Программист-прагматик. Путь от подмастерья к мастеру
ModernLib.Net / Компьютеры / Хант Эндрю / Программист-прагматик. Путь от подмастерья к мастеру - Чтение
(стр. 12)
|
Автор:
|
Хант Эндрю |
|
Жанр:
|
Компьютеры |
|
-
Читать книгу полностью
(648 Кб)
- Скачать в формате fb2
(537 Кб)
- Скачать в формате doc
(244 Кб)
- Скачать в формате txt
(230 Кб)
- Скачать в формате html
(545 Кб)
- Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22
|
|
Восьмой закон Леви
Подробности смешивают все в нашей первоначальной программе – особенно если эти подробности часто меняются. Каждый раз, когда нам приходится входить в программу и вносить в нее изменения для того, чтобы привести ее в соответствие с изменившейся бизнес-логикой, законодательством или вкусами руководства, мы рискуем нарушить систему, т. е. внести в нее новый дефект.
Поэтому мы говорим: "Долой подробности!". Уберите их из программы. В этом случае мы можем сделать нашу программу гибкой при настройке и легко адаптирующейся к изменениям.
Динамическая конфигурация
Прежде всего мы хотим сделать системы гибкими при настройке. Это касается не только цвета экрана и текста, но и более глубоких вещей, таких как выбор алгоритмов, программ баз данных, технологии связующего программного обеспечения и стиля пользовательского интерфейса. Эти пункты должны реализовываться в виде вариантов конфигурации, а не за счет интеграции или технологии.
Подсказка 37: Осуществляйте настройку, а не интеграцию
Используйте метаданные для спецификации вариантов настройки приложения: подгонки параметров, глобальных параметров пользователя, каталога, в который производится установка приложения, и т. д. Так что же такое метаданные? Строго говоря, метаданные – это данные о данных. Наиболее распространенным примером, вероятно, является схема базы данных или словарь данных. Схема содержит данные, которые описывают поля (столбцы) в терминах имен, длины и других атрибутов. Вы должны иметь возможность доступа к этой информации и ее обработки так, как если бы это были любые другие данные в этой базе. Мы используем этот термин в самом широком смысле. Метаданные – это любые данные, которые описывают приложение – как оно выполняется, какие ресурсы обязано использовать и т. д. Обычно доступ к данным и их использование осуществляется на этапе выполнения, а не компиляции. Вы используете метаданные все время, по крайней мере, это делают ваши программы. Предположим, вы щелкаете мышью для того, чтобы скрыть панель инструментов в интернет-браузере. Браузер будет сохранять эти глобальные параметры как метаданные в своего рода внутренней базе данных. Эта база данных может быть сформирована в собственном формате или может воспользоваться стандартным механизмом. При работе в операционной системе Windows таким механизмом является либо файл инициализации (используется суффикс .ini), либо записи в системном реестре. При работе с Unix подобная функциональная возможность обеспечивается системой X Window с помощью файлов Application Default. Java использует файлы Property. Во всех этих средах для извлечения значения вы указываете ключ. В других, более мощных и гибких реализациях метаданных используется встроенный язык сценариев (см. "Языки, отражающие специфику предметной области"). При реализации этих глобальных параметров в браузере Netscape фактически использованы обе эти технологии. В версии 3 параметры сохранялись в виде пар "ключ-значение":
SHOWTOOLBAR: False
В версии 4 параметры больше напоминали JavaScript:
user_pref("custtoolbar.Browser.Navigation_Toolbar.open", false);
Приложения, управляемые метаданными
Но мы хотим большего, нежели использовать метаданные для простых глобальных параметров. Мы хотим настраивать и управлять приложением через метаданные – насколько это возможно. Наша цель – думать описательно (обозначая, что должно быть сделано, а не как это должно быть сделано) и создавать высокодинамичные и адаптируемые программы. Это можно сделать, придерживаясь общего правила: программировать для общего случая и помещать всю специфику в другое место – за пределы компилируемого ядра программы.
Подсказка 38: Помещайте абстракции в текст программы, а подробности – в область метаданных
Этот подход характеризуется несколькими преимуществами: • Он вынуждает вас делать конструкцию несвязанной, что приводит к созданию более гибкой и адаптируемой программы. • Он заставляет вас создавать более устойчивую, абстрактную конструкцию за счет отнесения подробностей, выводя все подробности за пределы программы. • Вы можете настроить приложение, не прибегая к его перекомпиляции. Вы также можете использовать этот уровень настройки для обеспечения обходных путей при критических дефектах систем, находящихся в эксплуатации. • Метаданные могут быть выражены способом, который находится намного ближе к предметной области, по сравнению с универсальным языком программирования (см. "Языки, отражающие специфику конкретной области"). • Вы даже сможете реализовывать несколько различных проектов, используя то же самое ядро приложения, но с различными метаданными. Как правило, нам хочется отложить определение большинства подробностей на последний момент и оставить их как можно менее сложными для изменения. Создавая решение, позволяющее нам вносить изменения быстро, мы можем лучше справляться с потоком направленных сдвигов, которые погубили многие проекты (см. "Обратимость"). Бизнес-логика Итак, мы выбрали механизм базы данных в качестве опции настройки и предусмотрели метаданные для определения стиля пользовательского интерфейса. Можем ли мы сделать большее? Несомненно. Поскольку стратегия и бизнес-правила подвергнутся изменениям скорее, нежели любые другие аспекты проекта, есть смысл поддерживать их в очень гибком формате. Например, приложение, автоматизирующее процесс закупок, может включать в себя различные корпоративные стратегии. Может быть, вы производите оплату небольшим фирмам-поставщикам через 45 дней, а большим – через 90 дней. Сделайте настраиваемыми определения типов поставщиков, а также самих периодов времени. Используйте возможность обобщения. Возможно, вы создаете систему с ужасающими требованиями к последовательности операций. Действия начинаются и заканчиваются согласно сложным (и изменяющимся) бизнес-правилам. Подумайте об их реализации в виде некой системы на основе правил (или экспертной системы), встроенных в ваше приложение. Тем самым вы осуществите его настройку за счет написания правил, а не программы. Менее сложная логика может быть выражена при помощи мини-языка, что делает необязательным повторную компиляцию и развертывание при изменении среды. Пример приведен в разделе "Языки, отражающие специфику предметной области". Когда осуществлять настройку Как было упомянуто в разделе "Преимущество простого текста", рекомендуется представлять метаданные о настройке в формате простого текста – это делает жизнь проще. Но когда программа должна осуществлять считывание этой настройки? Многие программы осуществляют просмотр только при неудачном запуске. Если вам необходимо изменить настройку, это вынуждает вас перезапускать приложение. Более гибким подходом является написание программ, которые могут перезагружать свои настройки во время выполнения. Но эта гибкость обходится недешево: она более сложна в реализации. Рассмотрим, как будет использоваться приложение: если это продолжительный серверный процесс, то вам понадобится некий механизм для повторного считывания и применения метаданных в ходе выполнения программы. Для небольшого клиентского приложения с графическим интерфейсом, которое перезапускается достаточно быстро, это может и не понадобиться. Данное явление не ограничивается прикладными программами. Все мы раздражаемся, если операционные системы заставляют нас проводить перезагрузку при установке простых приложений или изменении совершенно безвредного параметра. Пример: пакет Enterprise Java Beans Пакет EJB (Enterprise Java Beans) является интегрированной средой, предназначенной для упрощения программирования в распределенной среде, основанной на транзакциях. Этот пакет упоминается в связи с тем, что он иллюстрирует использование метаданных для настройки приложений и упрощения процедуры написания программы. Предположим, что вы хотите создать некоторую программу на языке Java, которая будет принимать участие в транзакциях на различных машинах, с базами данных от различных производителей и с разными моделями потоков и распределения нагрузки. Хорошая новость: вам не нужно беспокоиться обо всем этом. Вы пишете так называемый bean-элемент – отдельный объект, который следует определенным соглашениям, и помещаете его в контейнер bean-элементов, управляющий многими низкоуровневыми средствами от вашего имени. Вы можете писать программу для bean-элемента, не включая какие-либо транзакционные операции или управление потоками; пакет EJB использует метаданные для указания способа обработки транзакций. Назначение потока и распределение нагрузки указываются как метаданные для основной службы транзакций, используемой контейнером. Это разделение допускает большую гибкость при динамической настройке среды во время работы. Контейнер bean-элемента может управлять транзакциями от имени bean-элемента одним из нескольких различных способов (включая вариант управления собственными обновлениями и отменой транзакций). Все параметры, воздействующие на поведение bean-элемента, указаны в описателе развертывания последнего – объекте, преобразованном в последовательную форму и содержащем нужные метаданные. Распределенные системы, подобные EJB, прокладывают путь в новый мир – мир настраиваемых, динамичных систем. Совместная настройка Выше уже говорилось о пользователях и разработчиках, настраивающих динамические приложения. Но что происходит, если вы позволяете приложениям настраивать друг друга? Речь идет о программах, которые адаптируются к операционной среде. Незапланированная, импровизированная настройка существующего программного обеспечения является мощной концепцией. Операционные системы уже способны подстраивать себя при загрузке под аппаратное обеспечение, a web-браузеры автоматически обновляются, инсталлируя новые компоненты. Большие приложения, с которыми вы работаете, имеют проблемы с управлением различными версиями данных и различными версиями библиотек и операционных систем. Возможно, здесь будет полезен более динамичный подход. Не пишите нежизнеспособных программ В отсутствие метаданных ваша программа не является столь адаптируемой или гибкой, какой она могла бы стать в противном случае. Плохо ли это? В реальном мире виды, которые не могут адаптироваться, умирают. Птицы додо не смогли приспособиться к присутствию людей и домашних животных на острове Маврикий и быстро вымерли
. Это было первое документально подтвержденное исчезновение вида от рук человека. Не дайте вашему проекту (или карьере) повторить судьбу птицы додо. Другие разделы, относящиеся к данной теме: • Ортогональность • Обратимость • Языки, отражающие специфику предметной области • Преимущества простого текста Вопросы для обсуждения • Работая над текущим проектом, подумайте о следующем: какая часть программы может быть убрана из нее и перемещена в область метаданных. Как в итоге будет выглядеть «ядро» программы? Сможете ли вы повторно использовать это ядро в контексте иного приложения? Упражнения 28. Что из нижеследующего лучше представить в виде фрагмента программы, а что вывести за ее пределы в область метаданных? 1. Назначения коммуникационных портов 2. Поддержка выделения синтаксиса различных языков в программе редактирования 3. Поддержка редактора для различных графических устройств 4. Конечный автомат для программы синтаксического анализа или сканера 5. Типовые значения и результаты, используемые в тестировании модулей
28
Временное связывание
Временное связывание – о чем это? – спросите вы. Это – о времени.
Время – аспект, который часто игнорируется в архитектуре программного обеспечения. Единственный временной параметр, который занимает наш ум – это время выполнения проекта, время, оставшееся до отправки продукта заказчику, но здесь разговор не об этом, а о роли временного фактора как элемента проектирования самого программного обеспечения. Существует два временных аспекта, представляющих для нас важность: параллелизм (события, происходящие в одно и то же время) и упорядочивание (относительное положение событий во времени).
Обычно мы не приступаем к программированию, держа в голове тот или иной аспект. Когда люди садятся за проектирование, разработку архитектуры или написание программы, события стремятся к линейности. Это и есть способ мышления большинства людей – сначала сделать «это», а потом всегда сделать «то». Но этот способ мышления приводит к связыванию во времени. Метод А всегда вызывается перед методом В; одновременно должен формироваться только один отчет; необходимо подождать перерисовки экрана до получения отклика на щелчок мыши. «Тик» обязан происходить раньше, чем "так".
Этот подход не отличается большой гибкостью и реализмом.
Нам приходится учитывать параллелизм
и думать о несвязанности любых временных или упорядоченных зависимостей. При этом мы выигрываем в гибкости и уменьшаем любые зависимости, основанные на времени во многих областях разработки: анализе последовательности операций, архитектуре, проектировании и развертывании.
Последовательность операций
При работе над многими проектами, нам приходится моделировать и анализировать последовательности операций пользователей, что является частью анализа требований. Мы хотели бы выяснить, что может происходить одновременно, а что – в строгой последовательности. Одним из способов осуществить задуманное является создание диаграммы последовательностей, с помощью системы обозначений наподобие языка UML (унифицированного языка моделирования)
. Диаграмма состоит из совокупности действий, изображенных в виде прямоугольников с закругленными уголками. Стрелка, выходящая из одной операции, идет либо к другой операции (которая может начаться после того, как первая закончится) либо к жирной линии, называемой полосой синхронизации. Как только все операции, направленные к полосе синхронизации, завершаются, можно перемещаться по стрелкам, идущим от полосы синхронизации. Операция, на которую не указывают никакие стрелки, может быть начата в любой момент. Вы можете использовать диаграммы, чтобы добиться максимального параллелизма, определив те процессы, которые могли бы осуществляться параллельно, но не осуществляются.
Подсказка 39: Анализируйте последовательность операций для увеличения параллелизма
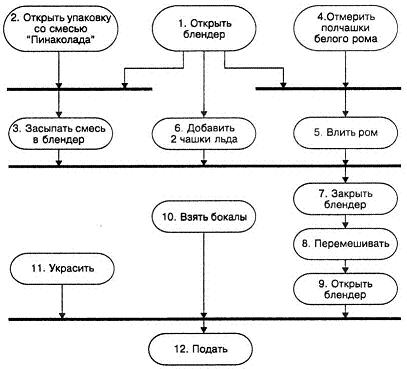
Например, в проекте блендера для коктейлей (упражнение 17) пользователи могут вначале описать последовательность операций следующим образом: 1. Открыть блендер 2. Открыть упаковку со смесью "Пинаколада" 3. Засыпать смесь в блендер 4. Отмерить полчашки белого рома 5. Влить ром 6. Добавить 2 чашки льда 7. Закрыть блендер 8. Перемешивать в течение 2 мин 9. Открыть блендер 10. Взять бокалы 11. Украсить 12. Налить Хотя они описывают эти операции последовательно (и даже могут выполнять их последовательно), заметим, что многие из них могли бы выполняться параллельно, как показано на блок-схеме (см. рис. 5.2). Это может открыть вам глаза на реально существующие зависимости. В этом случае задачи высшего уровня приоритета (1, 2, 4, 10 и 11) могут выполняться параллельно, как бы авансом. Задачи 3, 5 и 6 могут выполняться параллельно, но позже. Если бы вы участвовали в конкурсе по приготовлению коктейлей «Пинаколада», эти оптимальные решения выгодно отличали бы вас от всех остальных.
Рис. 5.2. Диаграмма на языке UML: приготовление коктейля "Пинаколада"
Архитектура
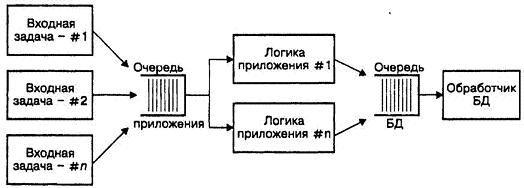
Несколько лет назад мы написали систему оперативной обработки транзакций (OLAP – on-line transaction processing). В простейшем варианте все, что должна была сделать система, – это принять запрос и обработать транзакцию в сравнении с БД. Но мы написали трехзвенное, многопроцессорное распределенное приложение: каждый компонент представлял собой независимую единицу, которая выполнялась параллельно со всеми другими компонентами. Хотя при этом возникает впечатление большой работы, это не так: при написании этого приложения мы использовали преимущество временной несвязанности. Рассмотрим этот проект более подробно. Система принимает запросы от большого числа каналов передачи данных и обрабатывает транзакции в рамках БД. Проект налагает следующие ограничения: • Операции с БД занимают сравнительно большое время. • При каждой транзакции мы не должны блокировать коммуникационные службы в момент обработки транзакции БД. • Производительность базы ухудшается за счет слишком большого числа параллельных сеансов. • Множественные транзакции осуществляются параллельно на каждой линии передачи данных. Решение, обеспечивающее наилучшую производительность и самый четкий интерфейс, выглядит подобно представленному на рисунке 5.3.
РИС. 5.3. Общая схема архитектуры системы оперативной обработки транзакций
Каждый прямоугольник обозначает отдельный процесс; процессы связываются через очереди работ. Каждый входной процесс отслеживает состояние одного входного канала связи и осуществляет запросы к серверу приложения. Все запросы являются асинхронными: как только входной процесс осуществляет текущий запрос, он сразу же возвращается к отслеживанию канала на наличие трафика. Точно так же сервер приложения осуществляет запросы процесса БД
и уведомляется в момент завершения отдельной транзакции. На этом примере также демонстрируется способ быстрого и грубого распределения нагрузки между множественными потребительскими процессами: это так называемая модель голодного потребителя. В модели голодного потребителя центральный планировщик заменяется на несколько независимых задач потребителя и централизованную очередь работ. Каждая задача потребителя захватывает некий фрагмент очереди работ и продолжает заниматься своим делом – его обработкой. Как только задача заканчивает свою работу, она возвращается к очереди за новой порцией. В этом случае, если выполнение какой-либо задачи срывается, другие задачи могут "натянуть поводья" и каждый отдельный компонент может продолжаться в своем собственном темпе. Происходит временная несвязанность одного компонента с другими.
Подсказка 40: Проектируйте, используя службы
На самом деле, вместо компонентов мы создали службы – независимые, параллельные объекты, скрытые за четко определенными, непротиворечивыми интерфейсами.
Проектирование с использованием принципа параллелизма
Поскольку Java все чаще принимается в качестве платформы, многие разработчики перешли к многопоточному программированию. Но программирование с использованием потоков налагает на конструкцию некоторые ограничения – и это хорошо. Эти ограничения настолько полезны, что нам хотелось бы пребывать под их благодатным покровом, когда бы мы ни занимались написанием программ. Это поможет нам делать нашу программу несвязанной и бороться с так называемым "программированием в расчете на стечение обстоятельств" (см. ниже одноименный раздел). При работе с линейной программой легко сделать предположения, которые в конечном итоге приведут к небрежно написанным программам. Но параллелизм заставляет задумываться о происходящем несколько глубже – вы больше не находитесь в безвоздушном пространстве. Поскольку многие события могут теперь происходить "в одно и то же время", вы можете внезапно столкнуться с зависимостями, основанными на факторе времени. Прежде всего необходимо защитить любые глобальные или статические переменные от параллельного доступа. Теперь можно задать самому себе вопрос, зачем нужна глобальная переменная на первом месте. Кроме того, необходимо убедиться в том, что вы предоставляете непротиворечивую информацию о состоянии независимо от порядка вызовов. Например, в какой момент допускается опрашивание состояния вашего объекта? Если ваш объект находится в недопустимом состоянии в период между определенными вызовами, то вы, вероятно, полагаетесь на стечение обстоятельств – никто не вызовет ваш объект в этот момент времени. Предположим, что есть подсистема работы с окнами, в которой интерфейсные элементы вначале создаются, а затем отображаются на дисплее. Вам не разрешается задавать состояние в элементе, пока он не отобразится. В зависимости от заданных параметров программы вы можете полагаться на то условие, что ни один другой объект не может воспользоваться созданным элементом, пока вы не выведете его на дисплей. Но в параллельной системе это может и не выполняться. При вызове объекты всегда обязаны находиться в допустимом состоянии, а они могут вызываться в самое неподходящее время. Вы обязаны убедиться, что объект находится в допустимом состоянии в любой момент, когда потенциально он может быть вызван. Зачастую эта проблема возникает с классами, которые определяют отдельные программы конструктора и инициализации (где конструктор не оставляет объект в инициализированном состоянии). Используя инварианты класса, обсуждаемые в разделе "Проектирование по контракту", вы сможете избежать этой ловушки. Четкие интерфейсы Размышления о параллелизме и зависимостях, упорядоченных во времени, могут заставить вас проектировать более четкие интерфейсы. Рассмотрим библиотечную подпрограмму на языке С под названием strtok, которая расщепляет строку на лексемы. Конструкция strtok не является поточно-ориентированной
, но это не самое плохое, рассмотрим временную зависимость. Первый раз вы обязаны вызвать подпрограмму Strtok с переменной, которую вы хотите проанализировать, а во всех последующих вызовах использовать NULL вместо этой переменной. Если переменная принимает значение, отличное от NULL, программа повторно производит разбор содержимого буфера. Не принимая во внимание потоки, предположим, что вы собираетесь использовать Strtok для одновременного синтаксического анализа двух отдельных строк: char buf1[BUFSIZ]; char buf2[BUFSIZ]; char *p, *q; strcpy(bufl, "это тестовая программа"); strcpy(buf2, "которая не будет работать"); р = strtck(buf1," "); q = strtok(buf2," "); while (p && q) { printf("%s %s\n", p, q); p = strtok(NULL, " "); q = strtok(NULL, " "); } Представленная программа работать не будет: существует неявное состояние, сохраняющееся в strtok между запросами. Вам придется использовать Strtok одновременно только с одним буфером. Конструкция синтаксического анализатора строк на языке Java будет отличаться от указанной выше. Она должна быть поточно-ориентированной и представлять непротиворечивое состояние. StringTokenizer st1 = new StringTokenizer("this is a test"); StrJngTokenlzer st2 = new StringTokenizer("this test will work"); while (st1.hasMoreTokens() && st2.hasMoreTokens()) { System.out.println(st1.nextToken()); System.out.println(st2.nextToken()); } Программа StringTokenizer обладает более четким и простым в сопровождении интерфейсом. Она не содержит в себе никаких сюрпризов и в будущем не приводит к появлению таинственных дефектов, чего нельзя сказать о программе Strtok.
Подсказка 41: При проектировании всегда есть место параллелизму
Развертывание
Как только вы спроектировали архитектуру с элементом параллельности, задача об управлении многими параллельными службами упрощается: модель становится всеобъемлющей.
Теперь вы можете проявить гибкость относительно способа развертывания приложения: по автономной модели, модели «клиент-сервер» или по n-звенной модели. Создавая архитектуру системы на основе независимых служб, вы также придаете динамизм процессу конфигурирования. Рассчитывая на параллелизм и разделяя операции во времени, вы получаете вес эти варианты, включая автономный вариант развертывания, где вы можете отказаться от параллелизма.
Другой путь (попытка внести параллелизм в непараллельное приложение) представляется намного сложнее. Если мы проектируем с учетом параллелизма, то со временем нам легче обеспечивать расширяемость и производительность, а если этот момент не настает, мы все равно получаем выгоду от более четкого интерфейса.
Так, может быть, пора?
Другие разделы, относящиеся к данной теме: • Проектирование по контракту
• Программирование в расчете на стечение обстоятельств
Вопросы для обсуждения • Сколько задач вы выполняете параллельно, готовясь к работе? Можете ли вы выразить это с помощью диаграммы на языке UML? Можете ли вы найти иной, более быстрый способ подготовки к работе, придав своим действиям больший параллелизм?
29
Всего лишь визуальное представление
Каждый смертный все же видит
Только то, что хочет видеть,
Отметая остальное.
Ля-ля-ля…
П. Саймон и А. Гарфункель, Боксер
Ранее нас учили не писать программы одним большим куском, а использовать принцип "разделяй и властвуй" и разбивать программу на модули. У каждого молу-ля есть свои собственные обязанности; модуль (или класс) считается четко определенным, если у него имеется одна четко обозначенная обязанность.
Но как только вы разбиваете программу на различные модули, основанные на обязанностях, вы сталкиваетесь с новой проблемой. Каким образом объекты общаются друг с другом на стадии выполнения программы? Как вы управляете логическими зависимостями между ними? Другими словами, как вы осуществляете синхронизацию изменений состояния (или обновление значений данных) различных объектов? Этой работе должна быть присуща четкость и гибкость – мы не хотим, чтобы они узнали друг о друге слишком много. Мы хотим, чтобы каждый модуль был похож на героя песни Саймона и Гарфункеля и видел только то, что хочет увидеть.
Начнем с концепции события. Событие представляет собой специальное сообщение, в котором говорится: "Только что случилось нечто интересное" (разумеется, с точки зрения наблюдателя). Мы можем использовать события, чтобы сигнализировать одному объекту об изменениях, произошедших с другим объектом, в которых последний может быть заинтересован.
Подобное использование событий сводит к минимуму связывание между двумя объектами – отправителю события не нужно обладать явной информацией о получателе. На самом деле могут существовать и множественные получатели, каждый из которых сосредоточен на собственном перечне основных операций (отправитель же находится в блаженном неведении относительно этого факта).
Однако при использовании событий необходимо соблюдать некоторую осторожность. Например, в одной из ранних версий Java одна подпрограмма получила все события, предназначенные для специфического приложения. Это не совсем подходит для облегчения сопровождения или развития программы.
Протокол "Публикация и подписка"
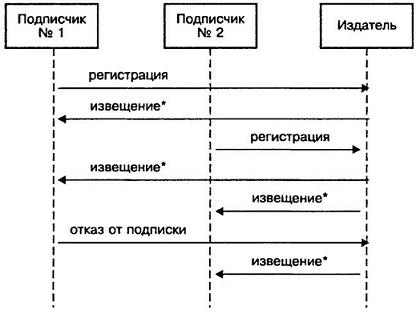
Почему считается дурным тоном пропускать все события через одну-единственную программу? Потому что при этом нарушается инкапсулирование объекта – теперь этой подпрограмме приходится получать сокровенную информацию о взаимодействии между многими объектами. Это также способствует увеличению связывания, а мы пытаемся его уменьшить. Поскольку и самим объектам приходится получать информацию об этих событиях, то, по всей вероятности, вы собираетесь нарушить принцип DRY, принцип ортогональности и, может быть, некоторые разделы Женевской конвенции. Быть может, вам случалось видеть подобные программы – их доминантой является огромный оператор case или многообразная конструкция if-then. Мы можем сделать это изящнее. Объекты должны иметь возможность регистрации только для приема событий, которые им нужны, и никогда не должны посылать события, которые им не нужны. Мы не хотим, чтобы наши объекты подверглись спаммингу! Вместо этого мы можем воспользоваться протоколом типа "публикация и подписка", который представлен на рисунке 5.4 с помощью диаграммы последовательностей на языке UML
. На блок-схеме последовательности показан поток сообщений между несколькими объектами, которые располагаются по столбцам. Каждое сообщение обозначено стрелкой с текстом, идущей от столбца отправителя к столбцу получателя. Звездочка у текста означает, что возможна посылка более одного сообщения данного типа.
Рис. 5.4. Протокол "Публикация и подписка"
Если нам интересны определенные события, которые генерируются объектом Publisher (Издатель), то все, что нам нужно, – это зарегистрироваться. Объект Publisher отслеживает все заинтересованные объекты Subscriber (Подписчик); когда объект Publisher генерирует событие, представляющее интерес, он, в свою очередь обращается к каждому объекту Subscriber, извещая их о том, что данное событие произошло. На эту тему существует несколько вариаций, отражающих другие стили обмена данными. Объекты могут использовать протокол "Публикация и подписка" на одноранговой основе (как показано выше), а также "программную шину", где централизованный объект поддерживает базу данных «слушателей» и осуществляет соответствующую диспетчеризацию. Вы даже можете получить схему, в которой критические события транслируются ко всем «слушателям» – как зарегистрированным, так и незарегистрированным. Одна из возможных реализаций событий в распределенной среде иллюстрируется службой сообщений CORBA, описанной во врезке "Служба событий CORBA" (см. ниже).
Страницы:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22
|
|