 |
|
Популярные авторы:: БСЭ :: Желязны Роджер :: Joyce James :: Раззаков Федор :: Толстой Лев Николаевич :: Станюкович Константин Михайлович :: Андерсон Пол Уильям :: Чехов Антон Павлович :: Грин Александр :: Лондон Джек Популярные книги:: The Boarding House :: Бурый волк :: Пошехонская старина :: Мальтийский сокол :: Подземная Москва :: Основание :: Вторая книга Паралипоменон :: Тварь в лунном свете :: Дневник путешествия из Тоса (Тоса никки) :: Как мы изобрели фотосинтезатор |
Компьютерра (№255) - Журнал «Компьютерра» № 5 за 7 февраля 2006 годаModernLib.Net / Компьютеры / Компьютерра / Журнал «Компьютерра» № 5 за 7 февраля 2006 года - Чтение (стр. 5)
Отсюда же и способность забывать неактуальную информацию. Человек никогда не забудет имя своей сестры, но имя преподавателя географии забыть может. Каждому знакомо раздражение, которое вызывается частым напоминанием незначительных событий. Даже такой всесторонне защищенный общественный институт, как семья, может быть разрушен, если один из супругов будет постоянно напоминать об обстоятельствах, которые другому супругу кажутся мелкими. Но человек не может без вспомогательных средств справиться с большими массивами информации, актуальность которой либо невозможно оценить, либо она может или должна быть оценена в будущем. Важнейшая функция информационных систем — законсервировать информацию для последующей оценки.
Если такая информационная система создается для принятия властных решений, чрезвычайно важно сохранить не только саму информацию, но и сведения о любых действиях с ней. В бумажных системах это обеспечивается заверением каждого документа подписью должностного лица, что позволяет в будущем установить как законность действия (полномочия чиновника), так и достоверность документа (его подлинность и отсутствие внесенных впоследствии искажений, например подчисток). В электронных системах используются совершенно иные принципы обработки информации, хотя сохраняются те же принципы ее использования. В отличие от бумажных, электронные документы не воссоздаются во множестве копий при каждом изменении отраженных в них обстоятельств, а изменяются в соответствии с изменениями этих обстоятельств. Сама возможность удаления данных из системы влечет немыслимые для бумажной документации возможности для злоупотреблений и махинаций. Особенно опасно удаление данных, если на их основании приняты властные решения, записи о которых хранятся в других системах. Когда много систем обмениваются данными, важно сохранить возможность сверки с некоторым эталонным источником. В серьезных разработках такая возможность всегда предусмотрена. Но это и означает, что идея уничтожения данных, использующихся в системах учета, — всего лишь миф или иллюзия. Ведь данные можно считать уничтоженными не в случае невозможности их штатного восстановления в той или иной информационной системе, а лишь при одновременном уничтожении всех копий этих данных во всех других информационных системах, включая резервные. В то же время уничтожение всех резервных копий практически означает полное обнуление информации обо всех зарегистрированных правах граждан, включая права собственности. Получается, что на практике ни о каком уничтожении данных не может быть и речи — данные, единожды попавшие в такую систему, будут храниться в ней до полного уничтожения самой системы, в том числе материальных носителей информации, а также всех резервных и иных копий (включая копии, использующиеся в других системах). А в случае интеграции разнородных систем учета в единую систему об уничтожении данных можно говорить только при уничтожении самой информационной среды. Это обстоятельство — неизбежный и один из самых опасных факторов внедрения управленческих систем, основанных на базах персональных данных. Надо добавить, что утрата контроля над возможностью копирования информации на любом носителе приводит к бессмысленности любых гарантий уничтожения данных — достаточно создать единственную неконтролируемую копию, ограничение тиражирования которой находится за пределами возможностей государства. А вероятность утраты контроля, сколь бы малой она ни была, со временем лишь растет. Рано или поздно утечка информации неизбежна, а значит, единственным приемлемым способом оценки такого риска было бы использование принципов оценки вероятности, используемых даже не в страховом, а в игорном бизнесе. Как известно, наибольшая надежность в этом смысле достигается при игре в рулетку, когда вероятность события не изменяется со временем пребывания игрока за игорным столом, то есть когда каждый раз игра начинается заново, независимо от предыдущих результатов (см. статью «Фортуна в колесе» К. Ветлугина, «КТ» #30-31 от 10.08.1998, и «Красное и черное» В. Гуриева, «КТ» #27-28 от 26.07.2005). Применив этот принцип к задаче сохранения вероятности утечки, утраты или искажения данных на приемлемо низком уровне, получим несколько неожиданный вывод: нужно с некоторой периодичностью полностью уничтожать систему и создавать ее заново. При этом решается и проблема непрерывного накопления ошибок. Отметим, что именно этот подход применяется в условиях бумажного документооборота, когда для принятия властных решений каждый раз заново собираются документы. В электронных же системах, напротив, происходит непрерывная актуализация и изменение уже имеющихся данных. В бумажных системах нет нужды уничтожать архивы — архивы играют в управлении пассивную роль и актуализируются только по мере необходимости. Бумажные архивы используются для напоминания отдельных фактов, сведения о которых сохранены в неизменном виде. Архивы сплошь и рядом противоречат друг другу (да простят меня архивариусы — это не их вина, а свойство самих архивов), сведения в них собираются с большими интервалами и фрагментарны. Поэтому бумажные архивы не годятся для принятия решений в автоматизированном режиме. Зато при когнитивной обработке этих фрагментов чиновниками, с учетом здравого смысла и реального состояния правоотношений, вполне можно составить картину, достаточную для принятия решения. Осознанно или неосознанно промежуточные факты, не отраженные в архивах, дополняются воображением чиновника и очень часто приблизительны. Например, если в паспорте есть штамп о браке, то только в самых ответственных случаях чиновник будет требовать свидетельство о браке, хотя юридическим подтверждением факта бракосочетания штамп в паспорте не является. Казалось бы, при таком подходе неизбежны ошибки и недоразумения, однако на практике, наоборот, ошибочных и нарушающих закон (права граждан) решений становится больше по мере роста объема используемых документов. Иными словами, чем длиннее список используемых документов, тем выше риск нарушения прав граждан. Другая сторона той же медали такова: чем больше используется документов, тем меньше ответственность чиновника. Не случайно наивысшую силу имеет судебное решение, где вообще нет никаких установленных списков документов, которые гражданин должен представлять в подтверждение своих доводов; причем никакие доказательства не имеют для суда заранее установленной силы (ст. 67 ГПК РФ и ст. 17 УПК РФ). Зато и ответственность судьи выше. При автоматизированной обработке любое противоречие в архивах может привести к фатальной ошибке. При этом архивы не актуализируются по мере необходимости, а актуальны всегда. Количество документов, используемых при принятии решения, резко возрастает. В случае объединения или взаимной интеграции архивов непротиворечивость этих документов и универсальность возможности их использования приобретает принципиальное значение (см. мою статью «Этот непостижимый административный учет», «КТ» #612 от 1.11.2005). Вместе с тем уменьшается роль когнитивной оценки документов одновременно с уменьшением ответственности чиновника, и растет риск нарушения прав граждан. Это в равной степени касается и информации, не используемой в управленческих целях. Разница лишь в том, что ее уничтожение или случайная утрата не повлечет нарушения ничьих прав. Напротив, угрозой становится сохранность информации, усугубленная ее непрерывной доступностью. Публикация в Сети высказанного человеком сгоряча мнения мозолит глаза в поисковиках как вечный памятник его неуравновешенности. Любая вовремя не уничтоженная мелочь может остаться в электронных сетях до скончания века — и будет легкодоступной неограниченному кругу лиц. Меня не волнует бумажное издание, содержащее неверные сведения о моей персоне, — оно не так доступно. Иное дело, если потенциальный работодатель или партнер полезет в Сеть выяснять, кто я да что я. Публикацию в бумажных изданиях он не найдет, а вот пустая склока, опубликованная в Интернете, может вызвать у него интерес. Одними из фундаментальных правовых основ являются понятия срока давности в уголовном праве (ст. 78 УК РФ) и срока приобретательской давности и исковой давности в гражданском праве (ст. 195, 231, 234 ГК РФ). Время лечит — это основа существования человеческого общества, вытекающая из самого способа мышления человека и гарантия непрерывной стабилизации отношений, непрерывного автоматического разрешения давних споров, обид и недоразумений. Гарантия ненакопления управленческих ошибок и неразрешимых конфликтов. В статье «Борьба с коррупцией или электронная гильотина как средство от перхоти» («КТ» #616 от 29.11.2005) я говорил о влиянии прозрачности на системы управления. Но прозрачность, усугубленная неуничтожимостью и непрерывной актуализацией информации, способна привести к коллапсу не только управленческих систем, но и общественных институтов саморегулирования. Надо понимать, как ненадежен расчет на некое общественное досье, где «все про всех всё знают», поскольку в этих условиях любое нарушение обязательств влечет пожизненное наказание. Общество, не способное прощать, не может существовать долго. Наиболее разрушительную и вместе с тем прогрессивную часть любого общества составляют люди авантюрного склада. Те, кто допускает наибольшее количество ошибок, склонен необдуманно брать на себя невыполнимые обязательства и способен, преодолевая угрызения совести, свои обязательства нарушать. Именно эти люди готовят и совершают революции, именно они оказываются нарушителями даже самых либеральных законов и в то же время именно они открывают Америки и нащупывают пути, по которым в дальнейшем движется весь мир. Если не предложить авантюристам прощение грехов, они наверняка найдут способ разнести в клочья любое общество и любой способ управления. Надеюсь, у меня будет время и возможность подробнее раскрыть существо проблем, заложенных в основу проекта закона о «Персональных данных». Здесь же просто кратко перечислю важнейшие из них. Сбор данных Законопроект не предусматривает практически никакого контроля за сбором персональных данных, оговаривая лишь ограничения в части обработки уже собранных сведений о гражданах. Персональные данные и сведения о частной жизни Из Европейской Конвенции «О защите частных лиц при автоматизированной обработке персональных данных» следует, что «персональные данные» означают любую информацию об определенном или поддающемся определению физическом лице (субъект данных). Уже в преамбуле содержится неоднозначное утверждение о том, что Конвенция подписана сторонами в целях уважения и защиты частной жизни, а в ст. 1 прямо говорится, что защита сведений о частной жизни граждан является основной целью Конвенции. Если исходить из ст. 23, 24 Конституции России, сведения о частной жизни могут быть собраны и обработаны только с согласия гражданина или по решению суда. Итого: единственный способ соблюсти и Конвенцию, и Конституцию — не подвергать персональные данные автоматизированной обработке. Уполномоченный орган по защите персональных данных Конвенция предусматривает создание специального независимого органа по защите персональных данных. Законопроект предполагает, что такой орган будет назначаться Правительством, и он же будет сертифицировать автоматизированные системы обработки персональных данных. Идентификаторы персональных данных Законопроект предполагает обязательное присвоение персональным данным граждан уникальных, несменяемых номеров. Причем законопроект не содержит никакой возможности уклониться от присвоения этого номера. Надо ли говорить, что это ущемляет одно из фундаментальных прав граждан — право иметь убеждения и действовать в соответствии с ними. Именно это право положено в основу закона «Об альтернативной службе», а также в основу норм уголовно-процессуального кодекса, гарантирующих право не давать показания против своих близких. Иными словами, даже если закон обязывает что-либо делать (например, служить в армии), человек вправе поступать согласно своим убеждениям, если это не нарушает конституционных прав других людей. В данном же случае отказ от присвоения уникального номера реализовать в рамках закона невозможно. Государственные и негосударственные системы Законопроект не делает никаких различий между электронными системами, использующими персональные данные граждан и применяющимися в органах государственной власти и негосударственных структурах. Биометрические данные Предполагается распространить действие этого закона и на системы сбора, хранения, обработки и использования биометрических данных, что вызывает особые опасения, поскольку создание баз биометрических и генетических данных граждан требует предельной осторожности и широкого обсуждения. В законопроекте же об этом говорится лишь вскользь, но этого уже достаточно, чтобы начать создавать такие базы. Трансграничная передача данных Законопроект прямо устанавливает возможность трансграничной (то есть за пределы России) передачи персональных данных. Очевидно, что при любых действиях с персональными данными в пределах России мы имеем возможность требовать от органов государственной власти России принятия властных мер. Если же злоупотребления персональными данными будут происходить за пределами страны, действенных механизмов их пресечения у органов государственной власти России нет в силу суверенитета других государств. Интеграция баз персональных данных Еще один пласт проблем вытекает из устанавливаемой законопроектом возможности интеграции баз персональных данных и неподконтрольной гражданину возможности передачи его персональных данных из одной интегрированной системы в другую. Надо сказать, что в силу ст. 23, 24 Конституции России без согласия гражданина или решения суда сведения о частной жизни не могут быть собраны, использованы и переданы из одной системы в другую. Остается подчеркнуть, что вышеизложенные неопределенности и проблемы, которые создаются принятием этого закона, усугублены предусмотренной им возможностью уничтожения персональных данных. 15 января на круглом столе в партии «Яблоко» было принято обращение к парламенту с требованием провести всенародное обсуждение законопроекта. Одновременно было выпущено обращение ко всем заинтересованным лицам с просьбой принять участие в разработке единого консолидированного Доклада по проекту закона (privacy.hro.org/persdata/15-01-06.php). Следующий круглый стол по этому вопросу решено провести в партии КПРФ, и далее по очереди в других политических и общественных организациях. Обсуждение доклада за неимением другого ресурса ведется в моем блоге david-gor.livejournal.com. Софтерра: Обыск местного значения Автор: Макс Магляс Говорить о том, что в наше время информационных технологий и бесконечного роста объема данных существует много проблем с обработкой и поиском информации, — это уже кощунство. Дабы не загружать вас субъективными и объективными суждениями, почерпнутыми из различных источников, перейду непосредственно к решению задачи. Апгрейд «прямого поиска» Когда информации в локальных сетях было немного, любой поиск осуществлялся банальным перебором горстки доступных файлов и последовательной проверкой их названий и содержимого. Такой поиск называется прямым, и программы, его использующие, традиционно включаются во все ОС и инструментальные пакеты. Но даже мощности современных компьютеров не хватит для быстрого прямого поиска в гигантских объемах данных. Перебор пары сотен документов на диске и поиск в громадной библиотеке и нескольких десятках почтовых ящиков — разные вещи. Поэтому программы прямого поиска сегодня уходят на второй план, если речь идет об универсальных средствах. В корпоративном секторе такой вид поиска уже не применяется — объемы не те. Не так давно Билл Гейтс, позавидовав, судя по всему, феноменальному успеху Google, огласил желание софтверного (уже и не только) гиганта всячески способствовать развитию поисковых систем и технологий. Но до создания какой-либо феноменальной программы от Microsoft или конкурентоспособного сервиса в Интернете пока далеко. Индекс, запрос, релевантность В основе современных технологий поиска лежат два процесса: индексация доступной информации и обработка запроса с последующим выводом результатов. Что касается первого, то любая программа (хоть настольный поисковик, хоть корпоративная информационная система или интернет-поисковый движок) создает свою область поиска. То есть обрабатывает документы и формирует их индекс (организованную структуру, в которой содержится информация об обработанных данных). Затем программа обрабатывает запрос (по ключевому слову-фразе) и выводит список документов, в которых эта ключевая фраза встречается. Так как информация содержится в структурированном индексе, то обработка запроса проходит в десятки и сотни раз быстрее, чем в случае с прямым поиском (выборка документов осуществляется не перебором файлов, а анализом текстовой информации в индексе). Найденные документы программа выводит в результирующем списке согласно релевантности — соответствию документа тексту запроса. В разных технологиях используются разные методы поиска и определения релевантности (количество «вхождений» слова, частота упоминания, отношение этих параметров к общему количеству слов в документе, расстояние между словами фразы запроса в искомых файлах и т. д.). На основе этих параметров определяется «вес» документа, и в зависимости от него тот или иной файл оказывается в списке результатов на определенной позиции. В случае с интернет-поиском дело обстоит еще сложнее. Ведь в данном случае надо учитывать и множество иных факторов (Page Rank Google тому пример). Но это тема для отдельной статьи, так что Интернет трогать не будем. На подопытный компьютер (Athlon 2,2 МГц; 1 Гбайт RAM, IDE-винчестер Seagate, 160 Гбайт, 7200 об./мин.; Windows XP) был установлен набор программ: dtSearch Desktop, «Ищейка Проф Deluxe», Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. Для тестов была скомпонована текстовая база документов в форматах doc, txt и html общим объемом 20 Гбайт. Группа товарищей под руководством вашего покорного слуги тестировала, сравнивала и делилась своими субъективными впечатлениями по каждой софтине. dtSearch Desktop 7.0 Разработчик: dtSearch Corp. Официальный сайт: www.dtsearch.com Цена: $199 Размер дистрибутива: 23,1 Мбайт Интерфейс dtSearch довольно прост, но некоторые окна или вкладки перегружены элементами, из-за чего создается впечатление сложности использования. Единственным действительно неприятным моментом является отсутствие русскоязычного интерфейса, хотя искать документы программа может на нескольких языках. Зато dtSearch одна из немногих утилит, которая может индексировать веб-страницы на заданную пользователем «глубину» (для этого, правда, нужно докупить адд-он dtSearch Spider). 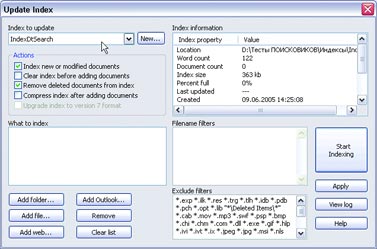 Имеется морфологический поиск (слово во всех морфологических формах), поиск с коррекцией ошибок (с опечатками) и поиск с использованием синонимов. dtSearch может производить поиск с использованием фраз, состоящих из слов, соединенных логическими операциями. Каждому слову в запросе можно устанавливать свой вес.  В общем и целом неплохая программа из разряда профессиональных поисковиков. Накладок с русским текстом при поиске не было. Как не было их ни с заявленной морфологией, ни с нечетким поиском. Система вполне адекватно находила нужные документы и по простому запросу в одно слово, и при использовании в качестве ключевой фразы пары абзацев документа.  iSYS Desktop 7.0 Разработчик: iSYS Search Официальный сайт: www.isys-search.com Цена: $570 Размер дистрибутива: 38,8 Мбайт Очень мощная программа, но размер установочного файла больше 40 Мбайт! Интерфейс весьма симпатичный, но разобраться, где и что находится, куда нажимать и где наконец-то осуществить поиск, новичку будет непросто: запросы для поиска вводятся при помощи запуска одной программы, а управление индексами производится при помощи другой. Поисковые запросы вводятся также в отдельных появляющихся окошках. Ко всему прочему не поддерживается русский язык. 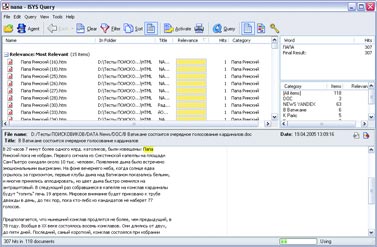 Возможности по созданию индексов включают в себя несколько готовых шаблонов (по папке «Мои документы», «Почта», «Почта и документы», «Определенная папка», «Папка с выбором типов файлов» и др.). ISYS Desktop умеет индексировать информацию из различных источников данных и предоставляет для этого множество настроек. Дополнительные возможности: поддержка SQL, FTP, TRIM Context, WORLDOX 2002, скрипты, планировщик индексации. Из продвинутых функций программа предлагает использование синонимов, фильтра сортировки (по пути, имени и дате создания файла). Удивило то, что отсутствует поиск с использованием морфологии. Кроме того, нет списка значимых слов, зато имеется обширный список слов незначимых. Также заявлены функции «приблизительный поиск» и «эвристический анализ». Результаты поиска весьма информативны, отображаются в виде списка документов, отсортированных по релевантности. К сожалению, предпросмотр документа доступен лишь в виде обычного текста, добиться отображения файлов в родном формате, будь то Word, Html или PDF, так и не удалось. Программа позволяет разбивать найденные документы на группы по определенным признакам (по умолчанию они разделены по релевантности). Google Desktop Search + GDE Enterprise Разработчик: Google Официальный сайт: www.google.com Цена: бесплатно Размер дистрибутива вместе с TweakGDS: 1,2 Мбайт Имя Google уже говорит о многом. Бесплатная разработка предназначена для поиска информации на персональном компьютере, в Интернете и корпоративной сети. С одной лишь оговоркой: компания Google предлагает свои услуги по консультации и развертыванию системы GDS Enterprise на предприятии за 10 тысяч долларов на каждую тысячу пользователей.  Первое, что бросается в глаза, — отсутствие собственной оболочки для программы. Google Desktop Search по-прежнему находится в окне браузера, соответственно весь интерфейс настольной версии достался софтине от старшего интернет-брата. После инсталляции Google Desktop Search начинает индексировать на компьютере все подряд — выбрать пути индексации невозможно. Придется скачать отдельную программку (TweakGDS), которая позволит расширить настройки Google Desktop, в том числе указать предназначенные для индексации диски и папки. Кроме того, для работы с сетью программе необходимы Microsoft .NET Framework и Microsoft Scripting Runtime. Что касается анализа поисковых запросов и выдачи результатов, то здесь все идентично интернет-поисковику Google: та же система отображения, тот же стандартный набор логических операций для запросов. Google Desktop Search предназначен исключительно для поиска файлов — внутреннего просмотрщика этих файлов в нем нет. Количества поддерживаемых форматов вполне достаточно, поиск осуществляется также по посещенным веб-страницам (данные из кэша).  К сожалению, похвастаться поддержкой русской морфологии, как и прочими интересными функциями поиска, данная софтина не может.Большое преимущество (или упущение?) заключается в настройке программы путем установки плагинов (даже для полноценной работы с архивами нужна отдельная примочка). Правда, все эти дополнения бесплатны. Однако если не брать в расчет десктопную версию поисковика, то грамотная настройка GDS Enterprise может оказаться вам не под силу — ведь не зря Google предлагает свои услуги. Если же вы все-таки осилите процедуру настройки и установки (или заплатите бригаде быстрого реагирования Google), то поймете, что сложность установки с лихвой компенсируется гибкими настройками при использовании в корпоративных сетях. Немаловажным моментом является использование групповых политик, что дает возможность установить настройки для каждого пользователя. Copernic Desktop Search Разработчик: Copernic Официальный сайт: www.copernic.com Цена: бесплатно Размер дистрибутива: 2,56 Мбайт В интерфейсе программы нет ничего лишнего, с ней разберется даже неискушенный пользователь. При первом запуске программа предлагает создать индексы. Необычным показалось то, что после выбора папок для индексирования Copernic не предлагает нажать какую-нибудь кнопку вроде «Начать индексацию», при этом индексация не начинается автоматически — утилита ждет простоя компьютера. Придется покопаться в опциях, чтобы настроить все должным образом. Отметим широкие возможности настройки автоматического создания индекса: встроенный планировщик, возможность индексации в фоновом режиме с низким приоритетом и т. д. 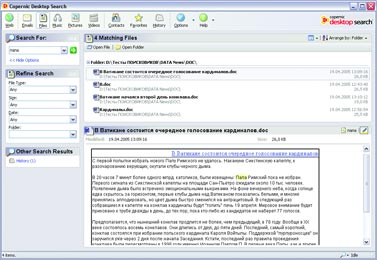 Изначально Copernic предлагает упрощенный вариант создания индекса: на выбор «Документы», «Изображения», «Видео», «Музыка». Можно выбрать типы файлов по расширению, запретить индексирование, например, картинок менее 16х16 пикселов или звуковых файлов короче 10 секунд. Copernic умеет работать с электронными письмами и контактами из адресной книги Microsoft Outlook (Outlook Express), возможна индексация «Избранного» и «Истории» из Internet Explorer. 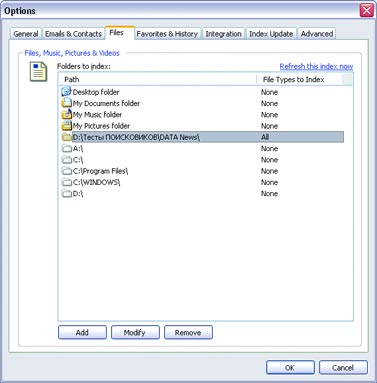 Тесты показали, что программа не ищет документы форматов txt и html на русском языке и позволяет найти их только по заголовкам, а не по содержанию. Единственное, что Copernic предоставляет для повышения эффективности поиска, — это стандартный набор логических операций. Несмотря на слабый анализ запросов, программа предоставляет интересную систему — пользователь может выбрать тип файлов (изображения, видео, музыка и т. п.), ввести поисковый запрос и выбрать атрибуты, присущие именно выбранному типу файлов. После поиска по определенному типу файлов выдается весьма информативный список в окне результатов, причем если под ваш запрос попали файлы других типов, вы сможете открыть и их, нажав на определенную ссылку.  Под списком найденных файлов отображается их содержимое, есть возможность просмотра мультимедийных файлов. Copernic прекрасно видит и индексирует «присоединенные» сетевые диски. Но на этом все и заканчивается. Хороший образец простого и удобного «домашнего» поисковика. SearchInform Desktop Professional 1.8 Разработчик: «СофтИнформ» Официальный сайт: www.searchinform.com/site/ru Цена: $199,95 (3000 рублей для граждан РФ) Размер дистрибутива: 15 Мбайт Интерфейс программы выполнен с соблюдением всех общепринятых правил. На первый взгляд он несколько громоздок, но при внимательном рассмотрении оказывается, что вместить весь предоставляемый SearchInform функционал, например, в окно браузера (как Google) нет никакой возможности. 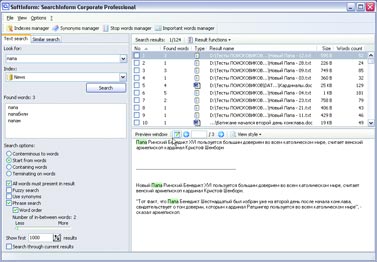 Поддерживается индексация электронных писем, подключение и индексация баз данных (!) и других внешних источников (DMS, CRM). При создании индекса можно дополнительно подключить встроенный словарь русской морфологии (или английского стэмминга) и поддержку атрибутов файлов. 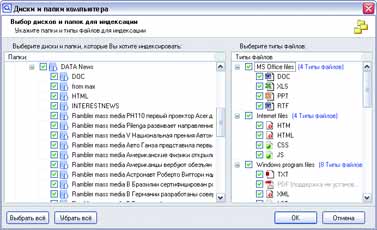 Перечисление возможностей программы начнем с фразового поиска: морфологический поиск, цитатный поиск, логические операции, поиск с синтаксическим разбором слова (поиск по началу слова, окончанию, средней части либо полное совпадение), смешанный цитатный поиск (все слова из запроса должны присутствовать в документе, но не обязательно во введенном порядке), поиск с коррекцией ошибок, использование синонимов и т. п. Кроме того, можно использовать словарь незначимых слов (в программе уже есть их список) и словарь приоритетных слов. Изюминкой программы является поиск документов, похожих по смысловому содержанию на текст запроса (они упорядочиваются «по проценту похожести»). В отличие от стандартного фразового поиска здесь удается избежать предварительного подбора ключевых слов.  Корпоративная версия SearchInform Corporate состоит из двух приложений: серверного и пользовательского. Первая самостоятельно обрабатывает указанные индексы, а пользователи могут использовать их для поиска в зависимости от прав доступа. Пользователи могут быть настроены автоматически, с помощью учетных записей Windows (NTFS-аутентификация Windows) или вручную (придется добавлять по отдельности). Каждому пользователю можно разрешить или запретить доступ к определенным индексам, можно также объединять пользователей в группы. «Ищейка Проф Deluxe» Разработчик: Isleuthhound Technologies Официальный сайт:www.isleuthhound.com/ru Цена: $29 Размер дистрибутива: 6 Mбайт Из названия ясно, что поддержка русского языка в программе есть. Интерфейс необычен, но весьма привлекателен. И все же многооконное решение — не самый удачный вариант (например, запрос вводится в одном окне, результат отображается в другом).  Индексирование проходит гораздо медленнее, нежели у других программ. Скорее всего, дело тут в неоптимизированных алгоритмах. Окно результатов не слишком информативно: прочитать весь найденный файл можно только открыв его — встроенного просмотрщика нет. Зато выдается выдержка из файла, где встретилось искомое слово.  Такого понятия, как «искать текст», нет; максимум, что можно искать, — это фразу. «Ищейка» предлагает стандартный набор: логические операции, поиск по маске и цитатный поиск. Присутствуют зачатки морфологического поиска, но настолько сырого, что он скорее мешает корректной работе (во время тестов было множество накладок с неправильным использованием морфологии).  Зато программа позволяет указывать атрибуты файлов (дата создания документа, имя файла, имя папки). Можно искать письма, указывая параметры (От, Тема и пр.), а также обновлять индексы по расписанию. 1, 2, 3, 4, 5, 6, 7, 8, 9 |
|||||||||