 |
|
Популярные авторы:: Раззаков Федор :: Горький Максим :: Толстой Лев Николаевич :: Сименон Жорж :: Азимов Айзек :: Борхес Хорхе Луис :: Грин Александр :: Пушкин Александр Сергеевич :: Гарднер Эрл Стенли :: Твен Марк Популярные книги:: Справочник по реестру Windows XP :: Башня зеленого ангела (Орден Манускрипта - 6) :: Зажги свет в доме своём :: Покинутый корабль :: Отпуск Мегрэ :: Участник поисков :: Великая резня - 1994 :: Медиумы :: Ломбард :: Немые и проклятые |
Вальсируя с медведямиModernLib.Net / Программирование / Демарко Том / Вальсируя с медведями - Чтение (стр. 7)
В этом есть некий псевдонаучный момент, который нельзя обойти вниманием. Мы проигнорировали дополнительные причины прекращения проекта и создали свой симулятор «RISKOLOGY» таким образом, что он вынуждает вас столкнуться с возможностью прекращения проекта, пока не пройдено контрольное событие, обозначающее окончание угрозы, после чего предполагается нулевой риск прекращения проекта. Это — весьма грубый подход к деликатному предмету прекращения проектов, оправданный лишь тем, что очень высока доля проектов, в конце концов прекращенных, для которых оказалось невозможным достичь соглашения, необходимого для наступления данного контрольного события. Главный риск №5: Низкая производительность В литературе есть множество свидетельств наличия существенных различий в производительности между группами разработчиков. Различия между командами проектов в целом несколько сглажены и всегда меньше, чем индивидуальные различия. Более того, некоторые различия индивидуальной производительности возникают из-за того или иного из четырех главных рисков, о которых уже шла речь. После устранения воздействия других рисков и распространения индивидуальных различий на команды мы видим следующий результат вариации командной производительности (см. рисунок ниже). Этот фактор, как правило, сбалансирован: по сути, одинакова вероятность как позитивных, так и негативных изменений производительности. Опасно использовать наши данные для очень малых команд, поскольку индивидуальные различия там могут не сгладиться. Например, команда из одного человека подвержена куда большему воздействию низкой или высокой производительности. Сбалансированный риск, вроде низкой или высокой производительности, просто вносит шум в процесс. Он расширяет диапазон неопределенности без сдвига среднего ожидаемого показателя, в каком бы то ни было направлении.  Совокупное воздействие главных рисков Моделирование требует нескольких параметров проекта и дает возможность заменить любой (или все) из главных рисков вашими собственными данными, а затем просчитывает варианты проекта, чтобы определить, какую продолжительность проекта следует ожидать. Данный профиль является результатом 500 отдельных прогонов, даты завершения которых сгруппированы в дискретные диапазоны. Для проекта (названного здесь Amalfi), где N — примерно 26 месяцев, без замещений, результаты моделирования с помощью «RISKOLOGY» похожи на цифры, с которыми вы сталкивались в конце главы 12:  Покажем здесь, как вы могли бы интерпретировать и объяснить результат, если бы таким был ваш проект существует некоторая ненулевая вероятность завершения проекта в период между 26-м месяцем и 27-м месяцем. Значительно вероятнее, однако, что вы будете готовы между 32-м и 34-м месяцами. С 75%-ной достоверностью можно назначить сроком сдачи 38-й месяц. Около 15% прогонов заканчивается прекращением проекта. Это — честная оценка риска прекращения проекта, с точки зрения взгляда на проект с начальной его даты, но за шесть месяцев действия проекта должно стать возможным оценить риск прекращения точнее и, быть может, снять его. Главные риски как показатель полноты выполнения управления рисками Главные риски можно также использовать для оценки того, был ли процесс управления рисками осуществлен разумно. Например, если вы представили пять главных рисков, но использовали данные, отличные от наших, вы можете быть достаточно уверены, что осуществили управление рисками, причем осуществили его разумно. Но мы с большим недоверием относимся к проектам, претендующим на управление рисками, когда они не принимали во внимание эти пять главных рисков. Глава 14 Уточненный процесс обнаружения рисков Вам следует беспокоиться не только о главных рисках. Может быть немало рисков, свойственных именно вашему проекту, которые нужно учесть в вашем уравнении риска. Например, может быть ключевой исполнитель, чей уход станет роковым для проекта, важный пользователь, который может решить идти своим путем или поставщик, чья необязательность может иметь ужасные последствия. Как только вы обнаружили и количественно оценили эти риски, ими можно управлять, как и любыми другими. Но выявить их может быть нелегко. Культура наших организаций иногда не позволяет говорить о самых тревожащих рисках. Мы ведем себя, как самые дикие племена, которые пытаются не подпустить к себе дьявола тем, что отказываются произносить его имя. Хранить молчание о риске — это не способ избавиться от него. Например, при подготовке проекта запуска Ariane 5[24], никто не говорил, что есть риск ошибок, связанных с тем, что компилятор не делает проверку граничных значений, и это поставит под угрозу запускаемый спутник. Но это, тем не менее, случилось и привело к полному провалу запуска. Обычным при обнаружении риска бывает чье-то высказывание «Знаете, если <нечто> случится, мы сильно влипнем…». Обычно говорящий уже какое-то время знал о риске и, возможно, даже самостоятельно его оценил в какой-то такой форме: «Пожалуй, я всерьез займусь своим резюме, если будет похоже, что <это нечто> может случиться». Когда все управление рисками в данном проекте происходит в голове единственного встревоженного индивида, то это говорит о сбое в коммуникации. А конкретнее, это означает, как правило, что существует некое препятствие, перекрывающее потоки важной информации. Выявление препятствий Рассмотрим эти факторы в реальном контексте: утром 28 января 1986 гола взорвался космический корабль Challenger, что повлекло ужасающие потери человеческих жизней, материальных средств и национального престижа. Расследование показало, что резкое похолодание непосредственно перед пуском вызвало выпадение из заданного температурного режима всей первой ступени и ее компонентов. Система была предназначена для работы при температуре выше нуля, а на деле оказалось куда холоднее. Никто из персонала не думал о кольцевых уплотнителях твердотопливных ускорителей, которые и вызвали беду, но многие люди знали, что компоненты системы чувствительны к низкой температуре, и нельзя рассчитывать, что они смогут нормально функционировать при температуре ниже нуля. Почему они молчали? У них были те же самые причины, которые не дают людям озвучивать риски в любых других компаниях. Это принимает форму неписаных правил, встроенных в корпоративную культуру: 1. Не имей привычки думать о неприятностях. 2. Не поднимай проблему, если у тебя нет готового решения. 3. Не говори, что нечто является проблемой, если не можешь доказать, что это так. 4. Не будь помехой. 5. Не озвучивай проблему, если не хочешь, чтобы на тебя возложили ответственность за ее немедленное решение. <……> суждаются открыто, то их никогда и не приспосабливают к изменяющимся обстоятельствам. Нам всем велят на работе принимать менталитет «будет сделано». И в этом загвоздка. Назвать риск по имени — значит оказаться в парадигме «не могу сделать». Обнаружение риска находится в глубоком противоречии с этим фундаментальным аспектом наших организаций. Поскольку подавление стимулов является достаточно мощным, нужен открытый, установленный и хорошо понимаемый процесс, обеспечивающий возможность высказываться. Нужен механизм, способ полного вовлечения всех и каждого при гарантированной безопасности. В основе этого механизма должны быть временные правила, позволяющие, по крайней мере, в данный момент, не повиноваться неписаным правилам. Если ваш начальник публично просит вас исполнить «роль адвоката дьявола для этой идеи», вы явно освобождены от диктата мышления «будет сделано». Это позволяет вам наслаждаться негативным мышлением типа «что если». Именно этого должен достичь наш уточненный процесс обнаружения рисков. Уточненный процесс Предлагаемый нами уточненный процесс для идентификации рисков включает три этапа продвижения от обнаруженного риска назад, к причинам его возникновения: 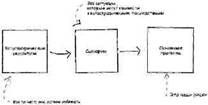 Когда происходит реальная катастрофа, эти три этапа проходят в противоположном порядке, двигаясь от причины по раскручивающемуся сценарию к окончательному результату. Но слишком жутко иметь с ними дело в таком порядке. Отработка «задом наперед» пугает меньше. Она позволяет сначала сконцентрировать внимание на возможном кошмарном результате, совершенно изолированно, отдельно от причины. Но даже при этом людям нелегко высказывать такие опасения: ТРЛ: В прошлом году мне нужно было сделать операцию на колене при полном обезболивании. Накануне моей отправки в больницу жена спросила, беспокоюсь ли я из-за этой операции. Я быстро ответил, что ни капельки, что тысячи таких операций проходят без всяких проблем. Немного позже я признался ей, что есть у меня какой-то небольшой, как мне казалось, иррациональный страх. Я боялся, что хирург прооперирует другую ногу. Жена посоветовала сказать врачу об этом. На следующее утро меня подготовили к операции, рядом была жена. Хирург вошел рассказать о послеоперационных процедурах. Жена смотрела на меня, удивленно вскинув брови. Я молчал. Прямо перед тем, как уйти готовиться к операции, хирург взял маркер и написал «Да» прямо над коленом, которое предстояло оперировать. Жена улыбнулась, а за ней и все мы. Механизм должен поощрять людей делиться своими страхами. Если бы доктор прямо спросил Тима в предоперационной палате, чего он особенно боится, проблема была бы тут же выложена. Механизм должен включать просьбу ко всем участникам поделиться своими худшими опасениями. Иногда помогает возможность сказать (как в рассказе Тима), что страх иррационален. Дальнейший процесс состоит в том, чтобы дедуктивным методом выявить, как мог бы реализоваться этот кошмар. Вся штука в том, чтобы пройти все три этапа более или менее механически, без всяких упреков и обвинений. «У меня есть такой кошмар, вот — сценарий, который мог бы к нему привести, а запустить этот сценарий могла бы такая штука…» Voila, один риск найден. Чтобы преодолеть табу неписаных правил, процедура обнаружения рисков должна быть изложена в письменном виде и роздана всем перед началом мероприятия. Вы не можете нежданно-негаданно обрушиться на людей и рассчитывать, что они пренебрегут неписаными правилами без надежной, формальной защиты. Процесс обнаружения рисков не должен состояться лишь один раз в начале проекта. Он должен стать постоянно действующей частью работы над проектом. На каждом совещании по выявлению рисков должен формально провозглашаться подход, которому будут следовать, чтобы неписаные правила были эффективно приостановлены. Три этапа обнаружения рисков обычно проходят одновременно на одном и том же совещании. Но методы уникальны для каждого из этапов, поэтому стоит рассмотреть по очереди каждый. Этап 1: мозговой штурм по выявлению катастроф Мозговой штурм — это групповое творчество. Идея состоит в использовании групповой динамики для отыскания обходных путей преодоления привычного мышления и возникновения новых свежих мыслей. Мозговой штурм по выявлению катастроф имеет несколько иной характер, хотя и здесь полезны некоторые методы классического мозгового штурма. В поисках хорошего описания этих методов рекомендуем заглянуть в раздел об использовании мозгового штурма (см. ссылки в конце книги). Мозговой штурм использует хитрости, мелкие уловки для помощи группе в преодолении неизбежной зажатости и тупиков. Даже названия, перечисленные в ссылках, предлагают дюжины этих хитростей, каждая из которых полезна для того, чтобы заставить группу придумать полезные ночные кошмары. Ниже представлены несколько хитростей, присущих только мозговому штурму в поисках катастроф: 1. Ставьте вопрос в явном виде в терминах ночного кошмара: почему-то это также помогает преодолеть действие неписаных правил, независимо от того, насколько присуще было корпоративной культуре позитивное мышление, ведь по-прежнему считается вполне нормальным вскочить ночью из-за жутких мыслей. Спросите людей, каковы их худшие опасения относительно проекта. Когда они просыпаются в холодном поту от ужаса за проект, что пугает их? 2. Используйте хрустальный шар: Представьте, что у вас есть доступ к хрустальному шару или способность узнавать чудом заголовки газет следующего года. Представьте, что это подглядывание в будущее свидетельствует о бедствии, постигшем проект, но что это за беда? Или, представьте, что ваша компания попала в «колонку идиотов» в журнале The Wall Street Journal, которая располагается посредине первой страницы, а причиной стали бы ужасы, которые творятся с этим проектом. Теперь задайтесь вопросом: «Как это могло случиться?» 3. Опишите противоположные виды на будущее: Попросите людей описать свои самые радужные мечты относительно проекта, а затем обсудите прямо противоположную версию. 4. Спрашивайте о провале, в котором нет виновных: Как может проект потерпеть неудачу без того, чтобы это было чьей-то виной? 5. Спрашивайте о провале, в котором есть конкретные виновники: Спросите людей: «Как бы мог проект провалиться по нашей собственной вине? по вине пользователя? по вине руководства? по вашей вине?» (Это работает, если только убедиться, что все повлечены в действие). 6. Представьте себе частичную неудачу: Спросите, как мог бы проект преуспеть в целом, по оставить одного конкретного участника неудовлетворенным или разгневанным. Мозговые штурмы стремительны и яростны, поэтому нужно заранее сделать некоторые приготовления, чтобы не пропустить ни одного предположения. Убедитесь, что обязанность следить за этим возложена не на фасилитатора. Этап 2: построение сценария Теперь вернемся к предполагаемым катастрофам и поочередно будем рассматривать их и воображать сценарии, которые могли бы привести к каждому из результатов. Придумывание сценариев может быть совершенно механическим, но вопрос о вине может повиснуть в воздухе, поэтому можно ожидать здесь некоторой напряженности. Здесь тоже нужно заранее продумать механизм улавливания и сохранения всей информации и использовать его, чтобы внезапно усилившаяся напряженность не помогла упустить те моменты, которые требуют самого пристального внимания. Стоит приписать хотя бы предположительную вероятность этим сценариям. Очевидно, что наиболее невероятные сценарии менее ценны, поскольку не оправдывают усилий по дальнейшему рассмотрению. Но бдительно относитесь к низким вероятностям, которые группа может приписывать определенным сценариям, ведь кто-то предложил их и для этого человека, возможно, это не было вопросом, которым можно пренебречь. Вместо того чтобы проводить анализ вероятности на месте, можно отложить его для проведения потом в подгруппах. Это даст некоторые эмпирические свидетельства для определения того, стоит или не стоит беспокоиться по поводу данного сценария. Этап 3: анализ основных причин Имея перед собой сценарии, все могут вместе определить потенциальную основную причину. Это гораздо легче сделать до того, как сценарий начал по-настоящему реализовываться. Когда сценарий воспринимается всего лишь как абстракция, то есть какая-то ерунда, которая могла бы приключиться, можно рассматривать причины без поиска виноватых: «Ну, не могу вообразить, чтобы это случилось, разве что какой-то идиот украдет часть персонала, чтобы использовать как „пожарную команду“, в другом месте». Такое достаточно легко сказать, пока на самом деле катастрофа не произошла, даже если потенциальный идиот находится вместе с нами в этой комнате. Ваши риски являются основными причинами сценариев, которые могут привести к катастрофическим результатам. Анализ основных причин сложнее, чем кажется. Причина этого не только во влиянии неписаных правил, но и в сложности понятия «основная» (определении того, достаточно ли глубока причина). Этот процесс успешнее осуществляет группа, чем отдельный индивидуум. За полезными подсказками по проведению сессий анализа основных причин обратитесь к соответствующему разделу ссылок в конце книги. Взаимовыгодная альтернатива Взаимовыгодная спиральная модель процессов[25] Барри Боэма (Barry Boehmi) соединяет многое из достижений человеческого разума, сделанных до сегодняшнего дня. (См. ссылки в конце книги или сайт RISKOLOGY). Она объединяет: • жизненный цикл, развивающийся по спирали • систему показателей (конкретнее, СОСОМО II) • управление рисками • «теорию W» группового взаимодействия Это — способ руководства IT-проектами в свете тех проблем, которые обычно преследуют каждое такое предприятие. С уникальным подходом Боэма к разработке программного обеспечения стоит познакомиться по причинам, выходящим далеко за пределы данной книги. Однако мы упоминаем об этом здесь, чтобы описать один из незначительных аспектов взаимовыгодной стратегии, бросающий полезный свет на обнаружение рисков. При взаимовыгодной стратегии проект строится на честном обязательстве отыскать всех участников проекта и узнать у каждого так называемые выигрышные условия, которые, с их точки зрения, обеспечивали бы успех проекта. Согласно этой методологии, требования определены как набор условий выигрыша. Ничто нельзя считать требованием, если никто не идентифицирует его как одно из своих условий выигрыша. Иногда условия выигрыша конфликтуют, особенно по мере роста числа участников проекта. Условие выигрыша, выраженное одной из сторон, может затруднить или сделать невозможным достижение выигрышных условий, выраженных другими сторонами. При взаимовыгодной стратегии любая пара выигрышных условий, между которыми существует конфликт или напряженность, представляет собой риск. Вы можете суметь использовать модель Боэма для обнаружения рисков, которые иначе было бы невозможно выявить. Очень много рисков, затрагивающих IT-проекты, возникли непосредственно из-за конфликтующих условий выгоды для различных участников, а использование модели Боэма ведет прямо к сути этой основной проблемы. Если даже ваш проект не выполняет формального и полного выяснения выигрышных условий, вы можете сами поразмышлять над условиями выигрыша в процессе определения рисков. Рассматривайте это как одну из уловок, которыми вы пользуетесь. Спросите участников: «Можете ли вы придумать очевидное условие выигрыша для данного проекта, которое находилось бы в конфликте с чьей-то еще выигрышной стратегией?» Каждый выявленный конфликт — это потенциальный риск. Глава 15 Динамика управления рисками Несмотря на неоднократно повторявшиеся утверждения, что управление рисками должно быть постоянной деятельностью, у вас могло все же остаться ощущение, что им по-настоящему занимаются в начале проекта, а затем (не считая эпизодического пустословия) спокойно забывают о нем до следующего проекта. Возможно, так могли бы решать проблемы управления рисками существа, наделенные даром абсолютного предвидения, но не мы. Когда проекты проваливаются, то часто это происходит примерно на середине, поэтому именно в это период управление рисками нужно проводить особенно активно. Причины проблем почти всегда возникают еще раньше, но их осознание приходит примерно на середине проекта: на начальной стадии проекта дело кажется идущим без помех, а затем все разваливается. Эту стадию проекта можно назвать «Возмездие»: к нам возвращаются наши прошлые грехи, включая плохое планирование, пропущенные задачи, плохо построенные отношения, скрытые допущения, излишнюю надежду на везение и т.п. В этой главе мы рассмотрим роль управления рисками в период Возмездия и далее, вплоть до конца проекта. Управление рисками, начиная с периода Возмездия Вот наш краткий список мер по управлению рисками, которые нужно осуществлять в период с середины проекта и далее, до самого конца: 1. непрерывный мониторинг показателей наступления рисков в поисках такого риска из списка, который кажется готовым перейти из разряда «всего лишь скверной возможности» в разряд «реальных проблем» 2. продолжение выявления рисков 3. сбор данных для наполнения хранилища рисков (базы данных для определения количественного влияния проблем, наблюдавшихся в прошлом) 4. ежедневное отслеживание показателей завершенности (см. ниже) Пункты 1 и 2 были рассмотрены в главах 9 и 14, и здесь мы к ним не будем возвращаться. Пункты 3 и 4 относятся к системе показателей: количественным показателям размера, целей и содержания, сложности и состояния проекта. Эти показатели и будут предметом этой и следующей глав. Показатели завершенности Мы используем здесь термин «показатели завершенности» но отношению к определенному классу показателей состояния, показывающему состояние исполнения проекта. Совершенная система показателей завершенности (если только такие существуют) уверенно покажет, что выполнено 0% в начале проекта и 100% в конце успешно завершенного проекта. А между ними она будет показывать постепенно возрастающие величины от 0 до 100. В лучшем из миров анализ после завершения проекта приведет к выводу, что значения безупречной системы показателей на каждой стадии проекта точно и ясно предсказывали, сколько еще остается времени и усилий. Понятно, что совершенных систем показателей завершенности не бывает, но существуют несовершенные, которые невероятно полезны. Мы — сторонники двух из них: • завершение описания граничных условий проекта • освоенный объем функционала (ООФ)[26] Эти показатели дают нам способ отслеживать пять главных рисков, рассмотренных в главе 13. Первая система защищает от главного риска, состоящего в нарушении спецификаций. Вторая представляет собой общий показатель чистого прогресса, используемый для отслеживания влияния остальных четырех главных рисков. Завершение описания граничных условий проекта Система — это нечто, предназначенное для преобразования входов в выходы, как показано на следующей диаграмме: 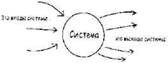 Это — правильное описание, будь система, о которой идет речь, государственным ведомством, бухгалтерской компанией, типичной IT-системой, живым человеком или селезенкой… то есть чем бы то ни было, что мы склонны назвать словом «система». В этом смысле у IT-систем есть отличие: они преобразуют потоки входных данных в потоки выходных данных. Традиционно задача спецификации таких систем сводилась почти полностью к определению правил преобразования, методики и подходов, применяемых системой при преобразовании входных потоков в выходные. Часто в процессе спецификации пропускают строгое и подробное описание самих потоков. Этот пропуск имеет некоторые непреодолимые причины: работа по определению этих потоков часто рассматривается как задача проектирования, которую программисты будут решать на более поздних стадиях. Она может оказаться очень затратной по времени. Откладывание полного определения разумно в проектах, где можно быть уверенными в успешном завершении проекта, но есть ведь и менее везучие проекты, где подробное определение потоков невозможно успешно провести, поскольку это вызовет обострение некоторых конфликтов среди участников проекта. Существование таких «дефективных» проектов вынуждает нас запихивать работу по описанию потоков обратно на раннюю стадию жизненного цикла с намерением заставить конфликт всплыть на поверхность пораньше, не позволяя ему оказаться замазанным на начальных стадиях и неожиданно появиться позднее. При этом подходе граничные потоки определены, но не спроектированы. Под этим мы подразумеваем, что они разложены до уровня элементов данных, но еще не упакованы в какой-то формат. Цель раннего обращения к проблеме состоит в том, чтобы все стороны согласились с составом потоков. В большинстве проектов такое согласие удается получить в пределах первых 15% времени работы над проектом. Когда согласие еще не достигнуто, а проект явно прошел 15%-ную отметку, то это с очевидностью указывает на то, что существует либо конфликт между участниками проекта (нет единого мнения о том, какую систему строить), либо прискорбная ошибка в оценке длительности проекта. В любом случае отсутствие согласия представляет собой проявление риска, причем одного из главных. Нет смысла работать над чем-то другим, пока не будет завершено описание граничных элементов. Если этого не произойдет, нет лучшего выбора, чем прекращение проекта. ООФ (первый проход) Освоенный объем функционала — это система показателей готовности проекта. Она должна говорить вам, насколько далеко вы продвинулись по пути от 0% готовности к 100% готовности. Поскольку ООФ тесно связан с инкрементной разработкой проекта[27], мы решили отложить подробное определение этой метрики до обсуждения метода инкрементной разработки в следующей главе. На этапе первого прохода мы покажем только основное назначение этой системы и ее отношение к инкрементному плану проекта. Допустим, что мы заглянули внутрь системы, которую вы намереваетесь построить, и изображаем ее разбитой примерно на сотню основных частей:  Если вы теперь начнете строить систему просто по методу «большого взрыва» (строить все эти части, соединять и тестировать их, поставлять их все вместе, когда все будут готовы), то вашей единственной метрикой готовности будет окончательная проверка при приеме проекта в целом. В виде функции от времени ваша показанная готовность будет выглядеть так: 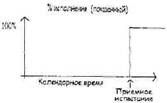 Вы проявляете 0%-ную готовность до самого конца, а затем внезапно она сменяется 100%-ной готовностью. Единственной причиной верить, что дело обстоит иначе (скажем, верить в некоторый момент, что вы находитесь в состоянии 50%-ной готовности), являются косвенные признаки. ООФ предназначен для обеспечения объективными свидетельствами частичной готовности, которые позволят вам нарисовать такую картинку и поверить в нее: 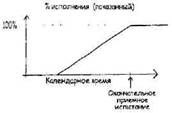 Все равно будет период на начальной стадии, когда прогресс подтверждается только верой. Однако уже намного раньше середины проекта, вы будете получать довольно надежные свидетельства от ООФ о частичной готовности. ООФ зависит от вашей способности строить систему методом инкрементной разработки, скажем, используя выбранные подсистемы, составленные из частей системы и называемые версиями. Так, версия 1, например, может быть такой:  Здесь вы соединяете (как можно лучше) входящие <……> частичным продуктом. Разумеется, частичная система <……> все, что должна делать полная система, но что-то <……> можно тестировать. Итак, вы это тестируете. Вы проводите испытания версии 1 и, когда она их проходит, вы заявляете <……> Версия 2 имеет больше функций:  Версия — % от общего ООФ 1 — 11% 2 — 19% 3 — 28% 4 — 38% 5 — 51% 6 — 60% 7 — 72% 8 — 81% 9 — 94% 10 — 100% Теперь с момента, когда версия 1 проходит свои приемные испытания (ПИ1), вы можете построить кривую, показывающую ожидаемую дату каждого следующего приемного испытания (ПИ)[28]. По мере прохождения этих испытаний можно в такой форме проследить ожидаемый ООФ и соотнести его с реальным:  Проявление любого из главных рисков (или какого-то еще серьезного риска) вызовет заметное отставание реального завершения версий от ожидаемого. Приведенный здесь пример явно вымышленный, но при выборе чисел и формы графика реального завершения, сравниваемого с ожидаемым, мы старались дать вам представление о примерном уровне контроля, обеспечиваемого этой схемой. Глава 16 Инкрементный метод для ослабления рисков Ослабление рисков включает полный набор предварительных мер, которые можно принять для обеспечения возможности последующих действий по эффективному противодействию рискам в случае их материализации. Всякое ослабление включает затраты и задержки в текущий момент ради того, чтобы справиться с возможными рисками при их наступлении в будущем. Это делает наилучший сценарий чуть менее прекрасным, поскольку, если риск не наступит, то затраты на ослабление могут показаться пропавшими зря. Анализ различных стратегий ослабления риска в терминах «платы за удовольствие» выглядит так: ваше удовольствие представляет собой взвешенную оценку сокращения затрат и задержек на преодоление возможных проявлений риска, а ваша плата — это затраты и задержки, связанные с самим ослаблением. Лучшей известной нам стратегией ослабления риска в терминах «плата за удовольствие» является инкрементная поставка. Под инкрементной поставкой мы понимаем… Инкрементная поставка — это разработка полного или практически полного плана проекта, а затем воплощение этого плана в жизнь подмножествами, где каждое следующее подмножество включает в себя предшествующие. Полная стратегия инкрементной поставки может и должна быть представлена и описана планом инкрементной поставки (см. ниже) еще до создания первого подмножества. Множество преимуществ инкрементной поставки были отмечены и документированы как нами самими, так и другими авторами (см. ссылки в конце книги). Есть несколько дополнительных причин особой привлекательности этого метода для менеджеров рисков: • Он может подтвердить гипотезы планирования проекта или доказать их несостоятельность. • Он требует упорядоченности компонентов системы. • Он может быть использован для оптимизации выгоды от промежуточных результатов (что особенно приятно в случае, если проект перерасходовал время и/или деньги). 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 |
|||||||