий в формальной логике использовались окружности или прямоугольники. Тогда для рассмотренного примера иерархия порождения классов может быть представлена в виде вложенных прямоугольников, каждый из которых соответствует отдельному классу (рис. 1.2).
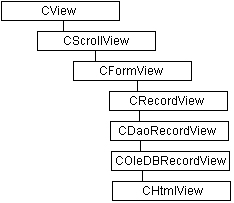
Рис. 1.2.Иерархия вложенности классов для примера «Автомобиль» Появление объектно-ориентированных языков программирования было связано с необходимостью реализации концепции классов и объектов на синтаксическом уровне. С точки зрения ООП класс является дальнейшим расширением структуры (structure) или записи (record). Включение в известные языки программирования С и Pascal классов и некоторых других возможностей привело к появлению соответственно C++ и Object Pascal, которые на сегодня являются наиболее распространенными языками разработки приложений. Распространению C++ и Object Pascal способствовало то обстоятельство, что язык C++ был выбран в качестве базового для программного инструментария MS Visual C++, а язык Object Pascal– для популярного средства быстрой разработки приложений Borland/Inprise Delphi. За короткий период времени оба инструментария превратились в мощные системы разработки программ с соответствующими библиотеками стандартных классов, содержащих сотни различных свойств и методов. Применительно к среде MS Visual C++ 5/6 такая библиотека имеет специальное название – MFC (Microsoft Foundation Classes), т. е. фундаментальные классы от Microsoft. При этом производные классы наследуют свойства и методы родительских классов. Ниже приводится фрагмент иерархии классов MFC в том виде, как он изображен в соответствующей документации (рис. 1.3).
Рис. 1.3.Фрагмент иерархии классов MFC, используемых в среде программирования MS Visual C++ 5/6
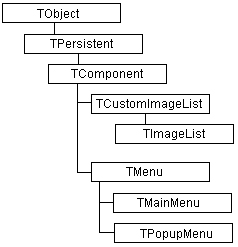
Рис. 1.4.Фрагмент иерархии классов VCU используемых в среде программирования Borland/Inprise Delphi 3-4 Процесс разработки программ в среде Borland/Inprise Delphi также тесно связан с использованием библиотеки стандартных классов – VCL (Visual Component Library) или библиотеки визуальных компонентов. Эта библиотека тоже построена по иерархическому принципу, в соответствии с которым компоненты нижележащих уровней наследуют свойства и методы вышележащих компонентов. Для данного случая также приводится фрагмент иерархии классов VCL (рис. 1.4). Даже этих простых примеров достаточно, чтобы понять следующий факт. А именно, для одной и той же общей концепции иерархии классов используются совершенно различные графические средства. В первом случае – вложенные прямоугольники, во втором – связные прямоугольники. В действительности различных способов изображения классов предложено гораздо больше, небольшая часть из них будет рассмотрена ниже. Однако уже сейчас важно осознать, что подобную ситуацию следовало бы унифицировать, т. е. использовать для этой цели некоторую единую систему обозначений. Следующий принцип ООП – инкапсуляция. Этот термин характеризует сокрытие отдельных деталей внутреннего устройства классов от внешних по отношению к нему объектов или пользователей. Действительно, взаимодействующему с классом субъекту или клиенту нет необходимости знать, каким образом реализован тот или иной метод класса, услугами которого он решил воспользоваться. Конкретная реализация присущих классу свойств и методов, которые определяют поведение этого класса, является собственным делом данного класса. Более того, отдельные свойства и методы класса вообще могут быть невидимы за пределами этого класса, что является базовой идеей введения различных категорий видимости для компонентов класса. Если продолжить рассмотрение примера с классом «Легковой автомобиль», то нетрудно проиллюстрировать инкапсуляцию следующим образом. Основным субъектом, который взаимодействует с этим классом, является водитель. Вполне очевидно, что не каждый водитель в совершенстве знает внутреннее устройство легкового автомобиля. Более того, отдельные детали этого устройства сознательно скрыты в корпусе двигателя или в коробке передач. А в случае нарушения работы автомобиля, являющейся причиной неадекватности его поведения, необходимый ремонт выполняет профессиональный механик. Инкапсуляция ведет свое происхождение от деления модулей в некоторых языках программирования на две части или секции: интерфейс и реализацию. При этом в интерфейсной секции модуля описываются все объявления функций и процедур, а возможно и типов данных, доступных за пределами данного модуля. Другими словами, указанные процедуры и функции являются способами оказания услуг внешним клиентам. В другой секции модуля, называемой реализацией, содержится программный код, который определяет конкретные способы реализаций объявленных в интерфейсной части процедур и функций. Принцип разделения модуля на интерфейс и реализацию отражает суть наших представлений об окружающем мире. В интерфейсной части указывается вся информация, необходимая для взаимодействия с любыми другими объектами. Реализация скрывает или маскирует от других объектов все детали, не имеющие отношения к процессу взаимодействия объектов (рис. 1.5).
Рис. 1.5.Иллюстрация сокрытия внутренних деталей реализации методов классов
Третьим принципом ООП является полиморфизм. Под полиморфизмом (греч. Poly– много, morfos – форма) понимают свойство некоторых объектов принимать различные внешние формы в зависимости от обстоятельств. Применительно к ООП полиморфизм означает, что действия, выполняемые одноименными методами, могут отличаться в зависимости от того, какому из классов относится тот или иной метод. Рассмотрим, например, три объекта или класса: двигатель автомобиля, электрический свет в комнате и персональный компьютер. Для каждого из них можно определить операцию «выключить». Однако сущность этой операции будет отличаться для каждого из рассмотренных объектов. Так для двигателя автомобиля вызов метода двигатеяь_автомобиля. выключить о означает прекращение подачи топлива и его остановку. Вызов метода Комната. электрический_ свет. выключить о означает простой щелчок выключателя, после чего комната погрузится в темноту. В последнем случае действие персональный_ компьютер. выключить о может быть причиной потери данных, если выполняется нерегламентированным образом.
В нашем примере для операции
выключить ()можно определить такие дополнительные параметры, как время выключения, некоторое условие нахождения объекта в предварительно включенном состоянии и пр. Для этого после имени операции указываются скобки, в которых могут быть указаны эти дополнительные параметры или аргументы. В случае отсутствия аргументов считается, что список параметров пуст. Однако скобки все равно записываются и указывают на тот факт, что соответствующее имя является именем операции или метода, в отличие от свойств или атрибутов класса, которые записываются без скобок. Полиморфизм объектно-ориентированных языков связан с перегрузкой функций, но не тождествен ей. Важно иметь в виду, что имена методов и свойств тесно связаны с классами, в которых они описаны. Это обстоятельство обеспечивает определенную надежность работы программы, поскольку исключает случайное применение метода для решения несвойственной ему задачи. Широкое распространение методологии ООП оказало влияние на процесс разработки программ. В частности, процедурно-ориентированная декомпозиция программ уступила место объектно-ориентированной декомпозиции, при которой отдельными структурными единицами программы стали являться не процедуры и функции, а классы и объекты с соответствующими свойствами и методами. Как следствие, программа перестала быть последовательностью предопределенных на этапе кодирования действий, а стала событийно-управляемой. Последнее обстоятельство стало доминирующим при разработке широкого круга современных приложений. В этом случае каждая программа представляет собой бесконечный цикл ожидания некоторых заранее определенных событий. Инициаторами событий могут быть другие программы или пользователи. При наступлении отдельного события, например, нажатия клавиши на клавиатуре или щелчка кнопкой мыши, программа выходит из состояния ожидания и реагирует на это событие вполне адекватным образом. Реакция программы при этом тоже связывается с последующими событиями. Наиболее существенным обстоятельством в развитии методологии ООП явилось осознание того факта, что процесс написания программного кода может быть отделен от процесса проектирования структуры программы. Действительно, до того как начать программирование классов, их свойств и методов, необходимо определить, чем же являются сами эти классы. Более того, нужно дать ответы на такие вопросы, как: сколько и какие классы нужно определить для решения поставленной задачи, какие свойства и методы необходимы для придания классам требуемого поведения, а также установить взаимосвязи между классами. Эта совокупность задач не столько связана с написанием кода, сколько с общим анализом требований к будущей программе, а также с анализом конкретной предметной области, для которой разрабатывается программа. Все эти обстоятельства привели к появлению специальной методологии, получившей название методологии объектно-ориентированнного анализа и проектирования (ООАП).
1.3. Методология объектно-ориентированного анализа и проектирования
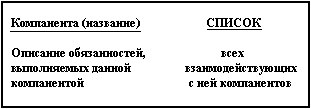
Необходимость анализа предметной области до начала написания программы была осознана давно при разработке масштабных проектов. Процесс разработки баз данных существенно отличается от написания программного кода для решения вычислительной задачи. Главное отличие заключается в том, что при проектировании базы данных возникает необходимость в предварительной разработке концептуальной схемы, которая отражала бы общие взаимосвязи предметной области и особенности организации соответствующей информации. При этом под предметной областью принято понимать ту часть реального мира, которая имеет существенное значение или непосредственное отношение к процессу функционирования программы. Другими словами, предметная область включает в себя только те объекты и взаимосвязи между ними, которые необходимы для описания требований и условий решения некоторой задачи. Выделение исходных или базовых компонентов предметной области, необходимых для решения той или иной задачи, представляет, в общем случае, нетривиальную проблему. Сложность данной проблемы проявляется в неформальном характере процедур или правил, которые можно применять для этой цели. Более того, такая работа должна выполняться совместно со специалистами или экспертами, хорошо знающими предметную область. Например, если разрабатывается база данных для обслуживания пассажиров крупного аэропорта, то в проектировании концептуальной схемы базы данных должны принимать участие штатные сотрудники данного аэропорта. Эти сотрудники должны хорошо знать весь процесс обслуживания пассажиров или данную предметную область. Для выделения или идентификации компонентов предметной области было предложено несколько способов и правил. Сам этот процесс получил название концептуализации предметной области. При этом под компонентой понимают некоторую абстрактную единицу, которая обладает функциональностью, т. е. может выполнять определенные действия, связанные с решением поставленных задач. На предварительном этапе концептуализации рекомендуется использовать так называемые CRC-карточки (Component, Responsibility, Collaborator– компонента, обязанность, сотрудники) [1]. Для каждой выделенной компоненты предметной области разрабатывается собственная CRC-карточка (рис. 1.6).
Рис. 1.6.Общий вид CRC-карточки для описания компонентов предметной области Появление методологии ООАП потребовало, с одной стороны, разработки различных средств концептуализации предметной области, а с другой – соответствующих специалистов, которые владели бы этой методологией. На данном этапе появляется относительно новый тип специалиста, который получил название аналитика или архитектора. Наряду со специалистами по предметной области аналитик участвует в построении концептуальной схемы будущей программы, которая затем преобразуется программистами в код. При этом отдельные компоненты выбираются таким образом, чтобы при последующей разработке их было удобно представить в форме классов и объектов. В этом случае немаловажное значение приобретает и сам язык представления информации о концептуальной схеме предметной области. Разделение процесса разработки сложных программных приложений на отдельные этапы способствовало становлению концепции жизненного цикла программы. Под жизненным циклом (ЖЦ) программы понимают совокупность взаимосвязанных и следующих во времени этапов, начиная от разработки требований к ней и заканчивая полным отказом от ее использования. Стандарт ISO/IEC 12207, хотя и описывает общую структуру ЖЦ программы, не конкретизирует детали выполнения тех или иных этапов. Согласно принятым взглядам ЖЦ программы состоит из следующих этапов:
• Анализа предметной области и формулировки требований к программе
• Проектирования структуры программы
• Реализации программы в кодах (собственно программирования)
• Внедрения программы
• Сопровождения программы
• Отказа от использования программы
На этапе анализа предметной области и .формулировки требований осуществляется определение функций, которые должна выполнять разрабатываемая программа, а также концептуализация предметной области. Эту работу выполняют аналитики совместно со специалистами предметной области. Результатом данного этапа должна являться некоторая концептуальная схема, содержащая описание основных компонентов и тех функций, которые они должны выполнять. Этап проектирования структуры программы заключается в разработке детальной схемы будущей программы, на которой указываются классы, их свойства и методы, а также различные взаимосвязи между ними. Как правило, на этом этапе могут участвовать в работе аналитики, архитекторы и отдельные квалифицированные программисты. Результатом данного этапа должна стать детализированная схема программы, на которой указываются все классы и взаимосвязи между ними в процессе функционирования программы. Согласно методологии ООАП, именно данная схема должна "служить исходной информацией для написания программного кода. Этап программирования вряд ли нуждается в уточнении, поскольку является наиболее традиционным для программистов. Появление инструментариев быстрой разработки приложений (Rapid Application Development, RAD) позволило существенно сократить время, и затраты на выполнение этого этапа. Результатом данного этапа является программное приложение, которое обладает требуемой функциональностью и способно решать нужные задачи в конкретной предметной области. Этапы внедрения и сопровождения программы связаны с необходимостью настройки и конфигурирования среды программы, а также с устранением возникших в процессе ее использования ошибок. Иногда в качестве отдельного этапа выделяют тестирование программы, под которым понимают проверку работоспособности программы на некоторой совокупности исходных данных или при некоторых специальных режимах эксплуатации. Результатом этих этапов является повышение надежности Программного приложения, исключающего возникновение критических ситуаций или нанесение ущерба компании, использующей данное приложение.
Методология ООАП тесно связана с концепцией автоматизированной разработки программного обеспечения (Computer Aided Software Engineering, CASE). Появление первых CASE-средств было встречено с определенной настороженностью. Со временем появились как восторженные Отзывы об их применении, так и критические оценки их возможностей. Причин для столь противоречивых мнений было несколько. Первая из них заключается в том, что ранние CASE-средства были простой надстройкой над некоторой системой управления базами данных (СУБД). Хотя визуализация процесса разработки концептуальной схемы БД имеет немаловажное значение, она не решает проблем разработки приложений других типов. Вторая причина имеет более сложную природу, поскольку связана с графической нотацией, реализованной в том или ином CASE-средстве. Если языки программирования имеют строгий синтаксис, то попытки предложить подходящий синтаксис для визуального представления концептуальных схем БД были восприняты далеко неоднозначно. Появилось несколько подходов, которые более подробно будут рассмотрены в главе 2. На этом фоне появление унифицированного языка моделирования (Unified Modeling Language, UML), который ориентирован на решение задач первых двух этапов ЖЦ программ, было воспринято с большим оптимизмом всем сообществом корпоративных программистов.
Последнее, на что следует обратить внимание, это осознание необходимости построения предварительной модели программной системы, которую, согласно современным концепциям ООАП, следует считать результатом первых этапов ЖЦ программы. Поскольку язык UML даже в своем названии имеет отношение к моделированию, следует дополнительно остановиться на целом ряде достаточно важных вопросов. Таким образом, мы переходим к теме, которая традиционно не рассматривается в изданиях по ООАП, но имеющая самое прямое отношение к процессу построения моделей и, собственно, моделированию. Речь идет о методологии системного анализа и системного моделирования.
1.4. Методология системного анализа и системного моделирования
Системный анализ как научное направление имеет более давнюю историю, чем ООП и ООАП, и собственный предмет исследования. Центральным понятием системного анализа является понятие системы, под которой понимается совокупность объектов, компонентов или элементов произвольной природы, образующих некоторую целостность. Определяющей предпосылкой выделения некоторой совокупности как системы является возникновение у нее новых свойств, которых не имеют составляющие ее элементы. Примеров систем можно привести достаточно много – это персональный компьютер, автомобиль, человек, биосфера, программа и др. Более ортодоксальная точка зрения предполагает, что все окружающие нас предметы являются системами. Важнейшими характеристиками любой системы являются ее структура и процесс функционирования. Под структурой системы понимают устойчивую во времени совокупность взаимосвязей между ее элементами или компонентами. Именно структура связывает воедино все элементы и препятствует распаду системы на отдельные компоненты. Структура системы может отражать самые различные взаимосвязи, в том числе и вложенность элементов одной системы в другую. В этом случае принято называть более мелкую или вложенную систему подсистемой, а более крупную – метасистемой. Процесс функционирования системы тесно связан с изменением ее свойств или поведения во времени. При этом важной характеристикой системы является ее состояние, под которым понимается совокупность свойств или признаков, которые в каждый момент времени отражают наиболее существенные особенности поведения системы. Рассмотрим следующий пример. В качестве системы представим себе «Автомобиль». Для этого случая система охлаждения двигателя будет являться подсистемой «Автомобиля». С одной стороны, двигатель является элементом системы «Автомобиль». С другой стороны, двигатель сам является системой, состоящей из отдельных компонентов, таких как цилиндры, свечи зажигания и др. Поэтому система «Двигатель» также будет являться подсистемой системы «Автомобиль». Структура системы «Автомобиль» может быть описана с разных точек зрения. Наиболее общее представление о структуре этой системы дает механическая схема устройства того или иного автомобиля. Взаимодействие элементов в этом случае носит механический характер. Состояние автомобиля можно рассматривать также с различных точек зрения, наиболее общей из которых является характеристика автомобиля как исправного или неисправного. Очевидно, что каждое из этих состояний в отдельных ситуациях может быть детализировано. Например, состояние «неисправный» может быть конкретизировано в состояния «неисправность двигателя», «неисправность аккумулятора», «отсутствие подачи топлива» и пр. Важно иметь четкое представление, что подобная детализация должна быть адекватна решаемой задаче. Процесс функционирования системы отражает поведение системы во времени и может быть представлен как последовательное изменение ее состояний: Если система изменяет одно свое состояние на другое, то принято говорить, что система переходит из одного состояния в другое. Совокупность признаков или условий изменения состояний системы в этом случае называется переходом. Для системы с дискретными состояниями процесс функционирования может быть представлен в виде последовательности состояний с соответствующими переходами. Более точное графическое описание процесса функционирования систем будет дано в главе 2. Методология системного анализа служит концептуальной основой системно-ориентированной декомпозиции предметной области. В этом случае исходными компонентами концептуализации являются системы и взаимосвязи между ними. При этом понятие системы является более общим, чем понятия классов и объектов в ООАП. Результатом системного анализа является построение некоторой модели системы или предметной области. Понятие модели столь широко используется в повседневной жизни, что приобрело очень много смысловых оттенков. Это и «Дом моделей» известного кутюрье, и модель престижной марки автомобиля, и модель политического руководства, и математическая модель колебаний маятника. Применительно к программным системам нас будет интересовать только то понятие модели, которое используется в системном анализе. А именно, под моделью будем понимать некоторое представление о системе, отражающее наиболее существенные закономерности ее структуры и процесса функционирования и зафиксированное на некотором языке или в другой форме. Примеров моделей можно привести достаточно много. Например, аэродинамическая модель гоночного автомобиля или проектируемого самолета, модель ракетного двигателя, модель колебательной .системы, модель системы электроснабжения региона, модель избирательной компании и др. Общим свойством всех моделей является их подобие оригинальной системе или системе-оригиналу. Важность построения моделей заключается в возможности их использования для получения информации о свойствах или поведении системы-оригинала. При этом процесс построения и последующего применения моделей для получения информации о системе-оригинале получил название моделирование.
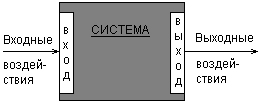
Наиболее общей моделью системы является так называемая модель «черного ящика». В этом случае система представляется в виде прямоугольника, внутреннее устройство которого скрыто от аналитика или неизвестно. Однако система не является полностью изолированной от внешней среды, поскольку последняя оказывает на систему некоторые информационные или материальные воздействия. Такие воздействия получили название входных воздействий. В свою очередь, система также оказывает на среду или другие системы определенные информационные или материальные воздействия, которые получили название выходных воздействий. Графически данная модель может быть изображена следующим образом (рис. 1.7).
Рис. 1.7.Графическое изображение модели системы в виде «черного ящика» Ценность моделей, подобных модели «черного ящика», весьма условна. Невольно может возникнуть ассоциация с «Черным квадратом». Однако если оценка изобразительных особенностей последнего не входит в задачи системного анализа, то общая модель системы содержит некоторую важную инфомацию о функциональных особенностях данной системы, которые дают представление о ее поведении. Действительно, кроме самой общей информации о том, на какие воздействия реагирует система, и как проявляется эта реакция на окружающие объекты и системы, другой информации мы получить не можем. В рамках системного анализа разработаны определенные методологические средства, позволяющие выполнить дальнейшую конкретизацию общей модели системы. Некоторые из графических средств представления моделей систем будут рассмотрены в главе 2. Процесс разработки адекватных моделей и их последующего конструктивного применения требует не только знания общей методологии системного анализа, но и наличия соответствующих изобразительных средств или языков для фиксации результатов моделирования и их документирования. Очевидно, что естественный язык не вполне подходит для этой цели, поскольку обладает неоднозначностью и неопределенностью. Для построения моделей были разработаны достаточно серьезные теоретические методы, основанные на развитии математических и логических средств моделирования, а также предложены различные формальные и графические нотации, отражающие специфику решаемых задач. Важно представлять, что унификация любого языка моделирования тесно связана с методологией системного моделирования, т. е. с системой воззрений и принципов рассмотрения сложных явлений и объектов как моделей сложных систем. Сложность системы и, соответственно, ее модели может быть рассмотрена с различных точек зрения. Прежде всего, можно выделить сложность структуры системы, которая характеризуется количеством элементов системы и различными типами взаимосвязей между этими элементами. Если количество элементов превышает некоторое пороговое значение, которое не является строго фиксированным, то такая система может быть названа сложной. Например, если программная СУБД насчитывает более 100 отдельных форм ввода и вывода информации, то многие программисты сочтут ее сложной. Транспортная система современных мегаполисов также может служить примером сложной системы. Вторым аспектом сложности является сложность процесса функционирования системы. Это может быть связано как с непредсказуемым характером поведения системы, так и невозможностью формального представления правил преобразования входных воздействий в выходные. В качестве примеров сложных программных систем можно привести современные операционные системы, которым присущи черты сложности как структуры, так и поведения.
ГЛАВА 2 Исторический обзор развития методологии объектно-ориентированного анализа и проектирования сложных систем
2.1. Предыстория. Математические основы
Представление различных понятий окружающего нас мира при помощи графической символики уходит своими истоками в глубокую древность. В качестве примеров можно привести условные обозначения знаков Зодиака, магические символы различных оккультных доктрин, графические изображения геометрических фигур на плоскости и в пространстве. Важным достоинством той или иной графической нотации является возможность образного закрепления содержательного смысла или семантики отдельных понятий, что существенно упрощает процесс общения между посвященными в соответствующие теории и идеологии.
Теория множеств
Как одну из наиболее известных систем графических символов, оказавших непосредственное влияние на развитие научного мышления, следует отметить язык диаграмм английского логика Джона Венна (1834-1923). В настоящее время диаграммы Венна применяются для иллюстрации основных теоретико-множественных операций, которые являются предметом специального раздела математики – теории множеств. Поскольку многие общие идеи моделирования систем имеют адекватное описание в терминологии теории множеств, рассмотрим основные понятия данной теории, имеющие отношение к современным концепциям и технологиям исследования сложных систем. Исходным понятием теории множеств является само понятие множество, под которым принято понимать некоторую совокупность объектов, хорошо различимых нашей мыслью или интуицией. При этом не делается никаких предположений ни о природе этих объектов, ни о способе их включения в данную совокупность. Отдельные объекты, составляющие то или иное множество, называют элементами данного множества. Вопрос «Почему мы рассматриваем ту или иную совокупность элементов как множество?» не требует ответа, поскольку в общее определение множества не входят никакие дополнительные условия на включение отдельных элементов в множество. Если нам хочется, например, рассмотреть множество, состоящее из трех элементов: «солнце, море, апельсин», то никто не сможет запретить это сделать. Примеров конкретных множеств можно привести достаточно много. Это и множество квартир жилого дома, и множество натуральных чисел, с которого начинается знакомство каждого ребенка с великим таинством счета. Совокупность компьютеров в офисе тоже представляет собой множество, хотя, возможно, они и соединены между собою в сеть. Множество живущих на планете людей, как и множество звезд на небосводе, тоже могут служить примерами множеств, хотя природа их существенно различна.
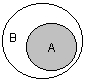
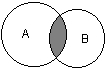
В теории множеств используется специальное соглашение, по которому множества обозначаются прописными буквами латинского алфавита, и традиция эта настолько общепризнана, что не возникает никакого сомнения в ее целесообразности. При этом отдельные элементы обозначаются строчными буквами, иногда с индексами, которые вносят некоторую упорядоченность в последовательность рассмотрения этих элементов. Важно понимать, что какой бы то ни было порядок, вообще говоря, не входит в исходное определение множества. Таким образом, множество, например, квартир 100-квартирного жилого дома с использованием специальных обозначений можно записать следующим образом: A={aj, 02, а3, ..., а{00}. Здесь фигурные скобки служат обозначением совокупности элементов, каждый из которых имеет свой уникальный числовой индекс. Важно понимать, что для данного конкретного множества элемент ato обозначает отдельную квартиру в рассматриваемом жилом доме. При этом вовсе необязательно, чтобы номер этой квартиры был равен 10, хотя с точки зрения удобства это было бы желательно. Принято называть элементы отдельного множества принадлежащими данному множеству. Данный факт записывается при помощи специального символа "е", который так и называется – символ принадлежности. Например, запись а10ьА означает тот простой факт, что отдельная квартира (возможно, с номером 10) принадлежит рассматриваемому множеству квартир некоторого жилого дома. Следующим важным понятием, которое служит прототипом многих более конкретных терминов при моделировании сложных систем, является понятие подмножества. Казалось бы, интуитивно и здесь нет ничего неясного. Если есть некоторая совокупность, рассматриваемая как множество, то любая ее часть и будет являться подмножеством. Так, например, совокупность квартир на первом этаже жилого дома есть ничто иное, как подмножество рассматриваемого нами примера. Ситуация становится не столь тривиальной, если рассматривать множество абстрактных понятий, таких как сущность или класс. Для обозначения подмножества используется специальный символ. Если утверждается, что множество А является подмножеством множества В, то это записывается как Аа В. Запоминать подобные значки не всегда удобно, поэтому со временем была предложена специальная система графических обозначений. Как же используются диаграммы Венна в теории множеств? Оказывается, тот факт, что некоторая совокупность элементов образует множество, можно обозначить графически в виде круга. В этом случае окружность имеет содержательный смысл или, выражаясь более точным языком, семантику границы данного множества. Очевидно, что рассмотрение отношения включения элементов одного множества в другое можно изобразить графически следующим образом (рис. 2.1). На этом рисунке большему множеству В соответствует внешний круг, а меньшему множеству (подмножеству) А – внутренний.
Рис. 2.1.Диаграмма Венна для отношения включения двух множеств Подобным образом можно изобразить и основные теоретико-множественные операции. Так, пересечением двух множеств А и В называется некоторое третье множество С, которое состоит из тех и только тех элементов двух исходных множеств, которые одновременно принадлежат и множеству А, и множеству В. Для этой операции также имеется специальное обозначение: С= А о В. Например, если в качестве множества А для операции пересечения рассмотреть множество сотрудников некоторой фирмы, а в качестве множества В – множество всех мужчин, то нетрудно догадаться, что множество С будет состоять из элементов -± всех сотрудников мужского пола данной фирмы. Операция пересечения множеств также может быть проиллюстрирована с помощью диаграмм Венна (рис. 2.2). На этом рисунке условно изображены два множества А и В, затененной области как раз и соответствует множество С, являющееся пересечением множеств А и В.
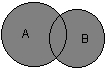
Рис. 2.2Диаграмма Венна для пересечения двух множеств Следующей операцией, которая также допускает наглядную интерпретацию, является операция объединения множеств. Под объединением двух множеств А и В понимается некоторое третье множество, пусть это будет D, которое состоит из тех и только тех элементов, которые принадлежат или А, или В, или им обоим одновременно. Конечно, специальное обозначение есть и для этой операции: D= AuB. Так, если в качестве множества А рассмотреть множество, состоящее из клавиатуры и мыши, а в качестве множества В – множество, состоящее из системного блока и монитора, то нетрудно догадаться, что их объединение, т. е. множество D, образует основные составляющие персонального компьютера. И для этой операции имеется условное графическое представление (рис. 2.3). На этом рисунке объединению двух исходных множеств также соответствует затемненная область, только размеры и форма ее отличаются от случая пересечения двух множеств на предыдущем рисунке.
Рис. 2.3.Диаграмма Венна для объединения двух множеств
Последнее, на что следовало бы обратить внимание при столь кратком знакомстве с основами теории множеств – это на так называемые понятия мощности множества и отношения множеств. Хотя существуют и другие операции над множествами, а также целый ряд дополнительных понятий, их рассмотрение выходит за рамки настоящей книги. Что касается понятия мощности множества, то данный термин важен для анализа кратности связей, поскольку ассоциируется с количеством элементов отдельного множества. В случае конечного множества ситуация очень простая, поскольку мощность конечного множества равна количеству элементов этого множества. Таким образом, возвращаясь к примеру с множеством А квартир жилого дома, можно сказать, что его мощность равна 100. Ситуация усложняется, когда рассматриваются бесконечные множества, т. е. множества, не являющиеся конечными. Не вдаваясь в технические детали, которые послужили источником драматичного по своим последствиям кризиса основ математики, ограничим наше рассмотрение бесконечными множествами счетной мощности. Такими множествами принято считать множества, содержащие бесконечное число элементов, которые, однако, можно перенумеровать натуральными числами 1, 2, 3 и т. д. При этом важно иметь в виду, что достичь последнего элемента при такой нумерации принципиально невозможно, иначе множество окажется конечным. Например, есть все основания считать множество всех звезд бесконечным, хотя многие из них имеют свое уникальное название. С другой стороны, множество всех возможных комбинаций из 8 символов, которые могут служить для ввода некоторого пароля, конечное, хотя и достаточно большое. Или, говоря строгим языком, это множество имеет конечную мощность.
Наконец, было упомянуто и следующее понятие, различные аспекты которого будут служить темой рассмотрения во всех последующих главах. Это фундаментальное понятие отношения множеств, которое часто заменяется терминами связь или соотношение. Данный термин ведет свое происхождение от теории множеств и служит для обозначения любого подмножества упорядоченных кортежей, построенных из элементов некоторых исходных множеств. При этом под кортежем понимается просто набор или список элементов, важно только, чтобы они были упорядочены. Другими словами, если рассматривать первый элемент кортежа, то он всегда будет первым в списке элементов, второй элемент кортежа будет вторым элементом в списке и т. д. Можно ли это записать с использованием специальных обозначений? Хотя и существует некоторая неоднозначность в принятых обозначениях, кортеж из двух элементов удобно обозначать как <a1, a2>, из трех элементов – <a1, a2, a3> и т. д. При этом отдельные элементы могут принадлежать как одному и тому же множеству, так и различным множествам. Важно иметь в виду, что порядок выбора элементов для построения кортежей строго фиксирован для конкретной задачи. Речь идет о том, что первый элемент всегда выбирается из первого множества, второй – из второго, и т. д: Отношение в этом случае будет характеризовать способ или семантику выбора отдельных элементов из одного или нескольких множеств для подобного упорядоченного списка. В этом смысле взаимосвязь является частным случаем отношения, о чем будет сказано в последующем. К сожалению, диаграммы Венна не предназначены для иллюстрации отношений в общем случае. Однако отношения послужили исходной идеей для развития другой теории, которая даже в своем названии несет отпечаток графической нотации, а именно – теории графов. В этой связи наиболее важным является тот факт, что теоретико-множественные отношения послужили также основой для разработки реляционной алгебры в теории реляционных баз данных. Развитие последней привело к тому, что в последние годы именно реляционные СУБД конкретных фирм доминируют на рынке соответствующего программного обеспечения.
Теория графов
Граф можно рассматривать как графическую нотацию для бинарного отношения двух множеств. Бинарное отношение состоит из таких кортежей или списков элементов, которые содержат только два элемента некоторого множества. Хотя основные понятия теории графов получили свое развитие задолго до появления теории множеств как самостоятельной научной дисциплины, формальное определение графа удобно представить в теоретико-множественных терминах. Графом называется совокупность двух множеств: множества точек или вершин и множества соединяющих их линий или ребер. Формально граф задается в виде двух множеств: G=(V, Е), где V={v1v2, ..., vn} – множество вершин графа, а Е={е1, е2, ..., еm} – множество ребер графа. Натуральное число n определяет общее количество вершин конкретного графа, а натуральное число m – общее количество ребер графа. Следует заметить, в общем случае не все вершины графа могут соединяться между собой, что ставит в соответствие каждому графу некоторое бинарное отношение PQ, состоящее из всех пар вида <vi, vj>, где vi, vj = V. При этом пара <vi, vj> и, соответственно, пара <vj, vi> принадлежат отношению PG в том и только в том случае, если вершины vi и vj соединяются в графе G некоторым ребром ek=Е. Вершины графа изображаются точками, а ребра – отрезками прямых линий. Рядом с вершинами и ребрами записываются соответствующие номера или идентификаторы, позволяющие их идентифицировать однозначным образом.
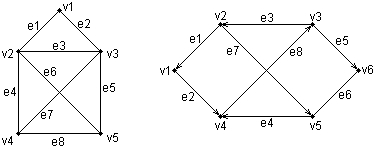
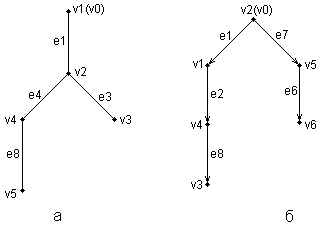
Ниже представлены два примера конкретных графов (рис. 2.4). При этом первый из них (рис. 2.4, а) является неориентированным графом, а второй (рис. 2.4, б) – ориентированным графом. Как нетрудно заметить, для неориентированного графа ребро е1 соединяет вершины v1 и v2, ребро е2 – вершины v1 и v3, а ребро e3 – вершины v2 и v3 и т. д. Последнее ребро, e8, соединяет вершины v4 и v5, тем самым задается описание графа в целом. Других ребер данный граф не содержит, как не содержит других вершин, не изображенных на рисунке. Так, хотя ребра е6 и e7 визуально пересекаются, но точка их пересечения не является вершиной графа. Для ориентированного графа (рис. 2.4, б) ситуация несколько иная. А именно, вершины v1 и v2 соединены дугой е1, для которой вершина v2 является началом дуги, а вершина v1 – концом этой дуги. Далее дуга е2 соединяет вершины v1 и v4, при этом началом дуги e2 является вершина v1, а концом – вершина v4.
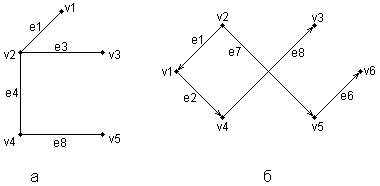
Рис. 2.4.Примеры неориентированного (а) и ориентированного (б) графов Графы широко применяются для представления различной информации о структуре систем и процессов. Примерами подобных графических моделей могут служить: схемы автомобильных дорог, соединяющих отдельные населенные пункты; схемы телекоммуникаций, используемых для передачи информации между отдельными узлами; схемы программ, на которых указываются варианты ветвления вычислительного процесса. Общим для всех конкретных подобных моделей является возможность представления информации в графическом виде в форме соответствующего графа. При этом отдельные модели, как правило, обладают дополнительной семантикой и специальными обозначениями, характерными для той или иной предметной области. Важными понятиями теории графов являются понятия маршрута и пути, которые ассоциируются с последовательным перемещением от вершины к вершине по соединяющим их ребрам или дугам. Для неориентированного графа маршрут определяется как конечная или бесконечная упорядоченная последовательность ребер S=<, esl, es2, ..., esk>>, таких, что каждые два соседних ребра имеют общую вершину. Нас будут интересовать только конечные маршруты S=<es1, es2, ..., esk>, т. е. такие маршруты, которые состоят из конечного числа ребер. При этом ребро esl принято считать началом маршрута S, а ребро esk – концом маршрута S. Для ориентированного графа соответствующая последовательность дуг S=<es1, es2, ..., esk> называется ориентированным маршрутом, если две соседние дуги имеют общую вершину, которая является концом предыдущей и началом последующей дуги. Примерами маршрутов для неориентированного графа (рис. 2.4, а) являются последовательности ребер: S1=<e1, e2 e5, e8>, S2=<e1, e2, е3, e1>, S3=<e3, e5, e8>. Если в маршруте не повторяются ни ребра, ни вершины, как в случае S1 и S3, то такой неориентированный маршрут называется простой цепью. Примерами ориентированных маршрутов для графа (рис. 2.4, б) являются такие последовательности дуг: S1=<e2, e8, e5>, S2=<e3, e7, e6>, S3=<e8, e3, e7, e4, e8>. Если в ориентированном маршруте не повторяются ни ребра, ни вершины, как в случае S1 и S2, то такой ориентированный маршрут называется путем. Последнее понятие также иногда применяется для обозначения простой цепи в неориентированных графах и для определения специального класса графов, так называемых деревьев. В общем случае деревья служат для графического представления иерархических структур или иерархий, занимающих важное место в ООАП. Деревом в теории графов называется такой граф D=<V, E>, между любыми двумя вершинами которого существует единственная простая цепь, т. е. неориентированный маршрут, у которого вершины и ребра не повторяются. Применительно к ориентированным графам соответствующее определение является более сложным, поскольку основывается на выделении некоторой специальной вершины v0, которая получила специальное название корневой вершины или просто – корня. В этом случае ориентированный граф D=<V, Е> называется ориентированным деревом или сокращенно – деревом, если между корнем дерева v0 и любой другой вершиной существует единственный путь, берущий начало в v0. Ниже представлены два примера деревьев: неориентированного дерева (рис. 2.5, а) и ориентированного дерева (рис. 2.5, б). В случае неориентированного дерева (рис. 2.5, а) любая из вершин графа может быть выбрана в качестве корня. Подобный выбор определяется специфическими особенностями решаемой задачи. Так, вершина v1 может рассматриваться в качестве корня неориентированного дерева, поскольку между v1 и любой другой вершиной дерева всегда существует единственная простая цепь по определению (или, что менее строго, единственный неориентированный путь).
Рис. 2.5.Примеры неориентированного (а) и ориентированного (б) деревьев Для случая ориентированного дерева (рис. 2.5, б) вершина v2 является единственным его корнем и имеет специальное обозначение v0. Единственность корня в ориентированном дереве следует из того факта, что ориентированный путь всегда имеет единственную вершину, которая является его началом. Поскольку в теории графов имеет значение только наличие или отсутствие связей между отдельными вершинами, деревья, как правило, изображаются специальным образом в виде иерархической структуры. При этом корень дерева изображается самой верхней вершиной в данной иерархии. Далее следуют вершины уровня 1, которые связаны с корнем одним ребром или одной дугой. Следующий уровень будет иметь номер 2, поскольку соответствующие вершины должны быть связаны с корнем двумя последовательными ребрами или дугами. Процесс построения иерархического дерева продолжается до тех пор, пока не будут рассмотрены вершины, которые не связаны с другими вершинами, кроме рассмотренных, или из которых не выходит ни одна дуга. В этом случае самые нижние вершины иногда называют листьями дерева. Важно иметь в виду, что в теории графов дерево «растет» вниз, а не вверх, как в реальной жизни. Изображенные выше деревья (рис. 2.5) можно преобразовать к виду иерархий. Например, неориентированное дерево (рис. 2.5, а) может быть представлено в виде иерархического дерева следующим образом (рис. 2.6, а). В этом случае корнем иерархии является вершина v1. Ориентированное дерево (рис. 2.5, б) также может быть изображено в форме иерархического дерева (рис. 2.6, б), однако такое представление является единственным. В первом случае (рис. 2.6, а) вершина v2 образует первый уровень иерархии, вершины v4 и v3 – второй уровень иерархии, вершина v5 – третий и последний уровень иерархии. При этом листьями данного неориентированного дерева являются вершины v3 и v5. Во втором случае (рис. 2.6, б) вершины v1 и v5 образуют первый уровень иерархии, вершины v4 и v6 – второй уровень иерархии, вершина v3 – третий и последний уровень иерархии. Листьями данного ориентированного дерева являются вершины v3 и v6.
Рис. 2.6.Иерархические схемы неориентированного дерева (а) и ориентированного дерева (б) В заключение следует заметить, что в теории графов разработаны различные методы анализа отдельных классов графов и алгоритмы построения специальных графических объектов, рассмотрение которых выходит за рамки настоящей книги. Для получения дополнительной информации по данной теме можно рекомендовать обратиться к специальной литературе по теории графов, где эти вопросы рассмотрены более подробно. В дальнейшем нас будет интересовать отдельное направление в теории графов, которое связано с явным включением семантики в традиционные обозначения и получившее самостоятельное развитие в форме семантических сетей.
Семантические сети
Семантические сети получили свое развитие в рамках научного направления, связанного с представлением знаний для моделирования рассуждений человека. Эта область научных исследований возникла в рамках общей проблематики искусственного интеллекта и была ориентирована на разработку специальных языков и графических средств для представления декларативных или, что менее точно, статических знаний о предметной области. Результаты исследований в области семантических сетей в последующем были конкретизированы и успешно использованы при построении концептуальных моделей и схем реляционных баз данных. В общем случае под семантической сетью понимают некоторый граф Gs= =(Vs, Es), в котором множество вершин Vs и множество ребер Es разделены на отдельные типы, обладающие специальной семантикой, характерной для той или иной предметной области. В данной ситуации множество вершин может соответствовать объектам или сущностям рассматриваемой предметной области и иметь вместо номеров вершин соответствующие явные имена этих сущностей. Подобные имена должны позволять однозначно идентифицировать соответствующие объекты, при этом общих формальных правил записи имен не существует. Множество ребер также делится на различные типы, которые соответствуют различным видам связей между сущностями рассматриваемой предметной области. Так, при построении семантической сети для представления знаний о рабочем персонале некоторой компании в качестве объектов целесообразно выбрать отдельных сотрудников, каждого из которых идентифицировать собственным именем и фамилией. Дополнительно в сети могут присутствовать такие объекты, как рабочие проекты и подразделения компании. В качестве семантических связей можно выделить такие виды, как должностное подчинение сотрудников, участие сотрудников в работе над проектами, принадлежность сотрудников тому или иному подразделению компании. Важной особенностью семантических сетей является разработка специальных графических обозначений для представления отдельных типов вершин и ребер. При этом вершины не изображаются, как ранее – точками, а имеют вид прямоугольников, овалов, окружностей и других геометрических фигур, конкретный вид которых определяет тот или иной тип сущностей предметной области. Более разнообразным становится и изображение ребер, приобретающих вид различных линий со стрелками или без них, а также имеющих специальные обозначения или украшения в виде условных значков. Соответствующая система обозначений, предназначенная для представления информации об отдельных аспектах моделируемой предметной области, получила название графической нотации.
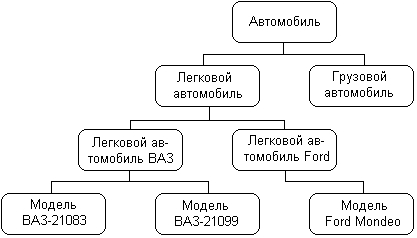
В качестве конкретного варианта представления информации в виде семантической сети рассмотрим дальнейшее развитие примера с классом «Автомобиль» из главы 1. Фрагмент семантической сети, которая описывает иерархию классов данной предметной области, может быть изображен следующим образом (рис. 2.7). На данном рисунке отдельные вершины семантической сети изображаются прямоугольниками с закругленными концами и служат для условного обозначения классов данной предметной области. Соединяющие вершины ребра имеют вполне определенный смысл или семантику. А именно, они явно указывают, что вершина или класс, расположенные на рисунке ниже, являются подклассом того класса уровнем выше, с которым имеется связь в форме соединяющего их ребра. Например, классы «Легковой автомобиль» и «Грузовой автомобиль» являются подклассами класса «Автомобиль», а классы «Модель ВАЗ-21083» и «Модель ВАЗ-21099» являются подклассами класса «Легковой автомобиль производства ВАЗ». Ребра или связи данной семантической сети имеют единственный тип, определяемый семантикой включения классов друг в друга. Поэтому никаких дополнительных обозначений они не содержат.
Рис 2.7.Фрагмент семантической сети для представления иерархии классов «Автомобиль»
Построение моделей сложных систем, отражающих десятки различных типов объектов и связей между ними, привело в конце 80-х годов к появлению большого числа различных графических нотаций, которые в той или иной степени были ориентированы на решение специальных классов задач. Сложилась парадоксальная ситуация, которая получила название «войны методов». Многие подходы, хотя и имели общие истоки, совершенно игнорировали другие альтернативные способы представления семантической информации. Наибольшее распространение в эти годы получил подход к моделированию программных систем, который назвали системным структурным анализом (ССА). Поскольку многие идеи ССА оказали непосредственное влияние на развитие языка UML, а используемая графическая нотация была реализована в некоторых CASE-средствах, ниже приводится краткая характеристика основных компонентов данного направления графического моделирования программных систем.
2.2. Диаграммы структурного системного анализа
Под структурным системным анализом принято понимать метод исследования системы, который начинается с наиболее общего ее описания с последующей детализацией представления отдельных аспектов ее поведения и функционирования. При этом общая модель системы строится в виде некоторой иерархической структуры, которая отражает различные уровни абстракции с ограниченным числом компонентов на каждом из уровней. Одним из главных принципов структурного системного анализа является выделение на каждом из уровней абстракции только наиболее существенных компонентов или элементов системы.
В рамках данного направления программной инженерии принято рассматривать три графические нотации, получивших названия диаграмм: диаграммы «сущность-связь» (Entity-Relationship Diagrams, ERD), диаграммы функционального моделирования (Structured Analysis and Design Technique, SADT) и диаграммы потоков данных (Data Flow Diagrams, DFD).
Диаграммы «сущность-связь»
Данная нотация была предложена П. Ченом (P. Chen) в его известной работе 1976 года [17] и получила дальнейшее развитие в работах Р. Баркера [16] (R. Barker). Диаграммы «сущность-связь» (ERD) предназначены для графического представления моделей данных разрабатываемой программной системы и предлагают некоторый набор стандартных обозначений для определения данных и отношений между ними. С помощью этого вида диаграмм можно описать отдельные компоненты концептуальной модели данных и совокупность взаимосвязей между ними, имеющих важное значение для разрабатываемой системы. Основными понятиями данной нотации являются понятия сущности и связи. При этом под сущностью (entity) понимается произвольное множество реальных или абстрактных объектов, каждый из которых обладает одинаковыми свойствами и характеристиками. В этом случае каждый рассматриваемый объект может являться экземпляром одной и только одной сущности, должен иметь уникальное имя или идентификатор, а также отличаться от других экземпляров данной сущности. Примерами сущностей могут быть: банк, клиент банка, счет клиента, аэропорт, пассажир, рейс, компьютер, терминал, автомобиль, водитель. Каждая из сущностей может рассматриваться с различной степенью детализации и на различном уровне абстракции, что определяется конкретной постановкой задачи. Для графического представления сущностей используются специальные обозначения (рис. 2.8).
Рис. 2.8.Графические изображения для обозначения сущностей Связь (relationship) определяется как отношение или некоторая ассоциация между отдельными сущностями. Примерами связей могут являться родственные отношения типа «отец-сын» или производственные отношения типа «начальник-подчиненный». Другой тип связей задается отношениями «иметь в собственности» или «обладать свойством». Различные типы связей графически изображаются в форме ромба с соответствующим именем данной связи (рис. 2.9).
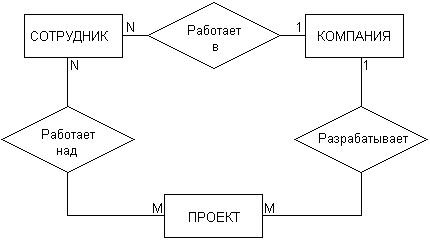
Рис. 2.9.Графические изображения для обозначения связей Графическая модель данных строится таким образом, чтобы связи между отдельными сущностями отражали не только семантический характер соответствующего отношения, но и дополнительные аспекты обязательности связей, а также кратность участвующих в данных отношениях экземпляров сущностей. Рассмотрим в качестве простого примера ситуацию, которая описывается двумя сущностями: «Сотрудник» и «Компания». При этом в качестве связи естественно. использовать отношение принадлежности сотрудника данной компании. Если учесть соображения о том, что в компании работают несколько сотрудников, и эти сотрудники не могут быть работниками других компаний, то данная информация может быть представлена графически в виде следующей диаграммы «сущность-связь» (рис. 2.10). На данном рисунке буква "N" около связи означает тот факт, что в компании могут работать более одного сотрудника, при этом значение N заранее не фиксируется. Цифра "1" на другом конце связи означает, что сотрудник может работать только в одной конкретной компании, т. е. не допускается прием на работу сотрудников по совместительству из других компаний или учреждений.
Рис. 2.10.Диаграмма «сущность-связь» для примера сотрудников некоторой компании Несколько иная ситуация складывается в случае рассмотрения сущностей «сотрудник» и «проект», и связи «участвует в работе над проектом» (рис. 2.11). Поскольку в общем случае один сотрудник может участвовать в разработке нескольких проектов, а в разработке одного проекта могут принимать участие несколько сотрудников, то данная связь является многозначной. Данный факт специально отражается на диаграмме указанием букв "N" и "М" около соответствующих сущностей, при этом выбор конкретных букв не является принципиальным.
Рис. 2.11.Диаграмма «сущность-связь» для примера сотрудников, участвующих в работе над проектами Рассмотренные две диаграммы могут быть объединены в одну, на которой будет представлена информация о сотрудниках компании, участвующих в разработке проектов данной компании (рис. 2.12). При этом может быть введена дополнительная связь, характеризующая проекты данной компании.
Рис. 2.12.Диаграмма «сущность-связь» для общего примера компании
Ограниченность ERD проявляется при конкретизации концептуальной модели в более детальное представление моделируемой программной системы, которое кроме статических связей должно содержать информацию о поведении или функционировании отдельных ее компонентов. Для этих целей в рамках ССА используется другой тип диаграмм, получивших название диаграмм потоков данных. А сейчас перейдем к диаграммам SADT.
Диаграммы функционального моделирования
Начало разработки диаграмм функционального моделирования относится к середине 1960-х годов, когда Дуглас Т. Росс предложил специальную технику моделирования, получившую название SADT (Structured Analysis & Design Technique). Военно-воздушные силы США использовали методику SADT в качестве части своей программы интеграции компьютерных и промышленных технологий (Integrated Computer Aided Manufacturing, ICAM) и назвали ее IDEFO (Icam DEFinition). Целью программы ICAM было увеличение эффективности компьютерных технологий в сфере проектирования новых средств вооружений и ведения боевых действий. Одним из результатов этих исследований являлся вывод о том, что описательные языки не эффективны для документирования и моделирования процессов функционирования сложных систем. Подобные описания на естественном языке не обеспечивают требуемого уровня непротиворечивости и полноты, имеющих доминирующее значение при решении задач моделирования. В рамках программы ICAM было разработано несколько графических языков моделирования, которые получили следующие названия:
• Нотация IDEF0 – для документирования процессов производства и отображения информации об использовании ресурсов на каждом из этапов проектирования систем.
• Нотация IDEF1 – для документирования информации о производственном окружении систем.
• Нотация IDEF2 – для документирования поведения системы во времени.
• Нотация IDEF3 – специально для моделирования бизнес-процессов.
Нотация IDEF2 никогда не была полностью реализована. Нотация IDEF1 в 1985 году была расширена и переименована в IDEF1X. Методология IDEF-SADT, нашла применение в правительственных и коммерческих организациях, поскольку на тот период времени вполне удовлетворяла различным требованиям, предъявляемым к моделированию широкого класса систем. В начале 1990 года специально образованная группа пользователей IDEF (IDEF Users Group), в сотрудничестве с Национальным институтом по стандартизации и технологии США (National Institutes for Standards and Technology, NIST), предприняла попытку создания стандарта для IDEFO и IDEF1X. Эта попытка оказалась успешной и завершилась принятием в 1993 году стандарта правительства США, известного как FIPS для данных двух технологий IDEFO и IDEF1X. В течение последующих лет этот стандарт продолжал активно развиваться и послужил основой для реализации в некоторых первых CASE-средствах. Методология IDEF-SADT представляет собой совокупность методов, правил и процедур, предназначенных для построения функциональной модели сиетемы какой-либо предметной области. Функциональная модель SADT отображает структуру процессов функционирования системы и ее отдельных подсистем, т. е. выполняемые ими действия и связи между этими действиями. Для этой цели строятся специальные модели, которые позволяют в наглядной форме представить последовательность определенных действий. Исходными строительными блоками любой модели IDEFO процесса являются деятельность (activity) и стрелки (arrows). Рассмотрим кратко эти основные понятия методологии IDEF-SADT, которые используются при построении диаграмм функционального моделирования. Деятельность представляет собой некоторое действие или набор действий, которые имеют фиксированную цель и приводят к некоторому конечному результату. Иногда деятельность называют просто процессом. Модели IDEFO отслеживают различные виды деятельности системы, их описание и взаимодействие с другими процессами. На диаграммах деятельность или процесс изображается прямоугольником, который называется блоком. Стрелка служит для обозначения некоторого носителя или воздействия, которые обеспечивают перенос данных или объектов от одной деятельности к другой. Стрелки также необходимы для описания того, что именно производит деятельность и какие ресурсы она потребляет. Это так называемые роли стрелок – ICOM – сокращение первых букв от названий соответствующих стрелок IDEFO. При этом различают стрелки четырех видов:
I (Input) – вход, т. е. все, что поступает в процесс или потребляется процессом.
С (Control) – управление или ограничения на выполнение операций процесса.
О (Output) – выход или результат процесса.
М (Mechanism) – механизм, который используется для выполнения процесса.
Методология IDEFO однозначно определяет, каким образом изображаются на диаграммах стрелки каждого вида ICOM. Стрелка Вход (Input) выходит из левой стороны рамки рабочего поля и входит слева в прямоугольник процесса. Стрелка Управление (Control) входит и выходит сверху. Стрелка Выход (Output) выходит из правой стороны процесса и входит в правую сторону рамки. Стрелка Механизм (Mechanism) входит в прямоугольник процесса снизу. Таким образом, базовое представление процесса на диаграммах IDEFO имеет следующий вид (рис. 2.13). Техника построения диаграмм представляет собой главную особенность методологии IDEF-SADT. Место соединения стрелки с блоком определяет тип интерфейса. При этом все функции моделируемой системы и интерфейсы на диаграммах представляются в виде соответствующих блоков процессов и стрелок ICOM. Управляющая информация входит в блок сверху, в то время как информация, которая подвергается обработке, изображается с левой стороны блока. Результаты процесса представляются как выходы процесса и показываются с правой стороны блока. В качестве механизма может выступать человек или автоматизированная система, которые реализуют данную операцию. Соответствующий механизм на диаграмме представляется стрелкой, которая входит в блок процесса снизу.
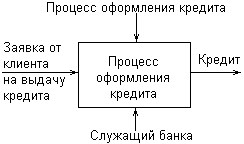
Рис. 2.13.Обозначение процесса и стрелок ICOM на диаграммах IDEF0 Одной из наиболее важных особенностей методологии IDEF-SADT является постепенное введение все более детальных представлений модели системы по мере разработки отдельных диаграмм. Построение модели IDEF-SADT начинается с представления всей системы в виде простейшей диаграммы, состоящей из одного блока процесса и стрелок ICOM, служащих для изображения основных видов взаимодействия с объектами вне системы. Поскольку исходный процесс представляет всю систему как единое целое, данное представление является наиболее общим и подлежит дальнейшей декомпозиции. Для иллюстрации основных идей методологии IDEF-SADT рассмотрим следующий простой пример. В качестве процесса будем представлять деятельность по оформлению кредита в банке. Входом данного процесса является заявка от клиента на получение кредита, а выходом – соответствующий результат, т. е. непосредственно кредит. При этом управляющими факторами являются правила оформления кредита, которые регламентируют условия получения соответствующих финансовых средств в кредит. Механизмом данного процесса является служащий банка, который уполномочен выполнить все операции по оформлению кредита. Пример исходного представления процесса оформления кредита в банке изображен на рис. 2.14.
Рис. 2.14.Пример исходной диаграммы IDEF-SADT для процесса оформления кредита в банке В конечном итоге модель IDEF-SADT представляет собой серию иерархически взаимосвязанных диаграмм с сопроводительной документацией, которая разбивает исходное представление сложной системы на отдельные составные части. Детали каждого из основных процессов представляются в виде более детальных процессов на других диаграммах. В этом случае каждая диаграмма нижнего уровня является декомпозицией некоторого процесса из более общей диаграммы. Поэтому на каждом шаге декомпозиции более общая диаграмма конкретизируется на ряд более детальных диаграмм. В настоящее время диаграммы структурного системного анализа IDEF-SADT продолжают использоваться целым рядом организаций для построения и детального анализа функциональной модели существующих на предприятии бизнес-процессов, а также для разработки новых бизнес-процессов. Основной недостаток данной методологии связан с отсутствием явных средств для объектно-ориентированного представления моделей сложных систем. Хотя некоторые аналитики отмечают важность знания и применения нотации IDEF-SADT, ограниченные возможности этой методологии применительно к реализации соответствующих графических моделей в объектно-ориентированном программном коде существенно сужают диапазон решаемых с ее помощью задач.
Диаграммы потоков данных
Основой данной методологии графического моделирования информационных систем является специальная технология построения диаграмм потоков данных DFD. В разработке методологии DFD приняли участие многие аналитики, среди которых следует отметить Э. Йордона (Е. Yourdon). Он является автором одной из первых графических нотаций DFD [10]. В настоящее время наиболее распространенной является так называемая нотация Гейна-Сарсона (Gene-Sarson), основные элементы которой будут рассмотрены в этом разделе. Модель системы в контексте DFD представляется в виде некоторой информационной модели, основными компонентами которой являются различные потоки данных, которые переносят информацию от одной подсистемы к другой. Каждая из подсистем выполняет определенные преобразования входного потока данных и передает результаты обработки информации в виде потоков данных для других подсистем. Основными компонентами диаграмм потоков данных являются:
• внешние сущности
• накопители данных или хранилища
• процессы
• потоки данных
• системы/подсистемы
Внешняя сущность представляет собой материальный объект или физическое лицо, которые могут выступать в качестве источника или приемника информации. Определение некоторого объекта или системы в качестве внешней сущности не является строго фиксированным. Хотя внешняя сущность находится за пределами границ рассматриваемой системы, в процессе дальнейшего анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы модели системы. С другой стороны, отдельные процессы могут быть вынесены за пределы диаграммы и представлены как внешние сущности. Примерами внешних сущностей могут служить: клиенты организации, заказчики, персонал, поставщики. Внешняя сущность обозначается прямоугольником с тенью (рис. 2.15), внутри которого указывается ее имя. При этом в качестве имени рекомендуется использовать существительное в именительном падеже. Иногда внешнюю сущность называют также терминатором.
Рис. 2.15.Изображение внешней сущности на диаграмме потоков данных Процесс представляет собой совокупность операций по преобразованию входных потоков данных в выходные в соответствии с определенным алгоритмом или правилом. Хотя физически процесс может быть реализован различными способами, наиболее часто подразумевается программная реализация процесса. Процесс на диаграмме потоков данных изображается прямоугольником с закругленными вершинами (рис. 2.16), разделенным на три секции или поля горизонтальными линиями. Поле номера процесса служит для идентификации последнего. В среднем поле указывается имя процесса. В качестве имени рекомендовано использовать глагол в неопределенной форме с необходимыми дополнениями. Нижнее поле содержит указание на способ физической реализации процесса.
Рис. 2.16.Изображение процесса на диаграмме потоков данных
Рис. 2.17.Изображение подсистемы на диаграмме потоков данных Информационная модель системы строится как некоторая иерархическая схема в виде так называемой контекстной диаграммы, на которой исходная модель последовательно представляется в виде модели подсистем соответствующих процессов преобразования данных. При этом подсистема или система на контекстной диаграмме DFD изображается так же, как и процесс – прямоугольником с закругленными вершинами (рис. 2.17). Накопитель данных или хранилище представляет собой абстрактное устройство или способ хранения информации, перемещаемой между процессами. Предполагается, что данные можно в любой момент поместить в накопитель и через некоторое время извлечь, причем физические способы помещения и извлечения данных могут быть произвольными. Накопитель данных может быть физически реализован различными способами, но наиболее часто предполагается его реализация в электронном виде на магнитных носителях. Накопитель данных на диаграмме потоков данных изображается прямоугольником с двумя полями (рис. 2.18). Первое поле служит для указания номера или идентификатора накопителя, который начинается с буквы "D". Второе поле служит для указания имени. При этом в качестве имени накопителя рекомендуется использовать существительное, которое характеризует способ хранения соответствующей информации.
Рис. 2.18.Изображение накопителя на диаграмме потоков данных Наконец, поток данных определяет качественный характер информации, передаваемой через некоторое соединение от источника к приемнику. Реальный поток данных может передаваться по сети между двумя компьютерами или любым другим способом, допускающим извлечение данных и их восстановление в требуемом формате. Поток данных на диаграмме DFD изображается линией со стрелкой на одном из ее концов, при этом стрелка показывает направление потока данных. Каждый поток данных имеет свое собственное имя, отражающее его содержание. Таким образом, информационная модель системы в нотации DFD строится в виде диаграмм потоков данных, которые графически представляются с использованием соответствующей системы обозначений. В качестве примера рассмотрим упрощенную модель процесса получения некоторой суммы наличными по кредитной карточке клиентом банка. Внешними сущностями данного примера являются клиент банка и, возможно, служащий банка, который контролирует процесс обслуживания клиентов. Накопителем данных может быть база данных о состоянии счетов отдельных клиентов банка. Отдельные потоки данных отражают характер передаваемой информации, необходимой для обслуживания клиента банка. Соответствующая модель для данного примера может быть представлена в виде диаграммы потоков данных (рис. 2.19). В настоящее время диаграммы потоков данных используются в некоторых CASE-средствах для построения информационных моделей систем обработки данных. Основной недостаток этой методологии также связан с отсутствием явных средств для объектно-ориентированного представления моделей сложных систем, а также для представления сложных алгоритмов обработки данных. Поскольку на диаграммах DFD не указываются характеристики времени выполнения отдельных процессов и передачи данных между процессами, то модели систем, реализующих синхронную обработку данных, не могут быть адекватно представлены в нотации DFD. Все эти особенности методологии структурного системного анализа ограничили возможности ее широкого применения и послужили основой для включения соответствующих средств в унифицированный язык моделирования.
Рис. 2.19.Пример диаграммы DFD для процесса получения некоторой суммы наличными по кредитной карточке
2.3. Основные этапы развития UML
Отдельные языки объектно-ориентированного моделирования стали появляться в период между серединой 1970-х и концом 1980-х годов, когда различные исследователи и программисты предлагали свои подходы к ООАП. В период между 1989-1994 гг. общее число наиболее известных языков моделирования возросло с 10 до более чем 50. Многие пользователи испытывали серьезные затруднения при выборе языка ООАП, поскольку ни один из них не удовлетворял всем требованиям, предъявляемым к построению моделей сложных систем. Принятие отдельных методик и графических нотаций в качестве стандартов (IDEF0, IDEF1X) не смогло изменить сложившуюся ситуацию непримиримой конкуренции между ними в начале 90-х годов, которая тоже получила название «войны методов». К середине 1990-х некоторые из методов были существенно улучшены и приобрели самостоятельное значение при решении различных задач ООАП. Наиболее известными в этот период становятся:
• Метод Гради Буча (Grady Booch), получивший условное название Booch или Booch'91, Booch Lite (позже – Booch'93).
• Метод Джеймса Румбаха (James Rumbaugh), получивший название Object Modeling Technique – ОМТ (позже – ОМТ-2).
• Метод Айвара Джекобсона (Ivar Jacobson), получивший название Object-Oriented Software Engineering – OOSE.
Каждый из этих методов был ориентирован на поддержку отдельных этапов ООАП. Например, метод OOSE содержал средства представления вариантов использования, которые имеют существенное значение на этапе анализа требований в процессе проектирования бизнес-приложений. Метод ОМТ-2 наиболее подходил для анализа процессов обработки данных в информационных системах. Метод Booch'93 нашел наибольшее применение на этапах проектирования и разработки различных программных систем. История развития языка UML берет начало с октября 1994 года, когда Гради Буч и Джеймс Румбах из Rational Software Corporation начали работу по унификации методов Booch и ОМТ. Хотя сами по себе эти методы были достаточно популярны, совместная работа была направлена на изучение всех известных объектно-ориентированных методов с целью объединения их достоинств. При этом Г. Буч и Дж. Румбах сосредоточили усилия на полной унификации результатов своей работы. Проект так называемого унифицированного метода (Unified Method) версии 0.8 был подготовлен и опубликован в октябре 1995 года. Осенью того же года к ним присоединился А. Джекоб-сон, главный технолог из компании Objectory AB (Швеция), с целью интеграции своего метода OOSE с двумя предыдущими. Вначале авторы методов Booch, ОМТ и OOSE предполагали разработать унифицированный язык моделирования только для этих трех методик. С одной стороны, каждый из этих методов был проверен на практике и показал свою конструктивность при решении отдельных задач ООАП. Это давало основание для дальнейшей их модификации на основе устранения имеющегося несоответствия отдельных понятий и обозначений. С другой стороны, унификация семантики и нотации должна была обеспечить некоторую стабильность на рынке объектно-ориентированных CASE-средств, которая необходима для успешного продвижения соответствующих программных ин-струментариев. Наконец, совместная работа давала надежду на существенное улучшение всех трех методов. Начиная работу по унификации своих методов, Г. Буч, Дж. Румбах и А. Дже-кобсон сформулировали следующие требования к языку моделирования. Он должен:
• Позволять моделировать не только программное обеспечение, но и более широкие классы систем и бизнес-приложений, с использованием объектно-ориентированных понятий.
• Явным образом обеспечивать взаимосвязь между базовыми понятиями для моделей концептуального и физического уровней.
• Обеспечивать масштабируемость моделей, что является важной особенностью сложных многоцелевых систем.
• Быть понятен аналитикам и программистам, а также должен поддерживаться специальными инструментальными средствами, реализованными на различных компьютерных платформах.
Разработка системы обозначений или нотации для ООАП оказалась непохожей на разработку нового языка программирования. Во-первых, необходимо было решить две проблемы:
1. Должна ли данная нотация включать в себя спецификацию требований?
2. Следует ли расширять данную нотацию до уровня языка визуального программирования?
Во-вторых, было необходимо найти удачный баланс между выразительностью и простотой языка. С одной стороны, слишком простая нотация ограничивает круг потенциальных проблем, которые могут быть решены с помощью соответствующей системы обозначений. С другой стороны, слишком сложная нотация создает дополнительные трудности для ее изучения и применения аналитиками и программистами. В случае унификации существующих методов необходимо учитывать интересы специалистов, которые уже имеют опыт работы с ними, поскольку внесение серьезных изменений в новую нотацию может повлечь за собой непонимание и неприятие ее пользователями прежних методик. Чтобы исключить неявное сопротивление со стороны отдельных специалистов, необходимо учитывать интересы самого широкого круга пользователей. Последующая работа над языком UML должна была учесть все эти обстоятельства. В этот период поддержка разработки языка UML становится одной из целей консорциума OMG (Object Management Group). Хотя консорциум OMG был образован еще в 1989 году с целью разработки предложений по стандартизации объектных и компонентных технологий CORBA, язык UML приобрел статус второго стратегического направления в работе OMG. Именно в рамках OMG создается команда разработчиков под руководством Ричарда Соли, которая будет обеспечивать дальнейшую работу по унификации и стандартизации языка UML. В июне 1995 года OMG организовала совещание всех крупных специалистов и представителей входящих в консорциум компаний по методологиям ООАП, на котором впервые в международном масштабе была признана целесообразность поиска индустриальных стандартов в области языков моделирования под эгидой OMG. Усилия Г. Буча, Дж. Румбаха и А. Джекобсона привели к появлению первых документов, содержащих описание собственно языка UML версии 0.9 (июнь 1996 г.) и версии 0.91 (октябрь 1996 г.). Имевшие статус запроса предложений RTP (Request For Proposals), эти документы послужили своеобразным катализатором для широкого обсуждения языка UML различными категориями специалистов. Первые отзывы и реакция на язык UML указывали на необходимость его дополнения отдельными понятиями и конструкциями. В это же время стало ясно, что некоторые компании и организации видят в языке UML линию стратегических интересов для своего бизнеса. Компания Rational Software вместе с несколькими организациями, изъявившими желание выделить ресурсы для разработки строгого определения версии 1.0 языка UML, учредила консорциум партнеров UML, в который первоначально вошли такие компании, как Digital Equipment Corp., HP, i-Logix, Intellicorp, IBM, ICON Computing, MCI Systemhouse, Microsoft, Oracle, Rational Software, TI и Unisys. Эти компании обеспечили поддержку последующей работы по более точному и строгому определению нотации, что привело к появлению версии 1.0 языка UML. В январе 1997 года был опубликован документ с описанием языка UML 1.0, как начальный вариант ответа на запрос предложений RTP. Эта версия языка моделирования была достаточно хорошо определена, обеспечивала требуемую выразительность и мощность и предполагала решение широкого класса задач.
Инструментальные CASE-средства и диапазон их практического применения в большой степени зависят от удачного определения семантики и нотации соответствующего языка моделирования. Специфика языка UML заключается в том, что он определяет семантическую метамодель, а не модель конкретного интерфейса и способы представления или реализации компонентов. Из более чем 800 компаний и организаций, входящих в настоящее время в состав консорциума OMG, особую роль продолжает играть Rational Software Corporation, которая стояла у истоков разработки языка UML. Эта компания разработала и выпустила в продажу одно из первых инструментальных CASE-средств Rational Rose 98, в котором был реализован язык UML. В январе 1997 года целый ряд других компаний, среди которых были IBM, ObjecTime, Platinum Technology и некоторые другие, представили на рассмотрение OMG свои собственные ответы на запрос предложений RFP. В дальнейшем эти компании присоединились к партнерам UML, предлагая включить в язык UML некоторые свои идеи. В результате совместной работы с партнерами UML была предложена пересмотренная версия 1.1 языка UML. Основное внимание при разработке языка UML 1.1 было уделено достижению большей ясности семантики языка по сравнению с UML 1.0, а также учету предложений новых партнеров. Эта версия языка была представлена на рассмотрение OMG и была одобрена и принята в качестве стандарта OMG в ноябре 1997. года. В настоящее время все вопросы дальнейшей разработки языка UML сконцентрированы в рамках консорциума OMG. Соответствующая группа специалистов обеспечивает публикацию материалов, содержащих описание последующих версий языка UML и запросов предложений RFP по его стандартизации. Очередной этап развития данного языка закончился в марте 1999 года, когда консорциумом OMG было опубликовано описание языка UML 1.3 (alpha R5). Последней версией языка UML на момент написания книги является UML 1.3, которая описана в соответствующем документе – «OMG Unified Modeling Language Specification», опубликованном в июне 1999 года. История разработки и последующего развития языка UML графически представлена на рис. 2.20.
Рис. 2.20.История развития языка UML Статус языка UML определен как открытый для всех предложений по его доработке и совершенствованию. Сам язык UML не является чьей-либо собственностью и не запатентован кем-либо, хотя указанный выше документ защищен законом об авторском праве. В то же время аббревиатура UML, как и некоторые другие (OMG, CORBA, ORB), является торговой маркой их законных владельцев, о чем следует упомянуть в данном контексте. Язык UML ориентирован для применения в качестве языка моделирования различными пользователями и научными сообществами для решения широкого класса задач ООАП. Многие специалисты по методологии, организации и поставщики инструментальных средств обязались использовать язык в своих разработках. При этом термин «унифицированный» в названии UML не является случайным и имеет два аспекта. С одной стороны, он фактически устраняет многие из несущественных различий между известными ранее языками моделирования и методиками построения диаграмм. С другой стороны, создает предпосылки для унификации различных моделей и этапов их разработки для широкого класса систем, не только программного обеспечения, но и бизнес-процессов. Семантика языка UML определена таким образом, что она не является препятствием для последующих усовершенствований при появлении новых концепций моделирования. В этой связи следует отметить внимание гиганта компьютерной индустрии компании Microsoft к технологии UML. Еще в октябре 1996 г. Microsoft и Rational Software Coiporation объявили о своем стратегическом партнерстве, которое, по их общему мнению, способно оказать решающее влияние на рынок средств объектно-ориентированной разработки программ. Конец бесплатного ознакомительного фрагмента.
Страницы:
1, 2, 3, 4
|
|