 |
|
Популярные авторы:: Борхес Хорхе Луис :: Толстой Лев Николаевич :: Раззаков Федор :: Картленд Барбара :: Азимов Айзек :: Чехов Антон Павлович :: Горький Максим :: Грин Александр :: Сименон Жорж :: Завтра Газета Популярные книги:: Справочник по реестру Windows XP :: Табакерка императора :: Целестина, или Шестое чувство :: Тайна хохочущей тени :: Неучтивый церемониймейстер Котсуке-но-Суке :: Истории о Хогбенах :: Пожиратель мух :: Беспардонный лжец Том Кастро :: Сад, где ветвятся дорожки :: Валери как символ |
Компьютерра (№255) - Журнал «Компьютерра» № 10 от 14 марта 2006 годаModernLib.Net / Компьютеры / Компьютерра / Журнал «Компьютерра» № 10 от 14 марта 2006 года - Чтение (стр. 9)
К тому же страны развиваются по-разному. Германская Википедия, на мой взгляд, качественнее английской — если брать соответствующие временные срезы. Думаю, это вызвано повышенным вниманием немцев к качеству — мы согласны на «Шевроле», а они покупают «Мерседесы». Как с этим обстоит в России, не знаю, — возможно, вы больше похожи на американцев, а не на немцев. В Германии в октябре этого года начинается публикация бумажной версии Википедии. Как будет решаться проблема с копирайтами? На сайте материалы сомнительного происхождения можно довольно быстро убрать, но отредактировать бумажный вариант после выпуска уже не получится. Как немецкая Википедия собирается решать эту проблему? Там же сотни тысяч статей… — Проектом занимается компания Direct Media, и они, насколько я знаю, собираются решать эту проблему традиционными способами: наймут редакторов и проверят содержание всех статей. Понятно, что свести риск к нулю не удастся, но это нормально. Вы же сами наверняка сталкиваетесь с проблемами плагиата… Больше того, нам время от времени приходят статьи, составленные из текстов русской Википедии. — Ну вот видите. В общем, риск есть всегда. Но его можно минимизировать. Впрочем, это не наша задача — этим занимается издатель. Как это устроено Я читал статьи Ларри Сэнгера о том, с чего начиналась Википедия, но так и не смог понять, чем вы привлекали людей в самом начале. Сейчас-то понятно — это большой проект, в него можно влиться и тешить свое самолюбие, зарабатывая авторитет в сообществе. Но ведь вначале ничего этого не было. И второй вопрос — насколько большую роль в становлении Википедии сыграли участники вашего предыдущего проекта, Nupedia. — Ваш второй вопрос, на самом деле, является частичным ответом на первый. За два года до Википедии мы запустили Nupedia. В этом проекте участвовали настоящие ученые, вдохновленные идеей бесплатной, доступной для всех энциклопедии, составляемой на добровольных началах. Ведь для многих людей Интернет начинался с идеи свободного обмена информацией. Но потом началась эпоха доткомов, а Интернет стал ассоциироваться с рекламой, спамом и прочим собачьим кормом. Наш же проект возвращал людей к корням Интернета. Мы собрали хороших людей, которые решили вместе делать что-то полезное и делиться этим с другими. И этот стимул работал. Не работала социальная модель Nupedia. Вы должны были написать статью целиком, потом следовал сложнейший процесс рецензирования — в общем, все было сложно и скучно с точки зрения участников проекта. Но когда открылась Википедия, самыми активными ее участниками стали люди из Nupedia, образовавшие ядро сообщества. Кроме того, в первые месяцы работы был и дополнительный стимул. Вы могли стать первым автором статьи на интересующую вас тему. Например, статьи о России. Для этого нужно было всего лишь создать новую страничку и написать на ней, например, «Россия — это страна» и поставить точку. Несложно ведь, да? Сегодня новых тем, которые никак не освещены, осталось не так уж много. В этом смысле русская Википедия находится в более выгодном положении. Мы только что перевалили за миллион статей, и новую тему придумать не так-то просто, у вас же пока лишь 60 тысяч статей, что для такой страны явно недостаточно. Недавно мы писали о новом проекте Ларри Сэнгера — Digital Universe («КТ» #627). Из его статей и из опубликованной концепции проекта очевидно, что ему симпатична менее открытая социальная модель, чем Википедия. Как вам кажется, будет ли его проект успешен? — Я был у Ларри несколько месяцев назад. Digital Universe — очень интересная идея, и у Ларри сейчас на нее есть куча денег. Намного больше, чем у нас было или когда-нибудь будет. Думаю, успех напрямую зависит от того, удастся ли Ларри выстроить вокруг своей идеи сообщество. Тут ведь какая штука? Если сделать слишком высокий порог вхождения, то построить сообщество очень трудно. Одна из сильных сторон Википедии (и одновременно источник ее слабости) — это легкость присоединения новых участников. Мы растем очень быстро. И к нам приходит множество полезных и неожиданных людей, которые… Иногда попадаются пятнадцатилетние авторы, пишущие совершенно невероятные статьи! Конечно, без плевел тоже не обходится. Так же легко к нам приходят и «трудные» люди, и просто глупцы… В более закрытое сообщество попасть труднее. В Nupedia нужно было сначала доказать, что ты, допустим, кандидат наук. И только потом тебе, возможно, доверят редактирование какой-нибудь запятой. Конечно, высокие барьеры предохраняют сообщества от нежелательных элементов, но и хорошим людям сложнее в них попасть. Многие участники Википедии втянулись в работу незаметно. Они сделали первое небольшое изменение. Потом еще и еще. После пяти или десяти изменений они говорят себе: пожалуй, пора зарегистрироваться. То есть это очень легкий и естественный процесс. Ларри предстоит решать эту проблему. Но, насколько я понимаю, они собираются использовать наш контент, проверяя и улучшая его. Так что я думаю, Википедия и Digital Universe могут быть полезны друг другу. В проекте Ларри можно сделать работу, которую трудно осуществить в рамках социальной модели Википедии. Но выстрелит ли его Вселенная — я не знаю. Посмотрим. В разговор вступает Александр Сергеев. Меня, честно говоря, удивил вопрос Владимира, поскольку меня интересует ровно обратное. Я могу понять людей, которые с энтузиазмом работали над проектом, когда он только начинался — это было ново, это было интересно, это было приключение. Но сейчас-то это уже не приключение, а скорее работа. Какой смысл заниматься ею, если рядом с тобой тем же занимаются тысячи людей? — Вы не учитываете, что сам процесс совместного редактирования может приносить удовольствие. Для многих это хобби. Наверное, со стороны это выглядит странно — попробуйте-ка, представить себе человека, который довольно потирает руки и говорит: «Наконец-то выходные! Будет время написать парочку статей для энциклопедии!» Может быть, это и глупо, но мы же не спрашиваем, почему люди играют по выходным в футбол или смотрят матчи по ТВ. Кое-кому нравится писать вместе. Они так развлекаются. Но только некоторые области знания предполагают такое легкое отношение. Не получится ли так, что какие-то важные, но сложные для описания области человеческого знания будут фактически отсечены? — Почти для каждой области человеческого знания можно найти людей, которые ею увлечены. Мне, например, смертельно скучной кажется математическая статистика… Постойте, как же вы торговали фьючерсами? — Так и торговал. Это был тяжелый труд. Все эти стохастические распределения… Не могу себе представить, чтобы делал это для собственного удовольствия. Но некоторые считают иначе. И у нас есть просто фантастические статьи на эти темы. В то же время у нас есть разделы, которые развиты хуже других, — ведь мы интернет-энциклопедия, что накладывает определенный отпечаток. Компьютерные статьи у нас в порядке, а вот, допустим, китайская поэзия — пока не очень. То есть некий дисбаланс, конечно, имеет место. Но я не думаю, что это критично. Если предположить, что есть тема — я не уверен в этом, но готов пойти на такое допущение, — о которой никто не хочет писать, то скорее всего и читать о ней никто не хочет. Так что отсутствие подобной информации, наверное, можно пережить. Вообще говоря, это интересный вопрос, но мы никак не можем оценить уровень отсутствующей информации. Если сравнивать нас с Британникой или Брокгаузом, то по широте обхвата мы их уже обошли, и я не могу сходу назвать какую-то область человеческого знания, которой мы совсем не касались. Кому выгодно То есть вы не планируете платить за написание статей, за которые никто не берется добровольно? — Нет. Мы не исключаем платежи, но другого рода. Я недавно был в Индии и обсуждал там проблемы хинди-Википедии. Она плохо развивается. Во многом потому, что все образованные индийцы — даже если дома они говорят на хинди — знают английский, используют английский на работе и набирают тексты с помощью английской клавиатуры. А набирать тексты на хинди на английской клавиатуре — сложно. И здесь мы можем, наверное, приобрести какие-нибудь плагины или хинди-клавиатуры. Вы планировали оплачивать работу региональных координаторов в медленно развивающихся странах. Это не может быть опасно для сообщества в целом? — Ох, мы бы с удовольствием платили всем, но мы маленькая некоммерческая организация и просто не можем себе этого позволить. Поэтому если мы будем платить, то лишь тем, кто занимается развитием отстающих Википедий — хинди, арабские языки, суахили. Нам нужно как-то запустить этот процесс. Возможно, некая система поощрений ободрит людей и позволит нам, так сказать, ввести мяч в игру. Это не вызовет конфликтов? Ведь большинство координаторов будет выполнять ровно ту же работу совершенно бесплатно. — Не исключено. Трудный вопрос. Но я думаю, что сообщество в целом отнесется к этому с пониманием. Википедия — всемирный благотворительный проект, и если мы нашли способ для ее продвижения в каких-то регионах, полагаю, это будет одобрено. Но, конечно, риск существует. В настоящее время Википедия финансируется за счет добровольных пожертвований, но уже год или два постоянно идут разговоры о рекламных блоках на страницах энциклопедии. Как вы к этому относитесь и может ли сложиться ситуация, когда это будет необходимо? — Не думаю, что реклама когда-нибудь станет необходимостью. У нас хватает денег на серверы, а участники работают на общественных началах. Вопрос, который стоит перед сообществом, другой: дополнительная прибыль от рекламы позволит нам развиваться быстрее. Но к этому нужно подходить осторожно. Лично я против введения рекламы. Думаю, есть и другие модели (например, те же бумажные публикации), позволяющие получить дополнительные средства. Но решать буду не я. Решать будет сообщество. Как вы относитесь к тому, что некоторые сайты используют контент Википедии и зарабатывают на показе рекламы, не отчисляя вам ни гроша (в отличие от Answers.com)? — Наш контент выпущен под свободной лицензией. Так что если люди берут наш контент, вставляют в него рекламу и зарабатывают на этом — ну что ж, формально у них есть такое право. С другой стороны, гораздо лучше и правильнее поступать так, как делает Answers.com, — они зарабатывают на нашем контенте, но часть заработков отдают нам, на дальнейшее развитие проекта. Помимо Википедии Ваша компания Wikia, зарабатывающая показом рекламы на страницах вики-сообществ, начинала с разработки поискового движка. Что пошло не так? Почему от изначальной идеи вы отказались? — Ну, это моя старая задумка — наложить модель Википедии на открытый каталог сетевых ресурсов типа dmoz.org, который тоже создается на добровольных началах. Проблема с dmoz.org в том, что это очень закрытое сообщество, а потому оно растет медленно и не может занять подобающее место в структуре Интернета. И, создавая Wikia, я пытался изобрести что-нибудь новое, совместив принципы свободного редактирования с поисковиками или каталогами веб-ресурсов. Это очень сложная задача, которую я так и не решил. В какой-то момент стало понятно, что лучше все-таки делать то, что умеешь. Поэтому мы поменяли акценты, превратив Wikia из поисковика в компанию, предоставляющую бесплатный хостинг под wiki-проекты. А как вы относитесь к wiki-поисковикам — websbiggest.com или qwika.com например? — Я довольно давно не заходил на websbiggest.com. Не знаю, насколько хорошо он работает. Но рассуждая абстрактно, совместное написание текста — труднейшая штука, но мы уже умеем это делать и знаем, как справляться с трудностями. У сообществ, построенных вокруг поисковиков, две проблемы. Первая — спам. Им ведь будут заниматься не только профессиональные спамеры, но и обычные люди, у которых есть сайт и которые просто хотят поднять его популярность. С этим очень трудно справиться. Вторая проблема заключается в следующем. Многим людям нравится совместно редактировать статьи. Это интересно само по себе. Это может стать интеллектуальной привычкой. А вот добавление ссылок в каталог, на мой вкус, — не слишком интересное занятие. Не знаю, как от него можно получать удовольствие. Если ребятам с websbiggest.com это удалось — мои поздравления. Теперь о qwika.com. Я немножко поигрался с этим поисковиком. Ну что сказать? Очень мило. Не знаю, насколько он нужен — многих ли не устраивает поиск в Википедии, где можно использовать не только родной движок, но и Google? Но, повторюсь, это интересный проект. Если не Википедия, то что? Давайте представим, что Википедию создал кто-то другой. Каким проектом вы бы хотели заняться после ухода из Bornis? — Flickr. Очень интересный проект. Простой и очевидный, но — пришедший в голову не мне. Я знаю основателей компании и даже как-то посетовал, что это не моя идея. На самом деле, Flickr был изобретен случайно. Вначале это была онлайновая игра, в рамках которой пользователям позволили загружать фотографии и ставить теги. В какой-то момент стало очевидно, что в саму игру уже никто не играет, тогда как дополнительный сервис пользуется большой популярностью. Они переименовались и превратились во Flickr. Кстати, вы можете представить, что лет через пять вам надоест заниматься Википедией и вы покинете проект? И наоборот — сможет ли проект развиваться без сильного лидера? — Мне это так интересно, что я не могу себе представить подобной ситуации. До сих пор не устаю удивляться, что еще два года назад я сидел дома в пижаме и работал за ноутбуком, а теперь, как видите, приехал в Москву и даю интервью. А сообщество, конечно, может развиваться и без меня. Более того, мы сейчас пытаемся уйти от модели «просвещенной тирании», которая перешла к нам по наследству от открытого софта. Для молодых проектов такая модель может быть полезна, потому что зачастую лучше хоть какое-нибудь решение, чем вообще ничего. Должен быть человек, чье слово ставит точку в любом споре. Но сейчас Википедия очень выросла, у нас множество неанглоговорящих участников, и я уже не вмешиваюсь напрямую в работу национальных Википедий, доверяя управление региональным координаторам. Вот взять китайскую версию — как я могу вмешиваться в их работу? Разве китайская версия не заблокирована китайскими властями? — Заблокирована… Но относительно недавно. Мы даже удивились, что они так долго с этим тянули. Может быть, имеет смысл не касаться некоторых тем в китайской версии? Ввести цензуру, как сделали крупные поисковики? — Китайские власти не пытались с нами договориться… Но, в любом случае, такая договоренность крайне маловероятна. Меня, честно говоря, очень беспокоит то, что делают в этом смысле Google, Yahoo или Microsoft. Даже если они верят, что поступают правильно (Google, например, говорит, что жизненно важно предоставить китайцам доступ к информации, поэтому, видимо, можно пойти на некоторые уступки), мы-то с вами знаем, что Китай — это огромный рынок. И у очень многих компаний появляется соблазн сказать, что, мол, мы делаем это лишь для того, чтобы помочь народу Китая. Но мы не коммерческая организация. И не приемлем никакой цензуры. У нас есть определенные ограничения, мы порой блокируем статьи от изменений, но не подстраиваем их содержание под чьи-то желания. Мы нейтральны. Поэтому, наверное, могли бы подчистить и заблокировать от немедленных изменений такие статьи, как статья о площади Тяньаньмэнь, или страничку о фаньлунгун. Но, опять же, это решение должен принимать не Китай, не Джимми Уэйлс, а сами участники сообщества Википедии. Думаю, что в долговременном смысле такой подход более перспективен. На нашей с вами памяти произошли невероятные изменения в России. И я не уверен, что это хорошая идея для, скажем, Google — ставить под удар свою репутацию ради достижения краткосрочных целей. Когда-нибудь в Китае все изменится, и китайцы вспомнят, кто помогал цензорам. Хорошо информированный оптимист Да, у него есть Ferrari, но ездит он на Hyundai, потому что Hyundai — в отличие от Ferrari — заводится. Да, пока Википедия не может гарантировать качество выдаваемой информации, но со временем «проверенные» статьи будут маркироваться как «стабильные», и у посетителя будет выбор — читать самый последний или не столь свежий, но проверенный вариант. Да, морально прошлый год был довольно тяжелым, потому что пресса с удовольствием муссировала любой скандал, связанный с Википедией, но даже негативные публикации шли проекту на пользу. Джимми — из тех хорошо информированных оптимистов, которые не стали пессимистами. Правда, в будущее он смотрит не столько с уверенностью, сколько с интересом: — Я могу легко предсказать будущее русской Википедии, потому что английская уже прошла все эти стадии развития. Я знаю, что бывает, когда у вас триста или пятьсот тысяч статей. Но предсказать будущее английской Википедии гораздо труднее. С нынешними темпами роста в следующем марте у нас будет два миллиона статей, а еще через год — четыре миллиона. И я даже представить не могу, на что это будет похоже. ТЕХНОЛОГИИ: Ориентация на язык Автор: Дмитрий Кириллов Одну из самых актуальных, наболевших и, не побоюсь этого слова, фундаментальных проблем разработки можно кратко назвать так: «проект программы не равен ее исходному коду». Впечатляющий набор современных инструментов для анализа, проектирования, рефакторинга и реинжиниринга предназначен, по сути, для сокращения разрыва между проектом системы и ее реализацией в исходном коде. Так как же сохранить качественный программный проект в условиях постоянно меняющихся требований заказчика? Статья, предлагаемая вашему вниманию, посвящена одному из потенциальных решений, которое способно существенно повлиять на сложившуюся практику разработки. Об авторе Лидер группы разработки в компании Nicotech International. В область профессиональных и академических интересов входят организация управления проектами, архитектура программного обеспечения, теория формальных языков, технологии порождающего программирования. В качестве вступления следует отметить, что современные методы разработки программного обеспечения позволяют достаточно четко отделить бизнес-требования к системе от программной архитектуры, а уж тем более — от исходного кода реализации... но лишь на ранних стадиях разработки. При этом серьезное изменение проекта на поздних стадиях может стать тем самым «дятлом, залетевшим в форточку и разрушившим цивилизацию». Для того чтобы этого не произошло, опытные разработчики и архитекторы рекомендуют: пользуйтесь шаблонами проектирования (при этом снижаются риски, связанные с неудачным выбором архитектуры); периодически проводите ревизии проекта (забавно, что при этом зачастую происходит документирование поведения системы «пост-фактум»); делайте архитектуру многослойной с минимальной зависимостью между слоями; прототипируйте, выпуская сборки как можно чаще (золотое правило экстремального программирования); определяйте возможные направления будущих изменений проекта (это уже из области технологий «третьего глаза»). Этот список можно продолжать бесконечно, однако и так понятно, что подобные рекомендации позволяют лишь снизить риски, обусловленные расхождением проекта и исходного кода. Корень же всех зол кроется в том, что высокоуровневые аспекты проекта выражаются и документируются в терминах естественного языка (каким является, например, русский или английский), тогда как код реализации пишется на каком-нибудь формальном языке (C++, Java, C#). И между двумя этими типами языков лежит целая пропасть. Языки предметной области Решение проблемы напрашивается само собой: может, сразу излагать бизнес-требования на формальном языке? Или хотя бы не бизнес-требования (это мы сильно замахнулись), а высокоуровневые абстракции предметной области, из которых и состоит проект системы? Да вот только где бы найти подходящий язык! Очевидно, что универсальные языки программирования для этой цели непригодны: в описании функций системы никогда не встречаются термины наподобие «класс» или «виртуальный метод». Диаграммы UML тоже хороши только в качестве красивых иллюстраций к техническому проекту системы[Справедливости ради нужно отметить, что диаграммы классов и взаимодействия могут быть полезны и на этапе реализации, но они опять-таки не содержат «правильных» абстракций]. Еще несколько лет назад казалось, что с этой ролью справится XML, однако сейчас понятно, что подобные проблемы ему не по зубам (более подробно по этому поводу см. врезку «XML и XSLT»). Вывод: подобные языки нужно создавать. Причем нужно создавать свой, особенный набор языков для каждого типа проектируемых систем, поскольку абстракции, на которых основана какая-нибудь бухгалтерская программа, сильно отличаются от абстракций системы по сбору данных для аналитической отчетности. Для таких языков даже существует устоявшийся термин — DSL (Domain-Specific Language, специализированный язык предметной области), — которым мы и будем пользоваться в дальнейшем. Идея языков предметной области стара как мир. Макросы, языки командных оболочек (shell-скрипты Unix, например), проблемно-ориентированные языки приложений (такие как встроенный язык известной в России системы «1С»), языки пользовательских интерфейсов (например, XUL, широко известный в сообществе Mozilla), даже «великий и могучий» SQL для работы с базами данных, — все вышеперечисленные языки относятся к категории DSL, поскольку каждый из них проектировался для своей предметной области. Вместе с тем, за редкими исключениями, DSL не используются в качестве средства разработки программных приложений. А ведь как было бы здорово: разработать DSL и записать на нем код проекта… «Создавать языки под каждый конкретный проект? Вздор!» — скажет вам любой специалист, хорошо знающий, как дорого обходится проектирование формальных языков с нуля. Действительно, при классической схеме разработки любого языка нужно написать много кода для распознавания исходных текстов на этом языке и их погружения в объектную модель, пригодную для дальнейших манипуляций. Кроме того, даже при условии, что эта работа проделана, возникает ряд вопросов. Как отображать и редактировать программы на таком языке? Понятно, что в век высоких скоростей и мощных сред разработки ограничиться простым текстовым редактором a-la «Блокнот» уже не получится: представления о производительности труда разработчика ныне совсем не те, что в «далекие» 90-е годы XX века. Какова стоимость внесения изменений в разработанный язык? Если для того, чтобы изменить какое-то понятие предметной области, нужно «перекроить» весь код распознавателя, выгода от использования такого подхода равна нулю. И главное: предположим, объектная модель получена. Что делать дальше? Ведь модель еще нужно связать с языком реализации системы, что является отдельной головной болью. Языковые инструментарии Перечисленные выше вопросы давно волнуют как сообщество разработчиков, так и компании, занимающиеся выпуском средств разработки, поскольку сама по себе идея DSL очень заманчива. Тем не менее по ряду причин комплексное решение вышеуказанных проблем могло появиться лишь совсем недавно. Речь идет о новом типе программного обеспечения — так называемых языковых инструментариях (language workbenches), которые являются полноценными средами разработки, специально заточенными под DSL. И хотя существуют пока лишь прототипы таких систем, совершенно непригодные для использования в реальных проектах, главные особенности языковых инструментариев можно наглядно продемонстрировать уже сейчас. Из разработок в этой области хотелось бы упомянуть два перспективных проекта. Первым из них является Meta Programming System компании JetBrains. Система MPS ориентирована на совместное использование с фирменной IDE компании — средой разработки Java-приложений IntelliJ IDEA, которой автор уже восхищался в статье «Кодируй да радуйся» («КТ» #562). Другой проект, Software Factories, принадлежит перу софтверного гиганта Microsoft и выступает в качестве дополнения к недавно вышедшей Visual Studio 2005[Meta Programming System можно свободно скачать по адресу jetbrains.com/mps. Проект Software Factories в настоящий момент представляет собой набор инструментов DSL Tools, доступных для скачивания в составе SDK к Visual Studio 2005. Подробности можно узнать здесь: msdn.microsoft.com/vstudio/teamsystem/workshop/sf]. Ну что ж, покончив с продолжительным введением, перейдем к самому интересному: технологии разработки программ в окружении языковых инструментариев. Что такое метапрограмма? Грубо говоря, метапрограмма — это программа, формирующая в результате своей работы другую программу. Сложно? Тем не менее все это интуитивно понятно человеку, хоть раз занимавшемуся разработкой динамических серверных страниц. Действительно, для веб-дизайнера HTML является «программой для браузера», а для веб-разработчика тот же HTML выступает в роли данных, которые нужно сформировать в результате работы некоторого серверного кода. Следует отметить важную особенность метапрограммирования: любая метапрограмма определяет не одну конкретную программу, а целый класс. Ниже приведен пример метапрограммы, которая определяет класс всех документов HTML, содержащих произвольное число параграфов. Текст метапрограммы (ASP.NET, С#) заключен между специальными операторами <%...%> и <%=...%>.
<%foreach(Paragraph p in Document) {%>
<%=p.Content%> <%}%>
Проектирование DSL Создание языка предметной области начинается с этапа моделирования данных — той информации, которая будет впоследствии записана в терминах DSL. Для простоты предположим, что нам необходимо разработать DSL, на котором можно описать структуру статьи для журнала «Компьютерра». Предметная область этой задачи включает в себя понятия статья, раздел и подраздел[Понятие «подраздел», конечно же, является избыточным, но кому нужны эти скучные профессиональные детали?]. Для статьи характерны название, автор и некоторая структура, включающая в себя разделы статьи. Проиллюстрируем вышесказанное диаграммой (см. рис. 1), описывающей модель данных нашего DSL, который условно назовем «Структура статьи в КТ». 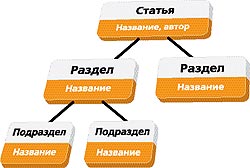 Следующий этап проектирования состоит в том, чтобы внести разработанную нами модель данных в языковой инструментарий. При этом для каждого понятия предметной области необходимо создать соответствующую концепцию языка. Например, концепция «статья» выглядит в MPS так, как изображено на рис. 2. На этом проектирование нашего языка можно считать завершенным. 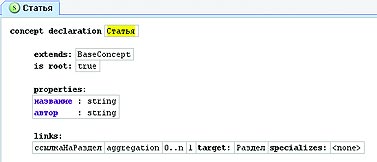 Кто-нибудь может возразить: язык — это в первую очередь знаковая система, а то, что мы только что создали, является скорее некоторой объектной моделью. Действительно, мы разработали только часть языка, традиционно называемую абстрактным синтаксисом. Если так можно выразиться, «знаковой системой» DSL в контексте языковых инструментариев являются редакторы, обеспечивающие визуальное отображение понятий языка. Создание редактора Разработка редактора для DSL — занятие еще более увлекательное, нежели проектирование самого DSL, поскольку тут гораздо более широкое поле для творчества. 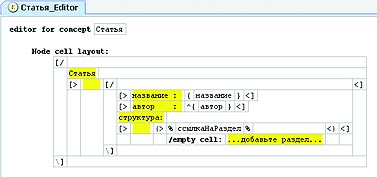 MPS обладает встроенным дизайнером для создания редакторов DSL, основанном на идее вложенных ячеек. Поясним эту идею на примере редактора для концепции «статья». На рис. 3 ячейка-контейнер верхнего уровня содержит две дочерние ячейки, расположенные вертикально. Верхняя ячейка содержит константное слово «статья», а нижняя является горизонтальным контейнером для других ячеек. И так далее. 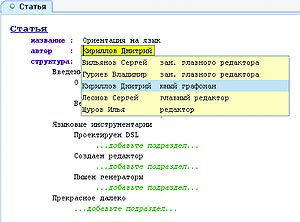 После определения «раскладки» составных частей остается связать с редактором атрибуты «название» и «автор», дополнить его возможностью выбора автора из списка, и получится нечто, изображенное на рис. 4. Процесс редактирования документов при помощи такого редактора очень прост и вполне удобен (хотя и слегка непривычен). Например, для добавления подраздела необходимо перейти в ячейку «…добавьте подраздел…» и начать ввод текста. После нажатия клавиши Enter фокус ввода переместится на следующий подраздел. Генераторы синтаксических анализаторов К автоматизации процесса разработки DSL можно подходить с различных сторон. Классический путь, существовавший задолго до появления языковых инструментариев, заключается в создании грамматики DSL, пригодной для обработки специальными программами — генераторами синтаксических анализаторов. Генератор синтаксических анализаторов (ГСА) — это утилита, на вход которой поступает файл с описанием правил грамматики некоторого языка, называемого целевым. В результате работы генератор формирует исходные тексты на C++ (или, допустим, Java), содержащие код для обработки конструкций целевого языка и, возможно, для формирования объектной модели. Написание собственного ГСА «с изюминкой» долгое время являлось престижной академической работой в области computer science, поэтому число подобных инструментов сегодня исчисляется десятками. Этот факт даже получил отражение в названиях многих ГСА: «еще один компилятор компиляторов» (yacc), «еще один инструмент для распознавания языков» (ANTLR) и т. п. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
|||||||||